Bondrewd
Veteran
It's not delayed.Hopefully Navi 32 is delayed until the clockspeeds really can hit 3+ghz or so
Right on money chefe.That would put it at 80% of the performance of a 7900xtx at like, $649 (or less).
It's not delayed.Hopefully Navi 32 is delayed until the clockspeeds really can hit 3+ghz or so
Right on money chefe.That would put it at 80% of the performance of a 7900xtx at like, $649 (or less).

Well yeah, they do a prim unit per shader array and N31 has 50% more of them over N21.adding new hardware for primitive culling.
It seems there's another slide deck, as seen here:
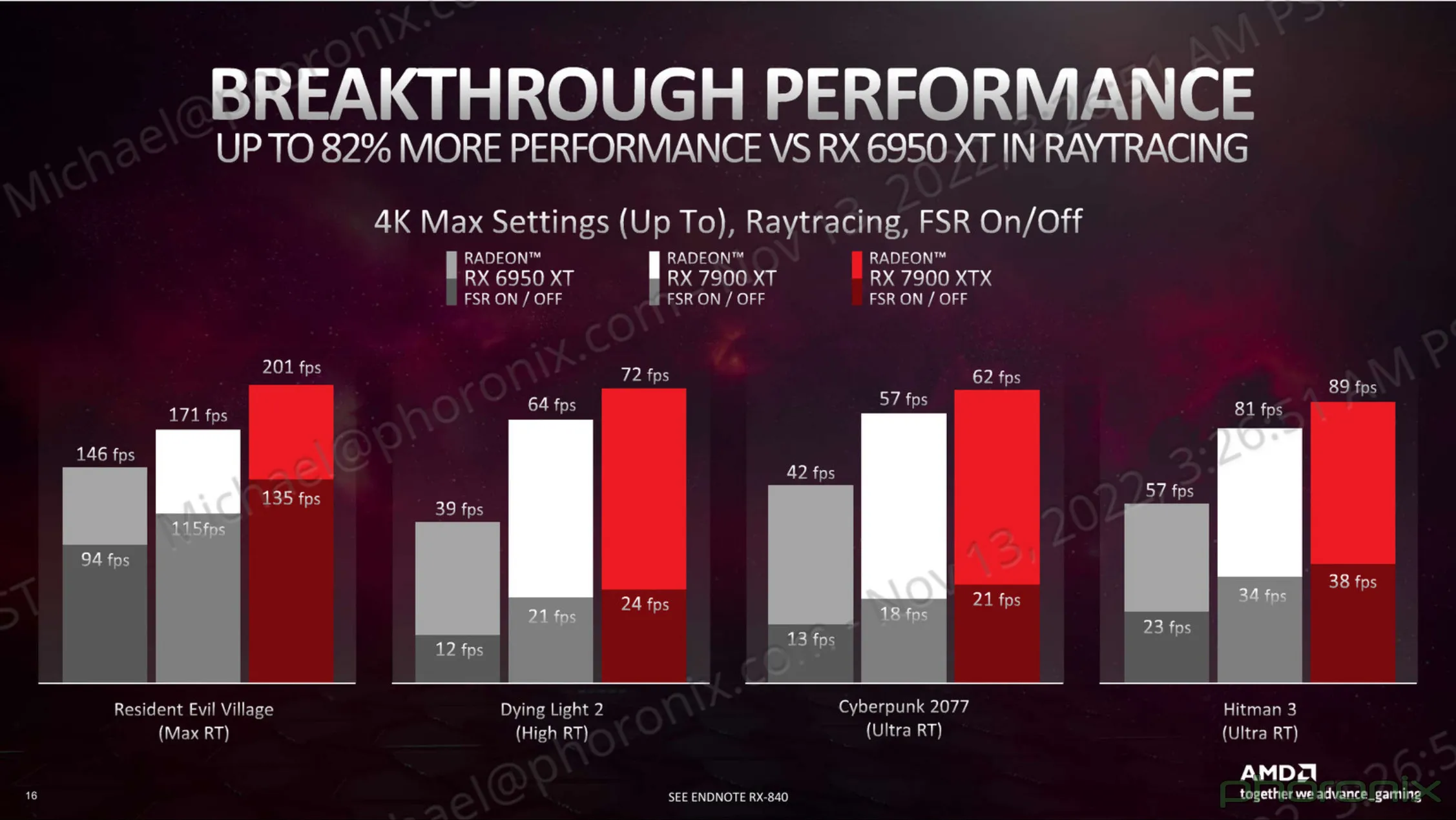
So as I've said, 7900XT will be more or less equal to 4080 in "rasterization" and will loose heavily when any RT will come into play.
There's a lot of RDNA3 performance numbers going around. Is that tweet including FSR in the 7900XT comparison against the 4080?
Perf numbers by Quasar Zone are for maxed out C2077 at 4K, no RT, and DLSS/FSR are used.Is that tweet including FSR in the 7900XT comparison against the 4080?
