Could the CPU not instruct the SSD DMA controller to send the required data direct to the GPU? Wouldn't that still allow all the security checks and file permissions to remain in place, but also allow the system memory to be bypassed?
Install the app
How to install the app on iOS
Follow along with the video below to see how to install our site as a web app on your home screen.
Note: This feature may not be available in some browsers.
You are using an out of date browser. It may not display this or other websites correctly.
You should upgrade or use an alternative browser.
You should upgrade or use an alternative browser.
DirectStorage GPU Decompression, RTX IO, Smart Access Storage
- Thread starter DavidGraham
- Start date
Realistically, this gains incredibly little. The heaviest CPU burden here (in terms of active compute cycles) is all the filesystem semantics about identity and access management, and then walking the filesystem descriptor (the journalled file system, or file table, or file bitmap, or whatever) to disover the relevant physical storage host controller(s) and, underneath, the mapped physical storage device blocks.Could the CPU not instruct the SSD DMA controller to send the required data direct to the GPU? Wouldn't that still allow all the security checks and file permissions to remain in place, but also allow the system memory to be bypassed?
Said another way: the inclusion of a filesystem in this I/O call makes the process CPU heavy.
One potential gain here would be bypassing the need for a second copy of the object in main system memory. While this immediately seems like a win (and it very well could be) you then get into some performance curiosities about leveraging heterogenous GPU systems as a novel way to "hardware accelerate" all the DXIO work away from the active rendering GPU. Mental picture for you: leverage a modern Intel iGPU or the AMD APU as the I/O offload accelerator in this picture; D3D12 already supports this asynchronous compute model today. Modern iGPU/APUs are simultaneously connected to the PCIe root complex and also main system memory. Bypassing main memory becomes an arbitrary and ultimately useless line in the sand for those folks who could use an embedded GPU (and thus, the main system memory pool) to do all the fancy GPU-accelerated decompression and storage management, to then hand it off to the dGPU doing all the raster work.
So yeah, could we get some gain in performance by skipping the main memory copy of the object? Certainly. Is that secondary memory copy actually costing CPU cycles? Sure, however it costs a miniscule quantity of CPU power when compared to the monster pile of CPU cycles needed to walk the filesystem abstraction layer.
Filesystems are the enemy here.
As I mentioned earlier, there are ways we could work around that bottleneck while keeping a filesystem. A contrived example could involve the software installer writing a singular binary blob (file) with all the assets bundled together. Once the write is complete, the app would then use a series of instructions to map out how the aforementioned asset file was physically written to the underlying storage (all the way down to discrete LBAs - or Logical Block Addresses), then create a bitmap of sorts serving as a rosetta stone for "this object/asset is stored on this storage controller, on this storage port connected to that controller, on this storage endpoint GUID attached to that storage port, starting at this LBA and extending to this LBA for the first 96KB, then skipping ahead to this LBA through this next LBA for the following 36KB, then skipping ahead again to this LBA through this other LBA for the next 124KB, and then...."
That bitmap rosetta stone would have to be built specifically on each machine during installation, and there would need to have a flag placed on that file to ensure it could never be "defragged" at any abstraction level, and if you ever migrated your disk (eg you upgrade from a 1TB gaming drive to a 4GB gaming drive) you'd have to let every app regenerate its bitmap because all the LBAs would change.
This method would permit a single filesystem call to get the master filehandle on the large asset blob, and then combined with an in-memory copy of that bitmap rosetta stone, the app could possibly issue direct I/O calls underneath to the millions of mapped blocks. This solution is a fragile, brittle, and rigid system that could be made to work but would also potentially suffer a LOT of strange pitfalls when it comes down to how a modern OS expects to be able to manage files separately from block I/O calls.
Also worth noting: in the direct storage I/O stack where the video card and the storage controller can work through a peer-to-peer transfer, there has to be a modification to both the video driver and storage driver stacks. Specifically, when each of those devices goes into PCIe Bus Master mode to do their jobs, the OS needs to know that the underlying hardware is carrying out commands that the OS may not have actually issued or even be aware of. So when the physical video card sends the PCIe TLP commands to the physical storage controller, the upstream OS storage driver needs to be aware of the physical device arbitration status so that other OS-handled I/O requests are properly queued and pipelined to stack in behind the current active bus transfer.
