avatar movie graphics in VR.
Will they have 4K VR lenses by then, for each eye?
Follow along with the video below to see how to install our site as a web app on your home screen.
Note: This feature may not be available in some browsers.
avatar movie graphics in VR.
Will they have 4K VR lenses by then, for each eye?
im thinking 80tflops is a possibility for nexgen consoles?
WRT mid-gen vs not I think Sony would rather have the PS6 being the next step up with updated everything and hopefully something PCs won't match for a few years in some specific area regarding exclusives. Whether or not that comes to pass depends on sales in 3 or 4 years which know one knows anything about.Yes, and I would say, that IF we do go down the route of mid-gen consoles again, in 2023/2024, the main draw for them would be greatly increased ray tracing performance over the base consoles, with Zen 4 or Zen 5 CPUs and RDNA 4 GPUs
It would not be for pushing 8K.
It would also allow Sony to do 60fps versions of all their big games, with ray tracing at 4K.
That said, I'd still prefer there to be no mid-gen consoles and we go straight to PS6 and Future Xbox in late 2026. All the software ecosystems and your services/games will just roll right onto the new hardware easier than ever.
Tensor cores can not run parallel with shader cores.I don't believe so. Unless some new manufacturing technique develops that can significantly reduce power consumption. To get that TF number, I think we would need to be at a node that is beyond 3nm and it would likely have to be MCM based. The bandwidth requirements would like have to be on the order of multi-terabyte/sec as well. I don't see a feasible technology for that on the horizon yet. This is even way beyond what HBM is currently capable of.
I still think next gen will be 20-30 TFlops plus a boat load of dedicated HW acceleration for raytracing and ML techniques (resolution up sampling, frame rate interpolation).
It seems the current gen will be severely lacking on the ML inference side. When you look at the peak tensor ops of Turing for the various flavors of INT8 and FP16 using the tensor cores, they are far beyond what the GPU cores can do and can be done in parallel with the GPU.
At least what has been disclosed so far from MS/Sony is that RDNA will simply allow for FP16 and INT8 ops to run on the GPU cores. Which is ok, but already behind what the state of the art is.
