Sorry yea I did my math wrong. You are right.I figure if you're going for two generations on with the microarchitecture, you probably wouldn't be too worried about the same bus. XSX gave no fucks about the X1 basic memory bus setup.
I think this is about a shrink and maybe a slight bump (think Xbox 1S) rather than a mid gen turbo machine!
How so?
320 x 14 / 8 = 560
256 x 18 / 8 = 576
What's your maths on this on? I think the 560 is a decimal figure, not binary. Same with Sony's 448.
320-bit was the only way to get 560 (decimal, not binary) GB/s.
Big Navi will be interesting for sure! In its favour, it doesn't have to share with a fast Zen CPU. I also think they might push for 16 gHz / Gbpp memory on some models, and enthusiasts will try and overclock too. Think it will still be memory bound quite a bit though.
The 72 CU salvage parts might be a really good balance though. Kinda like with Vega 56.
You are using an out of date browser. It may not display this or other websites correctly.
You should upgrade or use an alternative browser.
You should upgrade or use an alternative browser.
Xbox Series X [XBSX] [Release November 10 2020]
- Thread starter Megadrive1988
- Start date
-
- Tags
- microsoft xbox xbox series x xbsx
Sorry yea I did my math wrong. You are right.
Hey man, undeclared binary vs decimal has caught me out far too many times. Hard drive storage? OS vs Advert? Bandwidth? Memory allocation? It's a wild ride of contextual numbers!
I had to consult a calculator on this myself with multiple scenarios, and no mistake!
https://www.tomshardware.com/news/microsoft-xbox-series-x-architecture-deep-dive
Full hotchip presentation

EDIT: 7 nm is expensive
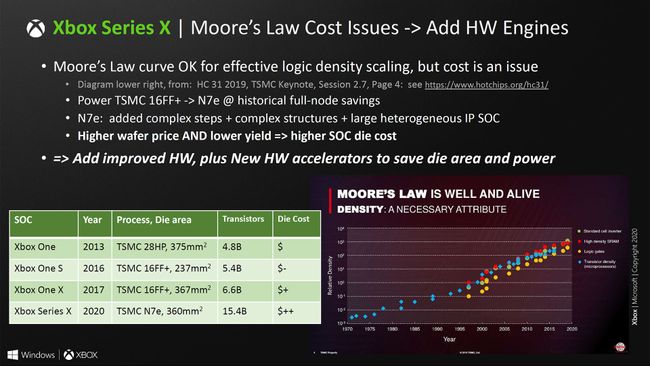

this look like expensive, APU, RAM, storage, double motherboard and cooling are probably more expensive than Xbox One X in 2017.

EDIT:

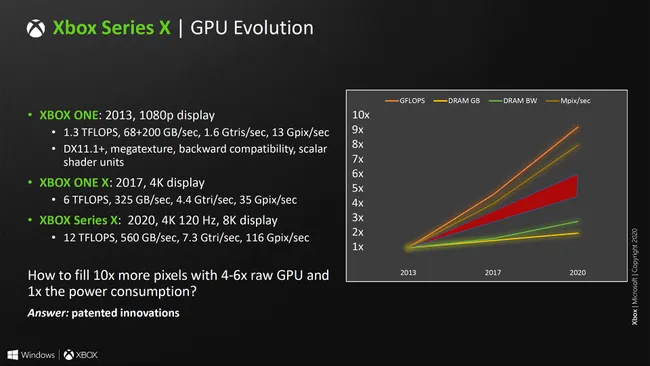
EDIT: Raytracing

Full hotchip presentation
EDIT: 7 nm is expensive
the die cost is higher. Microsoft doesn't specify how much higher, but lists "$" as the cost on the Xbox One and Xbox One S, "$+" for the Xbox One X, and "$++" for the Xbox Series X. As we've noted elsewhere, while TSMC's 7nm lithography is proving potent, the cost per wafer is substantially higher than at 12nm.
this look like expensive, APU, RAM, storage, double motherboard and cooling are probably more expensive than Xbox One X in 2017.
EDIT:
EDIT: Raytracing
Last edited:
Ike Turner
Veteran