Edit: it later occured to me the singular binary blob of asset data will also require several other steps in how it's created at the filesystem level so that individual assets are written to disk in such a way they align at LBA boundaries. This means there's a pre-step of determining the physical LBA size of the destination storage device before creating the file, and then while creating the asset blob, each asset needs to be padded so that they all line up properly on LBA boundaries. Otherwise you end up with asset fragments that spill over into other LBAs and then you have to build a bunch of extra logic to prune nonsense off the blocks, which also means you're loading more data and burning more GPU cycles than you actually need to.
Example to help illustrate: if your underlying storage device is a modern 4kN drive, then you want your assets padded to the nearest 4 kilobyte boundary -- so a 9KB asset will necessarily consume 12KB on disk -- three 4Kb blocks, padded so that it perfectly fits into three physical blocks. If your underlying storage is actually a 512E or a 512N device, then your 9KB asset could ostensibly only consume 9KB on disk -- eighteen 512b blocks aligned to the underlying eighteen physical blocks.
Last edited:
Thanks for the detailed write-ups.Realistically, this gains incredibly little. The heaviest CPU burden here (in terms of active compute cycles) is all the filesystem semantics about identity and access management, and then walking the filesystem descriptor (the journalled file system, or file table, or file bitmap, or whatever) to disover the relevant physical storage host controller(s) and, underneath, the mapped physical storage device blocks.
Said another way: the inclusion of a filesystem in this I/O call makes the process CPU heavy.
One potential gain here would be bypassing the need for a second copy of the object in main system memory. While this immediately seems like a win (and it very well could be) you then get into some performance curiosities about leveraging heterogenous GPU systems as a novel way to "hardware accelerate" all the DXIO work away from the active rendering GPU. Mental picture for you: leverage a modern Intel iGPU or the AMD APU as the I/O offload accelerator in this picture; D3D12 already supports this asynchronous compute model today. Modern iGPU/APUs are simultaneously connected to the PCIe root complex and also main system memory. Bypassing main memory becomes an arbitrary and ultimately useless line in the sand for those folks who could use an embedded GPU (and thus, the main system memory pool) to do all the fancy GPU-accelerated decompression and storage management, to then hand it off to the dGPU doing all the raster work.
So yeah, could we get some gain in performance by skipping the main memory copy of the object? Certainly. Is that secondary memory copy actually costing CPU cycles? Sure, however it costs a miniscule quantity of CPU power when compared to the monster pile of CPU cycles needed to walk the filesystem abstraction layer.
Filesystems are the enemy here.
As I mentioned earlier, there are ways we could work around that bottleneck while keeping a filesystem. A contrived example could involve the software installer writing a singular binary blob (file) with all the assets bundled together. Once the write is complete, the app would then use a series of instructions to map out how the aforementioned asset file was physically written to the underlying storage (all the way down to discrete LBAs - or Logical Block Addresses), then create a bitmap of sorts serving as a rosetta stone for "this object/asset is stored on this storage controller, on this storage port connected to that controller, on this storage endpoint GUID attached to that storage port, starting at this LBA and extending to this LBA for the first 96KB, then skipping ahead to this LBA through this next LBA for the following 36KB, then skipping ahead again to this LBA through this other LBA for the next 124KB, and then...."
That bitmap rosetta stone would have to be built specifically on each machine during installation, and there would need to have a flag placed on that file to ensure it could never be "defragged" at any abstraction level, and if you ever migrated your disk (eg you upgrade from a 1TB gaming drive to a 4GB gaming drive) you'd have to let every app regenerate its bitmap because all the LBAs would change.
This method would permit a single filesystem call to get the master filehandle on the large asset blob, and then combined with an in-memory copy of that bitmap rosetta stone, the app could possibly issue direct I/O calls underneath to the millions of mapped blocks. This solution is a fragile, brittle, and rigid system that could be made to work but would also potentially suffer a LOT of strange pitfalls when it comes down to how a modern OS expects to be able to manage files separately from block I/O calls.