I‘m confused that they write in headline 12 prim/clk and in the text 24 prim/clk. I think normally it uses 12 prim/clk, when you use primitive shader and put it in your program you get 24 prim/clk?It seems, according to this slide:
that there is native "fixed function primitive culling hardware to remove SW based culling overhead" which implies that AMD has gone "backwards" with NGG (primitive shaders), adding new hardware for primitive culling.
Is that the correct interpretation?
") Waiting 10 years for beyond3d suite 2.0
Waiting 10 years for beyond3d suite 2.0"Primitives" and "vertices" in the text - they're not actually the same thing.I‘m confused that they write in headline 12 prim/clk and in the text 24 prim/clk. I think normally it uses 12 prim/clk, when you use primitive shader and put it in your program you get 24 prim/clk?
"Primitives" and "vertices" in the text - they're not actually the same thing.
In a mesh there's approximately one triangle (primitive) per vertex, but when a mesh "wraps" around an object, going from front-facing to back-facing there are potentially some triangles that end up being viewed edge-on. They are degenerate (have 0 area measured in screen pixels), so should be culled, though they are not actually back-facing.
Another cause of culling within a mesh is when some triangles end-up entirely outside of the screen. The mesh in this case is near the edge and only parts of it fall over the edge. Only triangles whose full set of vertices are outside of the screen can be culled though, you can't cull a triangle which only has one vertex that's outside.
But anyway, none of this relates to the question I have, the apparent non-use of NGG because there's fixed function hardware to remove software culling overhead.
Really don't know.Was NGG ever used?
I think they mean that you had to write some special code if you want to use the new pipline in your software. Didn't we discussed here that there are special commands for NGG? And i think now you can use the normal Piplines (DX11, DX12 and Vulcan) withouth the command and the polyons will automaticly bean routet to NGG?Really don't know.
The reference to "software based culling overhead" is the key here and I can't tell what AMD is actually describing. This overhead has been "removed" in RDNA 3. Does that imply AMD has been using NGG, but with RDNA 3 that's been dropped in favour of fixed function hardware?
Was NGG ever exposed in client side s/w as something you can program for? AFAIR all geometry went through NGG automatically starting with RDNA1.I think they mean that you had to write some special code if you want to use the new pipline in your software. Didn't we discussed here that there are special commands for NGG? And i think now you can use the normal Piplines (DX11, DX12 and Vulcan) withouth the command and the polyons will automaticly bean routet to NGG?
 forum.beyond3d.com
forum.beyond3d.com
What you can do on PS5 rarely has any relevance to what you can do on PC.Didn't we discussed thet here:

Current Generation Hardware Speculation with a Technical Spin [post GDC 2020] [XBSX, PS5]
Nintendo did it with Switch. There are games (MK11?) that run higher clocks in general (maybe just in handheld mode), and they also added a boost to clocks specific to some games during loading screens. The former has an impact on battery life, the latter may have an impact, but it might also...
There are now only 2 HW shader stages for vertex/geometry processing:
- Surface shader which is a pre-tessellation stage and is equivalent to what LS + HS was in the old HW.
- Primitive shader which can feed the rasterizer and replaces all of the old ES + GS + VS stages.
Compared to the old HW VS, a primitive shader has these new features:
- Compute-like: they are running in workgroups, and have full support for features such as workgroup ID, subgroup count, local invocation index, etc.
- Aware of both input primitives and vertices: there are registers which contain information about the input primitive topology and the overall number of vertices/primitives (similar to GS).
- They have to export not only vertex output attributes (positions and parameters), but also the primitive topology, ie. which primitive (eg. triangle) contains which vertices and in what order. Instead of processing vertices in a fixed topology, it is up to the shader to create as many vertices and primitives as the application wants.
- Each shader invocation can create up to 1 vertex and up to 1 primitive.
- Before outputting any vertex or primitive, a workgroup has to tell how many it will output, using s_sendmsg(gs_alloc_req) which ensures that the necessary amount of space in the parameter cache is allocated for them.
- On RDNA2, per-primitive output params are also supported.
Notes about hardware support
- Vega had something similar, but I haven’t heard of any drivers that ever used this. Based on public info I cound find, it’s not even worth looking into.
- Navi 10 and 12 lack some features such as per-primitive outputs which makes it impossible to implement mesh shaders on these GPUs. We don’t use NGG on Navi 14 (RX 5500 series) because it doesn’t work.
- Navi 21 and newer have the best support. They have all necessary features for mesh shaders. We enabled shader culling by default on these GPUs because they show a measurable benefit.
- Van Gogh (the GPU in the Steam Deck) has the same feature set as Navi 2x. It also shows benefits from shader culling, but to a smaller extent.

 gitlab.freedesktop.org
gitlab.freedesktop.org
The VS (or TES) is butchered into two parts:
- Top part: ES vertex threads compute only the position output and store that to LDS.
- Culling code
- GS threads load the positions of each vertex that belongs to their triangle and decide whether to accept or cull the triangle.
- Surviving vertices are repacked if needed.
- Bottom part: ES threads of the repacked, surviving vertices compute the other outputs.