Ike Turner
Veteran
NoThis. ML inference acceleration, resolution scaling 3-10x. Game changer?")
How compare them? Numbers please!They don't have enough when comparing to Nvidia RTX 2060/2070/2080 and DLSS 2 performance numbers.
What we do know for certain is they are using ML for is adding of HDR to some Original Xbox and X360 BC games.
How compare them? Numbers please!
Look at the specs of both and compare the TOPs rates for INT8. It's already been discussed on B3D.
EDIT: Start reading one conversation starting from 2020-03-23 https://forum.beyond3d.com/posts/2113698/
Also the more recent parts of the DLSS thread: https://forum.beyond3d.com/threads/...g-discussion-spawn.60896/page-21#post-2146200
Also some DLSS 2 details from Nvidia themselves: https://www.nvidia.com/en-us/geforce/news/nvidia-dlss-2-0-a-big-leap-in-ai-rendering/
Going entirely from memory, I think the Series X has half the inference performance numbers as a Nvidia 2070 (maybe 2060?).
not until we see the models.This. ML inference acceleration, resolution scaling 3-10x. Game changer?
hardware to support it is nice, how good and how well it runs is in the model development.
ML Inference may not necessarily be related to Int 4 and Int 8 TOPs, but it likely is. I'm just not sure how their 3-10x is calculated.
not sure how to compare RT performance either. Is there a standardized metric?
check this out:
10 Giga Rays/s for a 2080TI
but here we are reading 95G/s ray-tri peak?
If a ray/triangle intersection is a ray, then this is weird because I'm reading 10 vs 95.
This is unlikely. Needs investigation.
Thanks for sharing these slides all
Last edited:
cheapchips
Veteran
Curious as to why they say Zen2 Server Class cores. Do lower end Zen2s normally cut server features or are they just fluffing up their spec slide?