Also worth noting: in the direct storage I/O stack where the video card and the storage controller can work through a peer-to-peer transfer, there has to be a modification to both the video driver and storage driver stacks. Specifically, when each of those devices goes into PCIe Bus Master mode to do their jobs, the OS needs to know that the underlying hardware is carrying out commands that the OS may not have actually issued or even be aware of. So when the physical video card sends the PCIe TLP commands to the physical storage controller, the upstream OS storage driver needs to be aware of the physical device arbitration status so that other OS-handled I/O requests are properly queued and pipelined to stack in behind the current active bus transfer.
Edit: it later occured to me the singular binary blob of asset data will also require several other steps in how it's created at the filesystem level so that individual assets are written to disk in such a way they align at LBA boundaries. This means there's a pre-step of determining the physical LBA size of the destination storage device before creating the file, and then while creating the asset blob, each asset needs to be padded so that they all line up properly on LBA boundaries. Otherwise you end up with asset fragments that spill over into other LBAs and then you have to build a bunch of extra logic to prune nonsense off the blocks, which also means you're loading more data and burning more GPU cycles than you actually need to.
Example to help illustrate: if your underlying storage device is a modern 4kN drive, then you want your assets padded to the nearest 4 kilobyte boundary -- so a 9KB asset will necessarily consume 12KB on disk -- three 4Kb blocks, padded so that it perfectly fits into three physical blocks. If your underlying storage is actually a 512E or a 512N device, then your 9KB asset could ostensibly only consume 9KB on disk -- eighteen 512b blocks aligned to the underlying eighteen physical blocks.
I remember back when Unreal Engine 5 was first announced and they showed off the Nanite PS5 tech demo.. Tim Sweeney said that PS5's I/O architecture was going to fundamentally change PC architecture in the future. He (Epic) obviously are in contact with all the major players in this space, and likely knew where this was all going and have been pushing the industry to move in that direction. I mean, PC will never be as efficiently designed as a dedicated console, but it also doesn't really have to be. As long of most of the major roadblocks are removed to make it as efficient as possible from storage to VRAM.. that sets things up well for the future. We know that dedicated hardware will be introduced at some point as well.
One potential gain here would be bypassing the need for a second copy of the object in main system memory. While this immediately seems like a win (and it very well could be)
I think this is exactly what we'll get. While a whole new filesystem may be the nirvana from a performance perspective, the co-ordination between vendors and Microsoft is too great IMO for this to happen. Instead we will get something like resizable bar which has theoretical architectural advantages, but in reality shows mixed and limited results. The fact that we are getting this in two seemingly different vendor locked solutions makes that pretty likely IMO. They will each go after the low hanging fruit that they can independently control which in this case appears to be cutting out the system memory copy for GPU destined data transfers from SSD.
you then get into some performance curiosities about leveraging heterogenous GPU systems as a novel way to "hardware accelerate" all the DXIO work away from the active rendering GPU. Mental picture for you: leverage a modern Intel iGPU or the AMD APU as the I/O offload accelerator in this picture; D3D12 already supports this asynchronous compute model today. Modern iGPU/APUs are simultaneously connected to the PCIe root complex and also main system memory. Bypassing main memory becomes an arbitrary and ultimately useless line in the sand for those folks who could use an embedded GPU (and thus, the main system memory pool) to do all the fancy GPU-accelerated decompression and storage management, to then hand it off to the dGPU doing all the raster work.
This is an intriguing possibility. Certainly leveraging the iGPU to handle the CPU destined data decompression which even under the Direct Storage GPU decompression model would still be done on the CPU could be a very real win, both from a architectural perspective and a practical/performance one.
I still see value in passing the GPU destined data directly to the GPU for decompression there, thus avoiding the extra system memory copies and saving PCIe bandwidth (on account of sending compressed data over that bus rather than uncompressed data). But for the CPU destined data then to unburden the CPU itself of that decompression job by utilising the otherwise idle iGPU seems like a excellent use of already present resources.
We know that dedicated hardware will be introduced at some point as well.
I still don't think this is necessarily the case. In fact I think it's less likely than likely to be honest. It's analogous to PhysX processors IMO. Theoretically it's an advantage. But practically it adds, cost, complexity, limits flexibility, and it quite difficult to implement in the PC space because of all the various parties that would need to agree on standards and support. I suspect the likely already good enough GPU implementation that should be relatively easily introducable will win out. I also think that streaming and decompression requirements will become relatively smaller over time compared to growing CPU and GPU performance.
