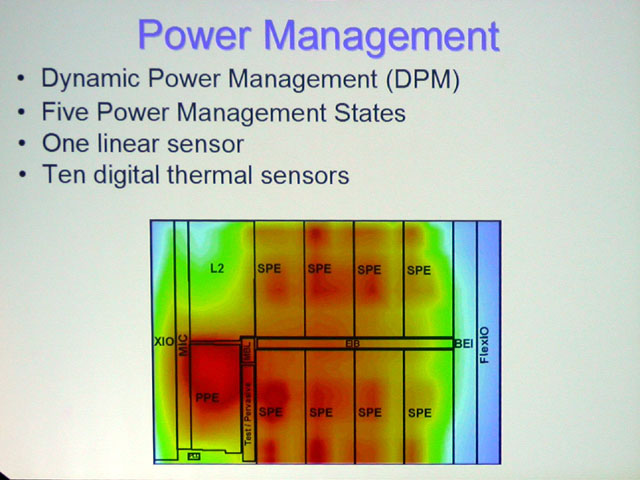
Could this not also mean a heavier workload for the PPE vs. the SPE's which would also imply a potential bottleneck?McFly said:On the cell thermal image, the PPE was the hottest part, so just doing the same on the xbox 360 cpu would make the chip extremly hot I guess.
Fredi
Install the app
How to install the app on iOS
Follow along with the video below to see how to install our site as a web app on your home screen.
Note: This feature may not be available in some browsers.
You are using an out of date browser. It may not display this or other websites correctly.
You should upgrade or use an alternative browser.
You should upgrade or use an alternative browser.
Second Gen Cell info
- Thread starter Mikage
- Start date
nelg said:Could this not also mean a heavier workload for the PPE vs. the SPE's which would also imply a potential bottleneck?McFly said:On the cell thermal image, the PPE was the hottest part, so just doing the same on the xbox 360 cpu would make the chip extremly hot I guess.
Fredi

Bear in mind that these were for CELL rev1 and not rev2...
EDIT:
The above numbers are for the SPE's though and not the PPE's...
I have not been following the cell processor to closely but I was under the impression (false?) that the power of he cell processor lies in the SPE’s. That a large part of the PPE’s job is to keep the SPE’s busy and heavily utilized. I know that we have no idea what kind of workload was being performed when the image was taken so we should not really read anything into it, except they should use the L2 cache as a thermal barrier between the PPE and SPE’sERP said:Could just mean that the SPE's weren't particularly busy when the thermal image was taken.
 .
.ERP said:Could just mean that the SPE's weren't particularly busy when the thermal image was taken.
Also: 50% of the SPEs is SRAM which burns very little power compared to logic.
Cheers
Gubbi
OTJaws said:EDIT:
The above numbers are for the SPE's though and not the PPE's...
I am curious as to how you can test just one part of a chip
Is it possible that both threads have a dedicated multiply-add unit,
but must contend with the other for int/permute/double precision fp?
Also, were there ever any details released on the PPE threading (old or new)?
- can it dispatch 2 instructions per thread per cycle, or a total of 2 per cycle?
- SoEMT or SMT, or round robin between threads on a cycle by cycle basis, or...
but must contend with the other for int/permute/double precision fp?
Also, were there ever any details released on the PPE threading (old or new)?
- can it dispatch 2 instructions per thread per cycle, or a total of 2 per cycle?
- SoEMT or SMT, or round robin between threads on a cycle by cycle basis, or...
psurge said:Is it possible that both threads have a dedicated multiply-add unit,
but must contend with the other for int/permute/double precision fp?
Also, were there ever any details released on the PPE threading (old or new)?
- can it dispatch 2 instructions per thread per cycle, or a total of 2 per cycle?
- SoEMT or SMT, or round robin between threads on a cycle by cycle basis, or...
It's in order -> no scheduling stage -> must be SoEMT.
Cheers
Gubbi
nelg said:OTJaws said:EDIT:
The above numbers are for the SPE's though and not the PPE's...
I am curious as to how you can test just one part of a chip
If you missed it earlier, Cell has many sensors built in. So I presume they get the result from them.
Don't see the logic - why couldn't you dispatch in order from multiple threads in the same cycle? You don't need scheduling, you just have to stall one thread if it needs a functional unit in use by the other thread...
edit : I suppose that is a form of scheduling, but its extremely primitive. Plus, you need logic like this for a 2 issue single threaded processor anyway... or am I missing something?
edit : I suppose that is a form of scheduling, but its extremely primitive. Plus, you need logic like this for a 2 issue single threaded processor anyway... or am I missing something?
Here's the relevent PPE snipet from the Realworldtech article, post-ISSCC.
...However, what is known is that the PPE processor core is a new core that is fully compliant with the POWERPC instruction set, the VMX instruction set extension inclusive. Additionally, the PPE core is described as a two issue, in-order, 64 bit processor that supports 2 way SMT. The L1 cache sizes of the PPE is reported to be 32KB each, and the unified L2 cache is 512 KB in size...