Tensor cores can not run parallel with shader cores.
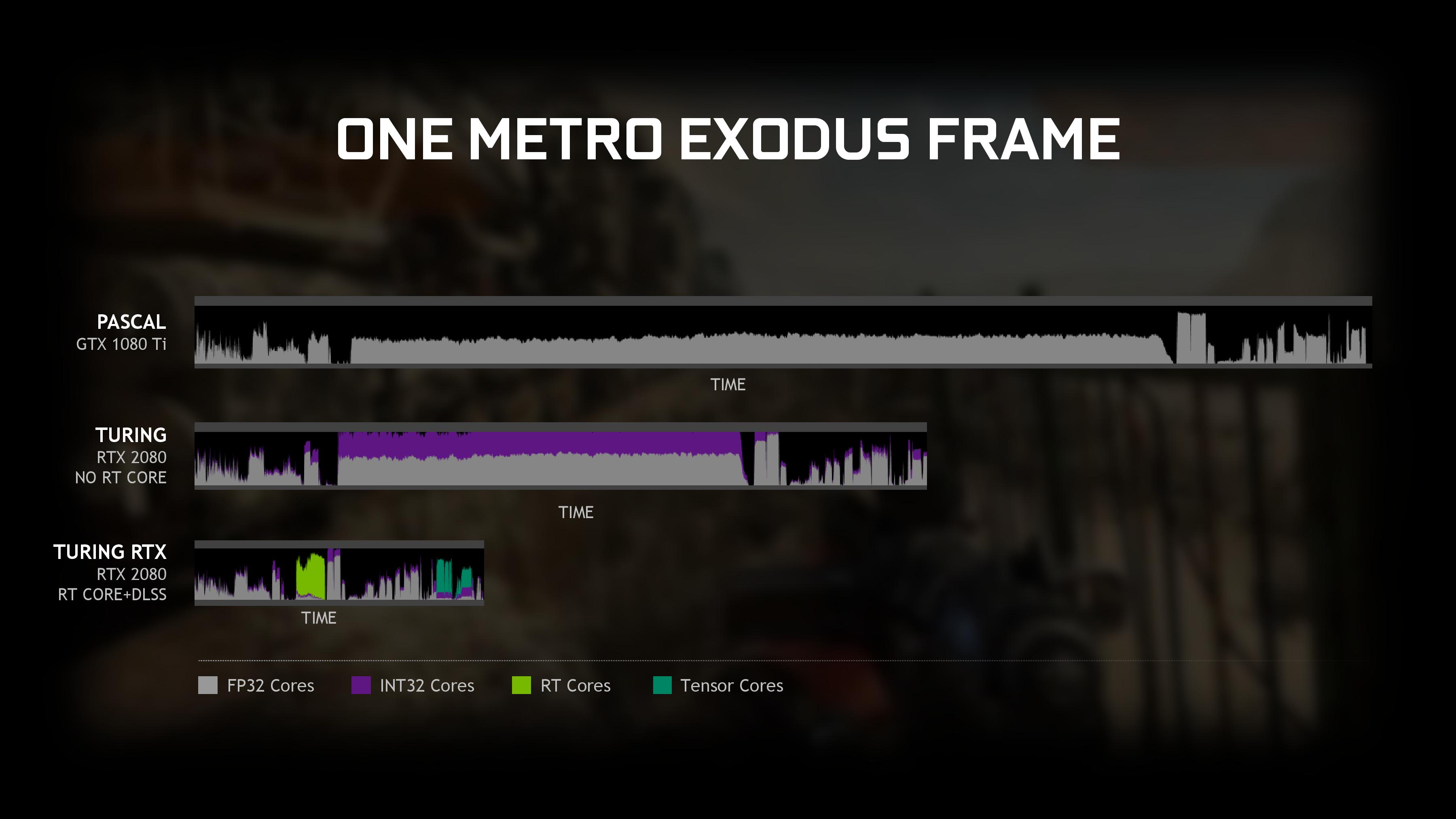
Everything I've read in the architecture threads here has stated tensor cores can not run concurrently with shader work due to lack of shared resources. Tensors saturate them all.interesting. I thought that was the case as I based the assumption off this slide.
Maybe this just means most of the shaders are doing tensor work and only some are doing the FP32 work.
Fully ray traced games with no exceptions. Major improvements in animation and ai.

I'm not sure how we get around this. This is an issue for all computing here. Trying to continually do more work with less power is very difficult to engineer. The amount of processing power that is occurring in such a small die is really ramping up the watts/cm^2 and therefore the TDP. We're getting to the point that if you're up to 50-80 TF of power that's a lot of transistors in such a small space, the heat is going to keep going up and so will the power. There lies a point that no amount of cooling will be able to keep up with the amount of watts/cm^2. I'm not sure at what TF level that is at, but I suspect it's happening soon. There's no magic solution I see coming here except toI've been thinking about this some since Ampere was announced. And I'm a little more pessimistic now. While the perf of Ampere looks great, it comes at a cost of an increased TPD. This is mostly fine for PC, but I don't think NVIDIA can really push much farther with their next line. For consoles, the power budget will be a big, big problem.
The node scaling from 7-5 and 5-3 only offers 30% power savings with each jump. So just a very rough estimate would put something like a 3090 (375 GPU power according to NVIDIA) out of the realm of possibility for a console APU without significant architectural improvements. Console manufacturers might have to wait until a process node beyond 3nm just to be able to get the needed performance at a reasonable power budget.

I don't know what tech will be used for PS6 or the Nexbox but one thing is certain GTAV will be launching with them.
Yes. We have GTA:V. On PS3, XB360, PC, PS4, XB1, PS5 and XSX. With all the re-re-re-releases we should get PS6/XBNext releases too.We already have GTA:V.