This is an intriguing possibility. Certainly leveraging the iGPU to handle the CPU destined data decompression which even under the Direct Storage GPU decompression model would still be done on the CPU could be a very real win, both from a architectural perspective and a practical/performance one.
I still see value in passing the GPU destined data directly to the GPU for decompression there, thus avoiding the extra system memory copies and saving PCIe bandwidth (on account of sending compressed data over that bus rather than uncompressed data). But for the CPU destined data then to unburden the CPU itself of that decompression job by utilising the otherwise idle iGPU seems like a excellent use of already present resources.
Its a case of 'why not', almost every CPU nowadays sports a integrated iGPU and those are quite capable, many hw features aswell. For laptops its always the case of an iGPU. iGPUs usually arent used when gaming (dedicated gpu).
So again, the bypass of system memory isn't going to net much of anything in terms of CPU cycles saved. You might avoid a handful of milliseconds of data transfer, depending on how big your asset might be.
The enormous all-CPU-consuming pink elephant in the room is the filesystem; most everything else in the work pipeline consumes so very little CPU time as to functionally not matter.
The enormous all-CPU-consuming pink elephant in the room is the filesystem; most everything else in the work pipeline consumes so very little CPU time as to functionally not matter.
So again, the bypass of system memory isn't going to net much of anything in terms of CPU cycles saved. You might avoid a handful of milliseconds of data transfer, depending on how big your asset might be.
The enormous all-CPU-consuming pink elephant in the room is the filesystem; most everything else in the work pipeline consumes so very little CPU time as to functionally not matter.
One would assume that a company as large as Microsoft, who also work with their own consoles, should be able to mitigate and/or find a solution to the filesystem de-effencies.
Filesystems solve real problems that are not necessarily linked to DirectIO function. DirectIO is a block-level function; transferring raw blocks of storage to VRAM means a filesystem has to get out of the way. This isn't about doing smarter things with filesystems, this is about making the filesystem get out of the way.
Microsoft has already stated it's the case though. I don't see why it would be any harder than it is for any other hardware standard and support to happen? This is specifically why AMD and Nvidia (and Intel) are utilizing the standard MS is bringing forward. GPU decompression, and anything else done within the current architecture is a stop-gap to allow actual hardware and architectural changes to be created and adopted by the market.I still don't think this is necessarily the case. In fact I think it's less likely than likely to be honest. It's analogous to PhysX processors IMO. Theoretically it's an advantage. But practically it adds, cost, complexity, limits flexibility, and it quite difficult to implement in the PC space because of all the various parties that would need to agree on standards and support. I suspect the likely already good enough GPU implementation that should be relatively easily introducable will win out. I also think that streaming and decompression requirements will become relatively smaller over time compared to growing CPU and GPU performance.
The SDK has been out for a while, correct? Is there a reason not a single dev has put out a game taking advantage of it? The first high-profile one will be Forspoken and that will be coming out almost a year after DirectStorage was made available.
Is it time-consuming/complicated to implement?
Is it time-consuming/complicated to implement?
DegustatoR
Legend
It is likely time consuming to implement while providing smallish actual benefits.The SDK has been out for a while, correct? Is there a reason not a single dev has put out a game taking advantage of it? The first high-profile one will be Forspoken and that will be coming out almost a year after DirectStorage was made available.
Is it time-consuming/complicated to implement?
That's disappointing. I've been hearing about the supposed great benefits for over two years now.It is likely time consuming to implement while providing smallish actual benefits.
IMOThat's disappointing. I've been hearing about the supposed great benefits for over two years now.
We are still very much in cross gen period.
So what would be the benefit for a studio to rewrite their loading and streaming code?
Faster loading, less demands on cpu for a cross gen title is probably hardly worth it.
DegustatoR
Legend
Such benefits could be coming with GPU decompression path being added but without it I rather doubt that DS bring much to the table in terms of actual I/O performance.That's disappointing. I've been hearing about the supposed great benefits for over two years now.
And if I remember this was supposed to be part of RTX IO which is still MIA two years later.Such benefits could be coming with GPU decompression path being added but without it I rather doubt that DS bring much to the table in terms of actual I/O performance.