20 x 16 channels instead of 10 x 32 seems like good news. The way they list bandwidth first of the key factors for raytracing perhaps explains the 320-bit bus.
The low rate of dram cost reduction is depressing though. Definitely explains not populating all 10 slots with 2GB chips.
$++ sounds like an expensive node. Very 'Intel' naming too.
The low rate of dram cost reduction is depressing though. Definitely explains not populating all 10 slots with 2GB chips.
$++ sounds like an expensive node. Very 'Intel' naming too.
Thanx but there is still not enough information for direct comparison.Look at the specs of both and compare the TOPs rates for INT8. It's already been discussed on B3D.
EDIT: Start reading one conversation starting from 2020-03-23 https://forum.beyond3d.com/posts/2113698/
Also the more recent parts of the DLSS thread: https://forum.beyond3d.com/threads/...g-discussion-spawn.60896/page-21#post-2146200
Also some DLSS 2 details from Nvidia themselves: https://www.nvidia.com/en-us/geforce/news/nvidia-dlss-2-0-a-big-leap-in-ai-rendering/
Going entirely from memory, I think the Series X has half the inference performance numbers as a Nvidia 2070 (maybe 2060?).
Yes we need more information.not until we see the models.
hardware to support it is nice, how good and how well it runs is in the model development.
ML Inference may not necessarily be related to Int 4 and Int 8 TOPs, but it likely is. I'm just not sure how their 3-10x is calculated.
not sure how to compare RT performance either. Is there a standardized metric?
check this out:
10 Giga Rays/s for a 2080TI
but here we are reading 95G/s ray-tri peak?
If a ray/triangle intersection is a ray, then this is weird because I'm reading 10 vs 95.
This is unlikely. Needs investigation.
Thanks for sharing these slides all
Curious as to why they say Zen2 Server Class cores. Do lower end Zen2s normally cut server features or are they just fluffing up their spec slide?
View attachment 4476
4MB L3 per cluster is the same as the 4xxx mobile models, which is significantly less. Though everything L2 and up likely the same.
On the plus side, it will have significantly lower latency CCX to CCX communication which was rather high on the chiplet models.
Well I figured out Nvidia's and it's not the same.
So 6 gigarays is
6*10^9 rays, you still need the pixel number, because it's rays shot per pixel.
Or to put better
if you take 4K resolution and run it at 120Hz, it's
6 Giga rays / 4K@120fps
6*10^9 / 3840*2160*120
= 6 rays per pixel (for a 2080) and 10 rays per pixel(for a 2080TI)
This is not the same as ray-tri peak.
I'm not sure how to convert ray-tri peak to ray/pixel.
May not have to. We may just want to look at ray-tri. perhaps Nvidia's calculation is not hte best way to do it.
if you have 1 px triangles on the screen 95G/s is more desirable than 10Gigarays/s. We'd need to covert Gigarays to ray-tri -- or if it does just represent that, then w/e.
You have a situation where MS has somehow pulled peak throughput of basic ray-tri intersection tests to be 9.5x better than nvidia. I'm not sure if I believe that given that Minecraft ran worse.
Shaded and secondary rays is what is going to matter here.
So 6 gigarays is
6*10^9 rays, you still need the pixel number, because it's rays shot per pixel.
Or to put better
if you take 4K resolution and run it at 120Hz, it's
6 Giga rays / 4K@120fps
6*10^9 / 3840*2160*120
= 6 rays per pixel (for a 2080) and 10 rays per pixel(for a 2080TI)
This is not the same as ray-tri peak.
I'm not sure how to convert ray-tri peak to ray/pixel.
May not have to. We may just want to look at ray-tri. perhaps Nvidia's calculation is not hte best way to do it.
if you have 1 px triangles on the screen 95G/s is more desirable than 10Gigarays/s. We'd need to covert Gigarays to ray-tri -- or if it does just represent that, then w/e.
You have a situation where MS has somehow pulled peak throughput of basic ray-tri intersection tests to be 9.5x better than nvidia. I'm not sure if I believe that given that Minecraft ran worse.
Shaded and secondary rays is what is going to matter here.
Last edited:
4MB L3 per cluster is the same as the 4xxx mobile models, which is significantly less. Though everything L2 and up likely the same.
On the plus side, it will have significantly lower latency CCX to CCX communication which was rather high on the chiplet models.
AMD mobile 4xxx performs well, this is a good compromise.
DavidGraham
Veteran
It doesn't matter anymore, the solution in Series X is less powerful than Turing, it's now confirmed to share resources with the Texture units, so it's either 4 ray ops per clock or 4 texture ops per clock.Well I figured out Nvidia's and it's not the same.
So 6 gigarays is
6*10^9 rays, you still need the pixel number, because it's rays shot per pixel.
Or to put better
if you take 4K resolution and run it at 120Hz, it's
But RT performance, aside from intersection is based on shading power isn't it?It doesn't matter anymore, the solution in Series X is less powerful than Turing, it's now confirmed to share resources with the Texture units, so it's either 4 ray ops per clock or 4 texture ops per clock.
If we assume the intersection is quick, isn't' there still a lot of shading happening?
These are high peak theoretical for the most basic case (ie, no shading, all coherent, once you get into bouncing and incoherent rays) the numbers will come down from their peak.
RT performance is a factor of compute power (to run against the intersected triangle) and intersection. And coherence makes the whole process run so much faster because you can share the memory in a block for all the compute units to work on.
So when concerning bounce or reflections, that's when incoherent rays are painful to do with right?
It doesn't matter anymore, the solution in Series X is less powerful than Turing
I think a comparison with Ampere is more intresting, seeing that Turing is a 2018 product.
Similar threads
- Replies
- 97
- Views
- 10K
- Locked
- Replies
- 260
- Views
- 22K
- Replies
- 54
- Views
- 7K