Install the app
How to install the app on iOS
Follow along with the video below to see how to install our site as a web app on your home screen.
Note: This feature may not be available in some browsers.
You are using an out of date browser. It may not display this or other websites correctly.
You should upgrade or use an alternative browser.
You should upgrade or use an alternative browser.
Possibly related to the fact that while FP capability per CU doubled, INT didn't. Or that the double capability requires some ILP to work.Has AMD hinted at which matrix workloads or libraries they’re targeting? FSR 3.0?
If SIMD throughput is 64x32b or 2x32x32b that would make Navi31 a 12288x32b chip. Why is it marketed as 6144?
Possibly related to the fact that while FP capability per CU doubled, INT didn't. Or that the double capability requires some ILP to work.
64x32b implies ILP isn’t required.
Depends on which spends more transistors, the ALUs or the data movement. If getting operands to the units takes more die area than the ALUs themselves, doubling up on compute might be transistor-efficient to get more use of the data paths, even if the compute sits idle a lot of the time. Just to get more use out of the system in the rare cases when enough operands can be delivered to run two ops in parallel.I suspect you're right, but it wildly contradicts the "extract maximum value from each transistor" statement on that first slide I included.



Jawed
Legend
That's "wave64 mode", typically used by pixel shaders.64x32b implies ILP isn’t required.
Of course if there are integer instructions (per pixel) then those instructions in the pixel shader progress at half rate, because there's only 32 lanes of integer ALU capability.
Super SIMD was supposedly motivated by making more effective use of vector register file bandwidth - a lot of time the bandwidth with old architectures was wasted.Depends on which spends more transistors, the ALUs or the data movement. If getting operands to the units takes more die area than the ALUs themselves, doubling up on compute might be transistor-efficient to get more use of the data paths, even if the compute sits idle a lot of the time. Just to get more use out of the system in the rare cases when enough operands can be delivered to run two ops in parallel.
As it happens, wave64 mode is the common case that will get good value out of these 64 lanes. The concern then rests with compute workloads in cases where 32 work item workgroups are used. Ray tracing is one of those cases, but maybe the traversal code has high ILP?
That's "wave64 mode", typically used by pixel shaders.
Of course if there are integer instructions (per pixel) then those instructions in the pixel shader progress at half rate, because there's only 32 lanes of integer ALU capability.
Super SIMD was supposedly motivated by making more effective use of vector register file bandwidth - a lot of time the bandwidth with old architectures was wasted.