So again, the bypass of system memory isn't going to net much of anything in terms of CPU cycles saved. You might avoid a handful of milliseconds of data transfer, depending on how big your asset might be.
But that reduced latency may have some benefits I guess? Perhaps say for SFS where there is a very short window to fetch the necessary tile from memory? I'm certainly not expecting anything massive in terms of real world performance improvements from Smart Access Storage or RTX-IO though.
Microsoft has already stated it's the case though. I don't see why it would be any harder than it is for any other hardware standard and support to happen? This is specifically why AMD and Nvidia (and Intel) are utilizing the standard MS is bringing forward. GPU decompression, and anything else done within the current architecture is a stop-gap to allow actual hardware and architectural changes to be created and adopted by the market.
If I recall correctly, didn't they say something along the lines of it's something they are investigating for the future? So not a guarantee from what I understood. The difficulties here would be deciding which compression formats to use because once agreed, they would be very difficult to change in future. Say it supports zlib and Kraken like the PS5 unit. Well for one that would be a pretty big competitive advantage for Oodle because devs would then be forced to license their product if they want to enjoy hardware based decompression (I'm not sure how licensing works for zlib based compression). But more importantly what happens if in future a better compression solution comes along? On the PS4/XBO generation for example that's exactly what happened and it ended up making their zlib based decompression units mostly redundant as devs often chose to use better methods (like Kraken) on the CPU. With GPU based decompression, any new solution could presumably be used provided it's able to be decompressed on GPU compute units via DirectStorage. With hardware based units though the onus would be on the vendor to add that functionality to the silicon, and anyone still using an older decompression block would be unable to use that new format. That then means devs probably won't use it because the majority of their customer base won't be able to take advantage of it and thus fall back to a much slower CPU software based solution. Better to just compress the game content with the older less efficient system that most people are able to take advantage of. So we have a chicken and egg situation much worse than that of graphics features vs game implementation.
The second big issue is who would be responsible for building that decompression block? if it were to sit where it does in the consoles then that would fall to Intel/AMD to incorporate it on the CPU. And I'm struggling to see what the motivation for that would be. For one, surely it would be better to just use the already present IGPU as @Albuquerque suggested above, and two, that will take up die space and add cost/complexity to ALL CPU's when this is a gaming specific feature, so would they really want that? Also by this point the majority of that work will already have been offloaded to the GPU so what motivation do Intel have for including additional hardware in their CPU's to take workload off a GPU? AMD may see it differently of course.
That's why I said in an earlier post that the GPU itself might be the better location for the block, but that still hits issue one above, and it's less than ideal for dealing with data that is destined for the CPU rather than the GPU.
IMO, simply decompressing CPU data on the iGPU and GPU data on the GPU with the data for each being routed directly from SSD to the appropriate memory pool is the most elegant way of doing this and has no down sides that in can see vs doing it on a dedicated ASIC (aside from the ASIC maybe consuming a bit less power in the process), it even has the advantage over a hardware based unit in that compressed data can be sent over the GPU's PCIe bus thus saving significant bandwidth there. The only caveat is whether there are any specific gotchas that make the iGPU approach and/or P2P DMA of data direct to VRAM unworkable.
That's disappointing. I've been hearing about the supposed great benefits for over two years now.
Nixxes looked at it but if I recall the interview correctly chose not to implement because they weren't file IO bound in the first place? I guess there are so many other bottlenecks in the loading process that the effort to implement DS as it stands right now may not be worth it. But that will likely change once Direct Storage implements the GPU decompression capability which certainly has the potential to have a big impact.
And if I remember this was supposed to be part of RTX IO which is still MIA two years later.
From the very limited information released so far, RTO-IO seems to be something subtly different. Rather than being a requirement for GPU based decompression which appears as though it might be a core component of the Direct Storage API itself, RTX-IO seems to be doing something similar to what AMD's Smart Access Storage is claiming by sending game data directly from the SSD to the GPU's VRAM without having to first go via the CPU and system memory.
But that reduced latency may have some benefits I guess? Perhaps say for SFS where there is a very short window to fetch the necessary tile from memory? ny other bottlenecks in the loading process that the effort to implement DS as it stands right now may not be worth it.