Tacitblue said:PC-Engine said:How many streams would a hyperthreading 3.5GHz dual core P4 be able to decode?
I think its a bit easy to see the kind of power that a streaming optimised processor like Cell has, when bottom line that's its strength, it was designed for that. a Pentium D with hyperthreading (isn't that the EE?) is not only prohibitably expensive (the processor all by itself costs more than a couple of PS3's expected cost) just has more burden from the bloatware it runs to keep us happy at work......or frustrated, depends on the time of day and what your deadlines are.
The chip is expensive because Intel's profit margins are very high, not because it cost $800 to fab. The cost primarily depends on the die size.
PC-Engine said:Tacitblue said:PC-Engine said:How many streams would a hyperthreading 3.5GHz dual core P4 be able to decode?
I think its a bit easy to see the kind of power that a streaming optimised processor like Cell has, when bottom line that's its strength, it was designed for that. a Pentium D with hyperthreading (isn't that the EE?) is not only prohibitably expensive (the processor all by itself costs more than a couple of PS3's expected cost) just has more burden from the bloatware it runs to keep us happy at work......or frustrated, depends on the time of day and what your deadlines are.
The chip is expensive because Intel's profit margins are very high, not because it cost $800 to fab. The cost primarily depends on the die size.
Right , last i heard the xeons only costed about 80$ to make . They then sell them at 1k or so and make alot of profit
If there's a second vmx unit, how does this affect the PPE flops per clock? It was 10 before, so now it is...?
I would have guessed 18, but accomodating two threads might not be the same as having two seperate full vmx units? Or are there two seperate full vmx units?
Thanks for any clarification..
I would have guessed 18, but accomodating two threads might not be the same as having two seperate full vmx units? Or are there two seperate full vmx units?
Thanks for any clarification..
Titanio said:If there's a second vmx unit, how does this affect the PPE flops per clock? It was 10 before, so now it is...?
I would have guessed 18, but accomodating two threads might not be the same as having two seperate full vmx units? Or are there two seperate full vmx units?
Thanks for any clarification..
It's still 2-way SMT, PPE ~ 16 flops per cycle across 2 VMX units doing 4-way FMADD
8 SPE's ~ 8*8 ~ 64 Flops per cycle
CELL rev2 ~ 80 flops per cycle ~ 320 GFlops @ 4 GHz.
Panajev2001a
Veteran
Gubbi said:psurge said:Is it possible that both threads have a dedicated multiply-add unit,
but must contend with the other for int/permute/double precision fp?
Also, were there ever any details released on the PPE threading (old or new)?
- can it dispatch 2 instructions per thread per cycle, or a total of 2 per cycle?
- SoEMT or SMT, or round robin between threads on a cycle by cycle basis, or...
It's in order -> no scheduling stage -> must be SoEMT.
Cheers
Gubbi
IBM has always stated SMT and not SoEMT
.Panajev2001a
Veteran
Jaws said:Panajev, what's your latest stance on two VMX units per PPE? Do you concur?
I do not concur: either you show me the extra Register-File or I will keep calling it wishful thinking.
Having a 32x128 bits register file shared by two VMX units would be not only wasteful silicon wise, but it would hardly bring the performance up.
Having two register-files for the VMX unit would ease MT impact on VMX-usage allowing to keep a separate context for each of the two HW threads using the VMX unit.
Panajev2001a said:Jaws said:Panajev, what's your latest stance on two VMX units per PPE? Do you concur?
I do not concur: either you show me the extra Register-File or I will keep calling it wishful thinking.
Having a 32x128 bits register file shared by two VMX units would be not only wasteful silicon wise, but it would hardly bring the performance up.
Having two register-files for the VMX unit would ease MT impact on VMX-usage allowing to keep a separate context for each of the two HW threads using the VMX unit.
Okay that makes sense...
rendezvous said:Jaws said:I see the following registers,
2*32.128 bit VMX
2*32.64 bit FP
2*32.64 bit INT
Do you agree?
Me too, given the size of those register blocks compared to the ones in the SPEs which we know are 128x128bit.
Do you agree on these registers?
The other question I have is that there are two 'identical' VMX blocks on the PPE, which weren't there before rev2?
See page 3-4 of this PDF for some PPE details.
The wording is confusing (fetch != issue) - at first glance this seems to imply the PPE is single issue.
Anyway, realworldtech has thread on this very same topic here Hopefully David Wang will write up his thoughts on the die photos...
The multithreading design supports fine-grained multithreading with round-robin thread scheduling. If both threads are active, the processor will fetch an instruction from each thread in turn. When one thread cannot issue a new instruction or is not active, the other active thread will be allowed to issue an instruction every cycle.
The wording is confusing (fetch != issue) - at first glance this seems to imply the PPE is single issue.
Anyway, realworldtech has thread on this very same topic here Hopefully David Wang will write up his thoughts on the die photos...
Similar threads
- Locked
- Replies
- 132
- Views
- 17K
- Replies
- 126
- Views
- 50K
- Replies
- 224
- Views
- 33K