As it happens, wave64 mode is the common case that will get good value out of these 64 lanes. The concern then rests with compute workloads in cases where 32 work item workgroups are used. Ray tracing is one of those cases, but maybe the traversal code has high ILP?
If it all of that is true why is AMD sandbagging? Is there actually enough operand bandwidth to feed 64 FMAs?
DegustatoR
Legend
My guess is that they want to present it as "very effective per flop architecture" which would turn into the opposite with 2x the FP32 ALU number - see Turing vs Ampere.If it all of that is true why is AMD sandbagging? Is there actually enough operand bandwidth to feed 64 FMAs?
Jawed
Legend
My understanding is that the bandwidth is only available if at least one operand comes from a prior instruction, where the resultant of that instruction is cached and fed to the ALUs without requiring it to be read from a VGPR. There is an arrow on the diagram that implies as much:If it all of that is true why is AMD sandbagging? Is there actually enough operand bandwidth to feed 64 FMAs?
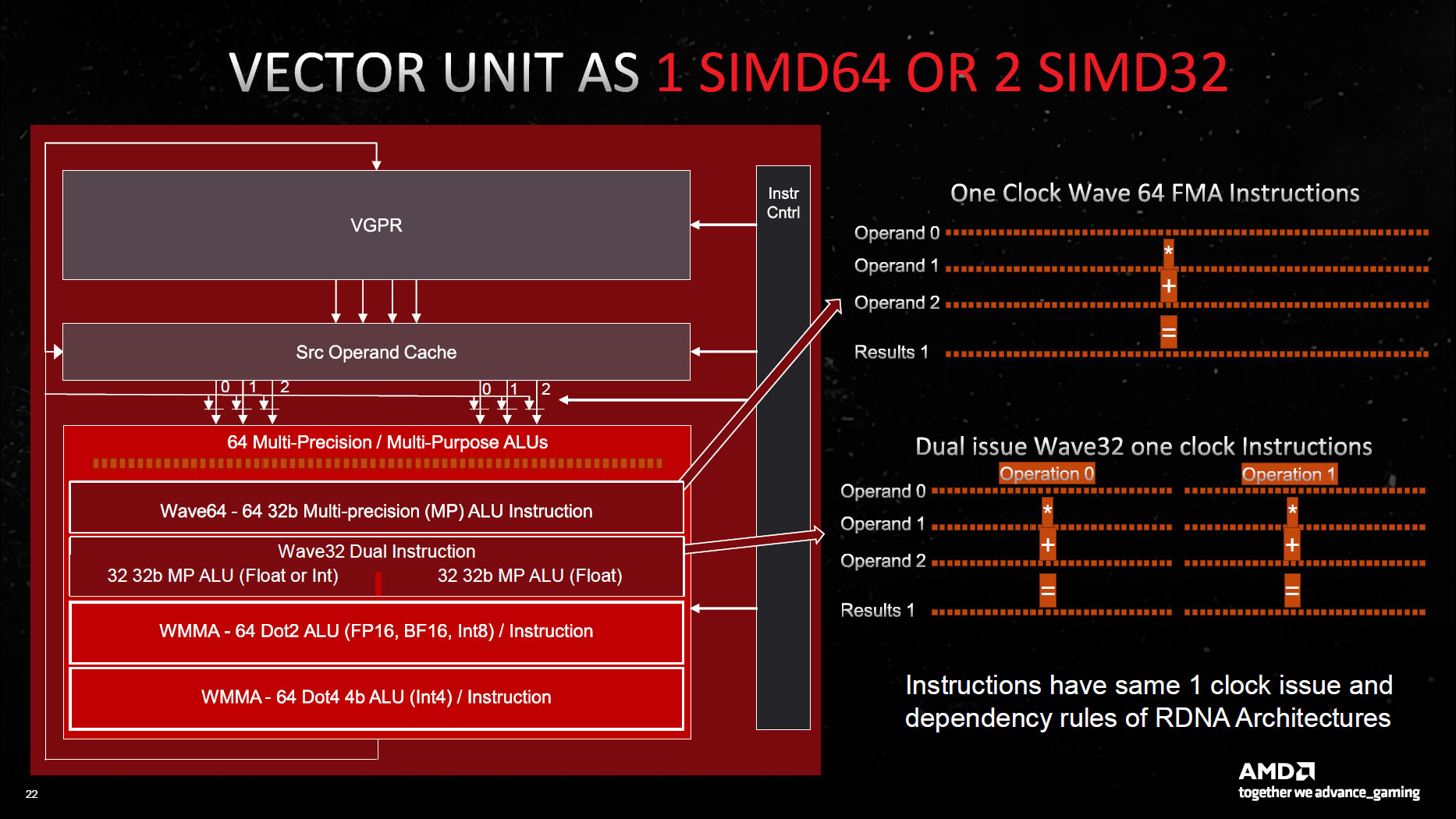
As an aside, I think AMD is sandbagging with many of the performance claims in these slide decks. But the margin from +20% to +50% isn't really that exciting so it probably doesn't matter much.
It's not going to change the +/- RTX4080 at $200 less conclusions that we have to wait a month for.
DegustatoR
Legend
Primitive shader is a s/w defined stage of geometry processing in RDNA GPUs. As far as we can tell all geometry runs through it on RDNA, mesh shaders including. It looks like RDNA3 has some additional h/w supporting this path now freeing main SIMDs from some calculations (presumably).Is Primitive Shaders now working better then Mesh Shader or is it just another name for the same thing?
DegustatoR
Legend
Shaders are s/w thus a primitive shader is also s/w. But it can run on separate h/w in part or even fully. In this case it's a s/w (shader) which does some sort of geometry processing.Short question what is s/w ?
DegustatoR
Legend
There are some h/w requirements for supporting mesh shaders. But the processing itself is done on main FP32 ALUs.But i thought that mesh shader have to be in Hardware?
Impossible to tell but unlikely. No reason for them to have something like that.So AMD have now more hardware then needed for mesh shader?
TopSpoiler
Regular
Is Primitive Shaders now working better then Mesh Shader or is it just another name for the same thing?
Primitive shader - Advanced Micro Devices, Inc.
Improvements in the graphics processing pipeline are disclosed. More specifically, a new primitive shader stage performs tasks of the vertex shader stage or a domain shader stage if tessellation is en
 www.freepatentsonline.com
www.freepatentsonline.com
Hmm i searched a little bit found these 3 intersting articles about AMD implementation:

