You are using an out of date browser. It may not display this or other websites correctly.
You should upgrade or use an alternative browser.
You should upgrade or use an alternative browser.
DirectStorage GPU Decompression, RTX IO, Smart Access Storage
- Thread starter DavidGraham
- Start date
")
Flappy Pannus
Veteran
Hell yes, I'm ready to Get Deflated
DegustatoR
Legend
Accelerating Load Times for DirectX Games and Apps with GDeflate for DirectStorage | NVIDIA Technical Blog
Load times. They are the bane of any developer trying to construct a seamless experience. Trying to hide loading in a game by forcing a player to shimmy through narrow passages or take extremely slow…
 developer.nvidia.com
developer.nvidia.com
I'm looking forward to seeing how this plays out. I'm really hoping that the burden on the cpu is lowered by a significant amount. I'd rather spend my money on GPUs vs CPUs.
Looks like they included a benchmark.

 github.com
github.com
Looks like they included a benchmark.
DirectStorage/README.md at main · microsoft/DirectStorage
DirectStorage for Windows is an API that allows game developers to unlock the full potential of high speed NVMe drives for loading game assets. - DirectStorage/README.md at main · microsoft/DirectS...
github.com
Accelerating Load Times for DirectX Games and Apps with GDeflate for DirectStorage | NVIDIA Technical Blog
Load times. They are the bane of any developer trying to construct a seamless experience. Trying to hide loading in a game by forcing a player to shimmy through narrow passages or take extremely slow…
developer.nvidia.com
More info from Nvidia
Intel have updated their DS example code to include gpu decompression.
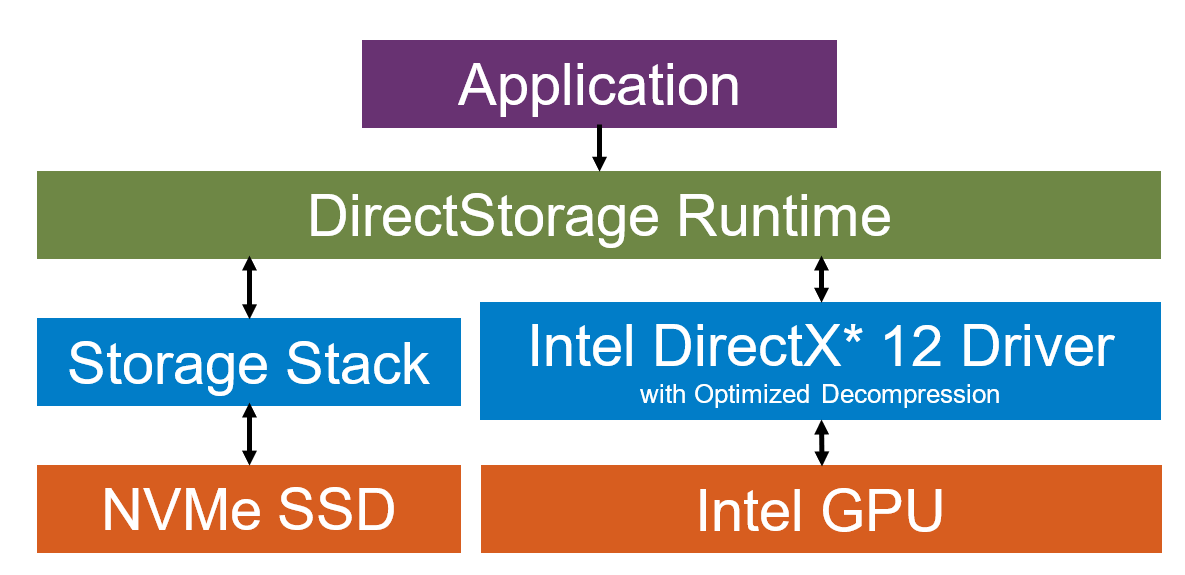

Awesome! And here I was planning to have an early night! Some observations:
- "Can be implemented cheaply in fixed-function hardware, using existing IP" - so hardware based decompression appears to be a design goal and thus a definite possibility moving forwards.
- RTX-IO lives! And it is, after all, just Nvidia's implementation of DirectStorage GPU decompression. Not even sure why it needed it's own name!
- Separate decompression of system memory destined data on the CPU (rather than GPU) (re)confirmed.
- If I'm reading it correctly, 256MB of VRAM (across input and output staging buffers) will generally be allocated as the staging buffer for the decompression. Although that can vary by GPU VRAM size.
- Intel has a really cool Sampler Feedback streaming (little s) demo showing how a scene featuring 100's of GB of source texture data can run on 100MB of VRAM using this tech.
