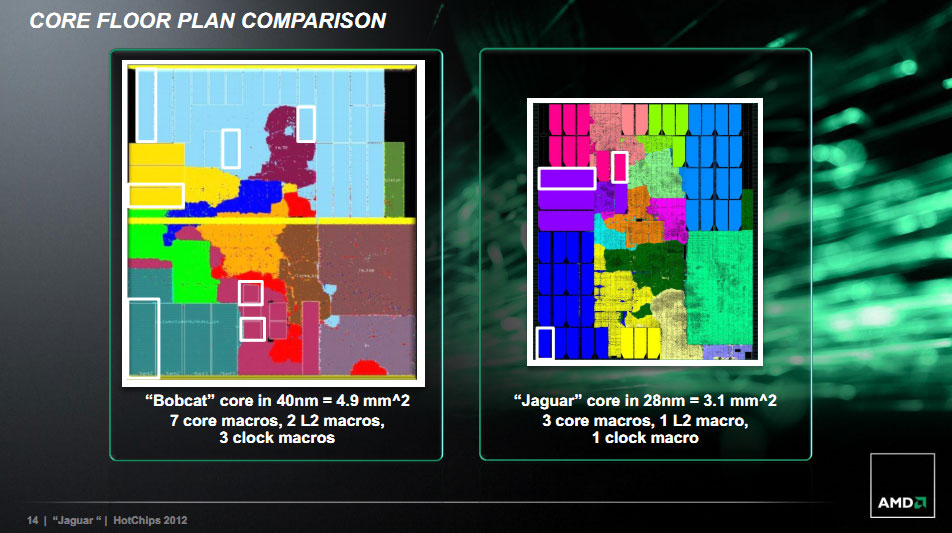
28nm is theoretically 50% smaller than 40nm yet Jaguar cores will, again, have a bit of enhancements and likely require more local memory so it is not likely to fit 4 cores into the same area as Bobcat cores, even with the die shrink.
If they have a fast memory architecture such as stacked DDR4 they wouldn't need as much cache as the memory would be physically closer and higher throughput which would mean they wouldn't need as much cache, right?
But even being generous and saying 2 Bobcat cores + cache, memory controller were half a die at 75mm^2 (so about 38mm^2 for 2 cores) it would seem 2 Jaguars could (conjecture) fit into that die area on 28nm and 4 Jaguar cores into 75mm^2. 150mm^2 would be a rough guestimate to the total area needed for 8 Jaguar cores.
Considering that there are parts of the die which aren't duplicated when you raise the core count, memory controllers/uncore etc perhaps the total die area would be less than that but with so much dense logic on the chip it could jive with rumours of poor yield for the same reason that the Cell came with one disabled SPE, logic is defect intolerant. Perhaps this is the reason for the rumoured 'Xbox TV' where the lesser SKU uses the parts which don't meet spec?
") Exlusives will be out of reach for budget reasons no matter how many fans we screw in pc case.
Exlusives will be out of reach for budget reasons no matter how many fans we screw in pc case.