One interesting bit brought up by this patch series is that with GFX11, Next-Gen Geometry (NGG) is now always enabled.

Well of course, that's likely one reason why it doesn't support mesh shaders. RDNA1 is a dinosaur architecture.It's notable that RDNA 2 has functionality there that's not present on RDNA 1. Which may be relevant to general conclusions regarding NGG culling being of no benefit on RDNA 1.
Yes but no. They're there to support the WMMA-instructions, Dot2 (FP16, BF16, INT8) and Dot4 (INT4), but they still employ all the "normal ALUs" in Compute Unit, not just those accelerators.RDNA3 really has dedicated matrix accelerators after all!
That's really exciting!
Well of course, that's likely one reason why it doesn't support mesh shaders. RDNA1 is a dinosaur architecture.
RDNA3 really has dedicated matrix accelerators after all!
View attachment 7552
That's really exciting!
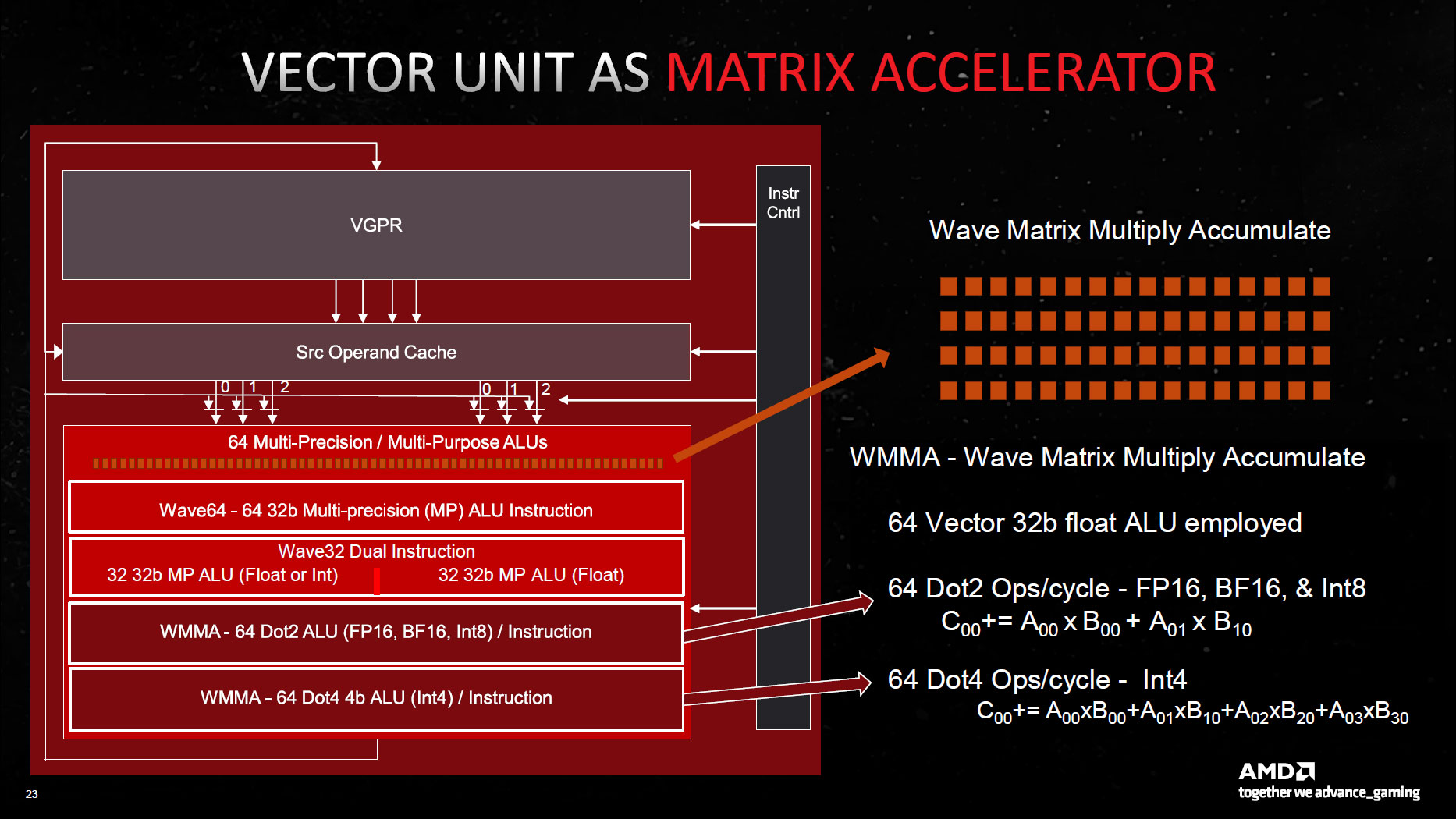
This is factually the case according to one of the articles I've just linked, Mesh Shaders requires per-primitive output parameters.Well of course, that's likely one reason why it doesn't support mesh shaders. RDNA1 is a dinosaur architecture.