- In line with the above, Intel sees this tech being used in future to treat the NVMe as a last level graphics cache (essentially VRAM), much like we heard described for Xbox Series X's velocity architecture at launch.
- Amazingly, in this fairly extreme demo, the GPU decompression has virtually no negative impact on frame rate. Although they do state that could change based on platform and software.
- Intel also shows a 2.7x speedup over a 12900k on an Arc A770 and that may simply be limited by the SSD speed rather than GPU capability.
Maybe I missed it but does all data still have to go through the CPU first?
It goes via system RAM. But there is basically no CPU impact of that.
There is a latency cost that has yet to alleviated compared to the implementation on consoles. I don’t know enough to know if this matters in practice though.It goes via system RAM. But there is basically no CPU impact of that.
AMD support for Microsoft DirectStorage 1.1
AMD is pleased to support Microsoft’s recently released DirectStorage 1.1 with GPU Decompression. DirectStorage must be enabled by developers to realize the benefits.
 gpuopen.com
gpuopen.com
There is a latency cost that has yet to alleviated compared to the implementation on consoles. I don’t know enough to know if this matters in practice though.
I wouldn't be so sure of that tbh. The hardware decompressor in the consoles will add it's own latency. And the latency of reading from an NVMe drive is going to be huge compared to the latency added by system memory copies which have much lower latency than NV memory of the SSD.
Certainly Intels SFS demo seems to be working pretty spectacularly so I doubt there's much reason to be concerned here.
The NVMe latency still applies to the PC as well it just has more stops before it can be decompressed.I wouldn't be so sure of that tbh. The hardware decompressor in the consoles will add it's own latency. And the latency of reading from an NVMe drive is going to be huge compared to the latency added by system memory copies which have much lower latency than NV memory of the SSD.
Certainly Intels SFS demo seems to be working pretty spectacularly so I doubt there's much reason to be concerned here.
The NVMe latency still applies to the PC as well it just has more stops before it can be decompressed.
Yes but the point is is that if system mem copies are 1/20th the latency of the initial NVMe read then the extra latency is basically irrelevant.
Vroom
Results from my 2080 Ti with a 10GB .tar archive. Not a bad showing considering it's not maxing out the GPU.
GPU GDEFLATE:
16 MiB staging buffer: .......... 4.57729 GB/s mean cycle time: 154632000
32 MiB staging buffer: .......... 7.46996 GB/s mean cycle time: 98937830
64 MiB staging buffer: .......... 11.8437 GB/s mean cycle time: 81842042
128 MiB staging buffer: .......... 13.7098 GB/s mean cycle time: 100085301
256 MiB staging buffer: .......... 13.3529 GB/s mean cycle time: 106768209
512 MiB staging buffer: .......... 11.7419 GB/s mean cycle time: 187876636
1024 MiB staging buffer: .......... 6.61114 GB/s mean cycle time: 22161204
Results from my 2080 Ti with a 10GB .tar archive. Not a bad showing considering it's not maxing out the GPU.
Ryzen 7700X and 3080ti. The 3080ti can load the scene faster using about 90% gpu. The 7700X loads the scene about 0.3-0.4s slower using 100% of the CPU. That bench looks like it's designed to be pretty heavy. Really curious about benchmarks that take a streaming approach vs a full scene loading benchmark.
tongue_of_colicab
Veteran
Maybe I'm reading your post wrong (didn't watch the video) but 100% cpu vs 90% gpu usage & less than a 0.5 sec difference in loading time sound to me like it basically makes no difference? Well, expect that a cpu costing half of what that gpu costs is barely any slower.
Maybe I'm reading your post wrong (didn't watch the video) but 100% cpu vs 90% gpu usage & less than a 0.5 sec difference in loading time sound to me like it basically makes no difference? Well, expect that a cpu costing half of what that gpu costs is barely any slower.
The test is done with a gen 3 SSD and the result is decompressing 8.1 GB/s on the GPU and 6.1 GB/s on the CPU. It's really just moving decompression off of the cpu so the cpu can do other things. There could be other differences here in terms of end to end latency, but not sure. One is SSD -> RAM -> VRAM -> decompress on gpu, and the other is SSD->RAM->decompress on CPU->VRAM. It's possible some people might have a strong cpu and a weak gpu, so I'm pretty sure the documentation recommends software gives the user the option to choose between CPU and GPU decompression. Overall, I think most people would rather spend their money on the GPU, so it makes sense to offload that way so some of your dollars can be diverted towards the gpu. Mid-range cpu with high-end gpu might make a better pairing in the future.
Similar threads
- Replies
- 2K
- Views
- 226K
- Replies
- 3
- Views
- 4K
- Replies
- 13
- Views
- 6K
- Replies
- 204
- Views
- 33K
- Replies
- 43
- Views
- 10K