 blog.siggraph.org
blog.siggraph.org

 disruptiveludens-wordpress-com.translate.goog
disruptiveludens-wordpress-com.translate.goog
How mesh shaders are implemented in an AMD driver
In the previous post I gave a brief introduction on what mesh and task shaders are from the perspective of application developers. Now it’s time to dive deeper and talk about how mesh shaders are implemented in a Vulkan driver on AMD HW. Note that everything I discuss here is based on my...
timur.hu
Mesh Shaders Release the Intrinsic Power of a GPU - ACM SIGGRAPH Blog
Jon Peddie Research shares how it has taken 20 years to realize the intrinsic power of a GPU through mesh shaders.
Primitive vs Mesh Shader, aclarando la confusión
El mayor cuello de botella que han tenido las GPU en todos estos años ha sido la etapa de rasterizado, donde es completamente igual la capacidad de cálculo de toda la geometría previa, que si la un…
disruptiveludens-wordpress-com.translate.goog

AMD RDNA 3 GPU Architecture Deep Dive: The Ryzen Moment for GPUs
Swimming with the next generation GPUs
That Ryzen moment for GPUs is kinda telling on the situation, it might be their great chance.
IIRC mesh shaders require some hardware plumbing that allow certain data sharing between the CUs and rasterizer blocks but I'm not positive.But i thought that mesh shader have to be in Hardware? So AMD have now more hardware then needed for mesh shader?
Jawed
Legend
I don't really understand this, but I suspect they are using spare bits that were perhaps unused in RDNA 2.View attachment 7554
Sounds they can now skip over testing triangles, if the ray intersects none of the child boxes?
Referring back to:

RDNA2 hardware BVH · Wiki · Bas Nieuwenhuizen / mesa · GitLab
Mesa 3D graphics library
 gitlab.freedesktop.org
gitlab.freedesktop.org
I'm going to guess that 32-bits (4 bytes) of ID is excessive. So by using less bits, they can put instance/ray flags into the ID (pointer, as described in the slide).
Also, notice that FP32 box nodes have unused bytes, 16 of them according to that page. So maybe that's where the geometry flags go?
The Phoronix article misses this crucial slide though:

which means that RDNA 3 adds two new modes, Largest-first and Closest-midpoint.
I think at each traversal step, where it specifies the box node it wants to evaluate, it sets bits relating to instancing and/or ray flags as part of the ID that it sends to the ray accelerator. So the ID is really a composite data field when requesting box node results. When traversal is being performed for shadow rays, say, turn on the bit that specifies largest-first child sorting.
I don't understand how discarding empty ray quads could have been a problem on RDNA 2 and why RDNA 3 is better when these quads are discarded.But idk about 'DXR ray falgs'.
View attachment 7555
When a quad is predicated-off, as the slide seems to indicate, it should have no material shading execution under RDNA 2. Which should mean that there is no memory request associated with that quad.
On the contrary, the slide indicates that RDNA 3 moves distinct materials into disparate quads. So, starting with three distinct materials, it puts those materials into three distinct quads. This prevents the first quad from performing two distinct memory requests because it is handling two materials. In this aspect this would be an improvement over RDNA 2.
This doesn't really answer what happens when there's a lot of predicated-on work items, such that every quad has two or more materials... I suppose there is more likely to be a common material amongst the quads or within quads as the number of predicated-on work items increases.
Similar threads
- Replies
- 85
- Views
- 12K
- Replies
- 185
- Views
- 21K
- Replies
- 86
- Views
- 18K
- Replies
- 59
- Views
- 8K
- Replies
- 15
- Views
- 2K