Any gain is a gain, I suppose. Still, in order for this whole object load process to fully skip system memory, we still have to get DirectI/O doing the things which it promised re: direct block transfer from storage device to video card device. I've provided my own perspective on how this might be solved, and while I have decades of experience in storage technology from both the OS side as well as the hardware and FC/iSCSI/FCoE/Converged/NVMeOF topology side, that still doesn't qualify me to speak with authority on what Microsoft is actually going to do.
Windows DirectI/O is a block transfer function by design and intentioned use.
Windows filesystems do not provide, by design and intentioned use, any block transfer capability.
Forcibly retooling an existing Windows FS to emulate a block storage device will result in aggregating the negatives of each.
"Speaking For Myself" I see no useful way for DXIO to be constructed on top of an existing Windows file system.
Today and right now, DXIO/DXStorage really seems to be about offloading decompression of assets to the GPU, not necessarily about completely retooling the end-to-end loading of assets from vendor-agnostic storage directly into vendor-agnostic VRAM.
DegustatoR
Legend
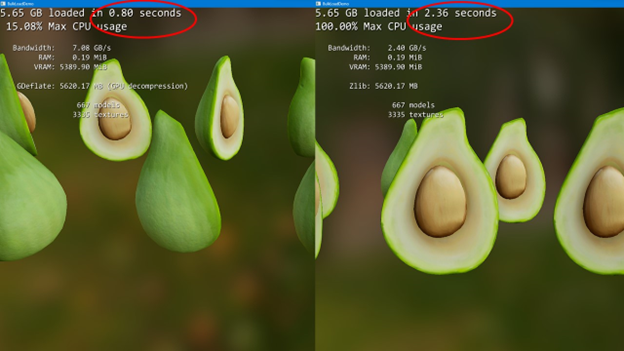
DirectStorage 1.1 Coming Soon - DirectX Developer Blog
When we shared our first public release of DirectStorage on Windows to reduce CPU overhead and increase IO throughput, we also shared that GPU decompression was next on our roadmap. We are now in the final stretch of development and plan to release DirectStorage 1.1 with GPU Decompression to...
 devblogs.microsoft.com
devblogs.microsoft.com
With DirectStorage 1.1, we present a new compression format, contributed by NVIDIA, called GDeflate.
“NVIDIA and Microsoft are working together to make long load times in PC games a thing of the past,” said John Spitzer, VP of Developer and Performance Technology at NVIDIA. “Applications will benefit by applying GDeflate compression to their game assets, enabling richer content and shorter loading times without having to increase the file download size.”
GDeflate is a novel lossless data compression standard optimized for high-throughput decompression on the GPU with deflate-like compression ratios. GDeflate saves CPU cycles by offloading costly decompression operations to the GPU, while saving system interconnect bandwidth and on-disk footprint at the same time. GDeflate compression is inherently data-parallel, which enables greater scalability across a wide range of GPU architectures. It is designed to provide significant bandwidth amplification when loading from the fastest NVMe devices, supporting both bulk-loading and fine-grained streaming scenarios.
GDeflate provides a new GPU decompression format that all hardware vendors can support and optimize for. Microsoft is working with key partners like AMD, Intel, and NVIDIA to provide drivers tailored for this format. “Intel is excited to release drivers co-engineered with Microsoft to work seamlessly with the DirectStorage Runtime to bring optimized GPU decompression capabilities to game developers!” said Murali Ramadoss, Intel Fellow and GM of GPU Software Architecture. Like all DirectX technologies, with DirectStorage, Microsoft is working to ensure that gamers have great options for compatibility and performance for their hardware.
Last edited:
Very interesting that GDeflate was developed by Nvidia as an open standard.
I can't wait to see the compression ratios ("deflate like") and speeds on various GPU's.
Great to see this is coming to soon.
I can't wait to see the compression ratios ("deflate like") and speeds on various GPU's.
Great to see this is coming to soon.
Similar threads
- Replies
- 2K
- Views
- 237K
- Replies
- 3
- Views
- 4K
- Replies
- 13
- Views
- 6K
- Replies
- 204
- Views
- 34K
- Replies
- 43
- Views
- 11K