You are using an out of date browser. It may not display this or other websites correctly.
You should upgrade or use an alternative browser.
You should upgrade or use an alternative browser.
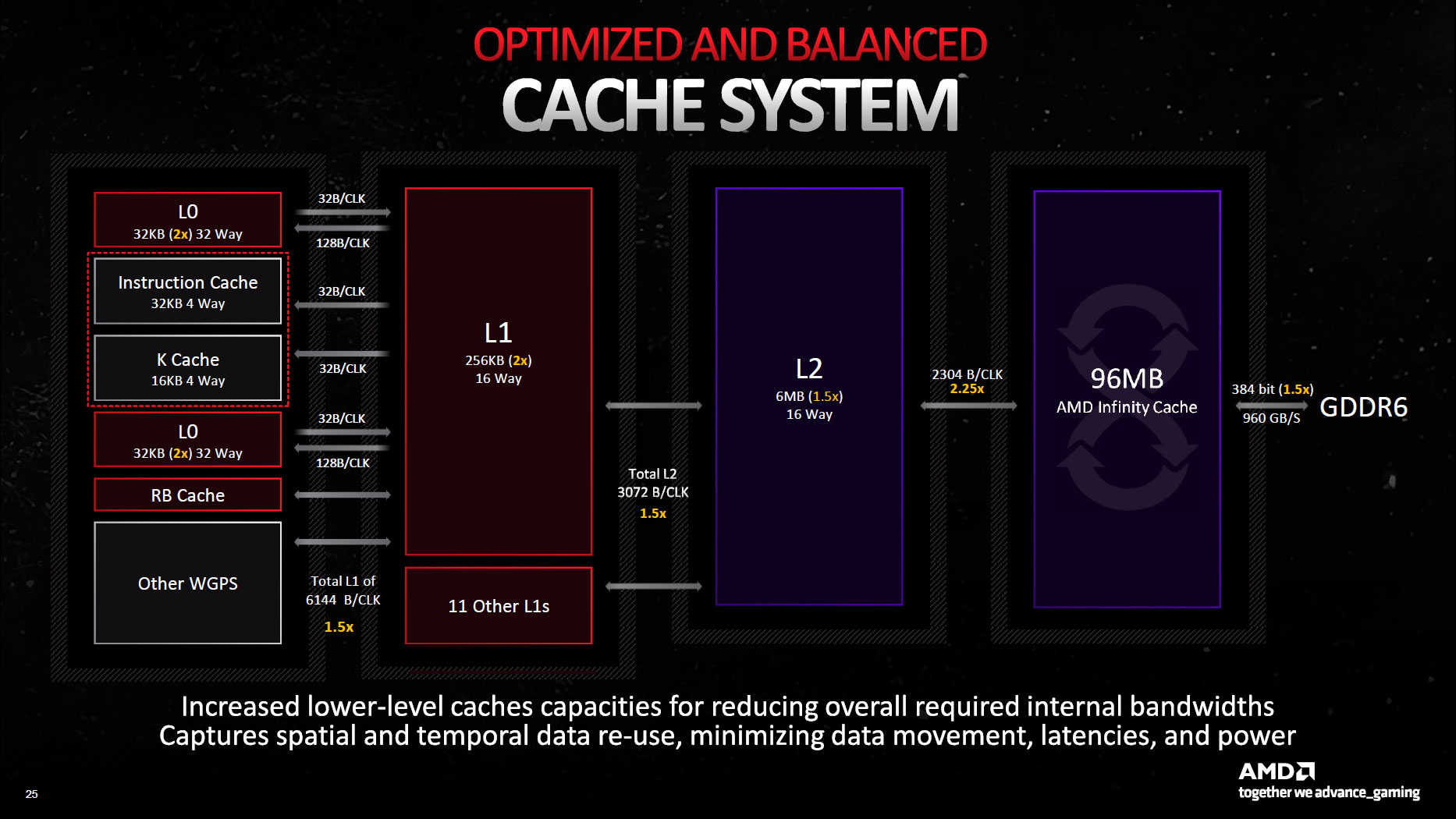
2304 bytes/clock for 96MB infinity cache, 192B/slice assuming same number of slices. That'll be 1536 bytes/clock for N32 (1.5x N21, 2x N22) and 768 bytes/clock for N33 (same as N22, 3x N23) so crazy bandwidth numbers all around. N31 has more L3 bandwidth per cycle than N21's L2, 2048 bytes/clockDid they reduce the clocks a lot (~1.4GHz), go 4MB slices and double width per slice (24 slices, 128B/clock)? 192B/clock, 12x 8MB (same as RDNA2), 1.88GHz?
It's not baffling. Moores law is dead, so the only way to get serious speedups is to have serious higher price as well.Nvidia is going to charge far more than they used to for things that imply the exact same names. Literally all they had to do was type a different set of names in some marketing doc and they'd have solved these unnecessary problems, but somehow they couldn't manage it. Baffling.
If they would bring back Titan labels for the high end, people would just focus on lower end, concluding that high end is not for games (which is exactly the truth as i see it).
If they keep the same naming, they can hope people just accept the increasing price but keep loyal to their x80 model they bought for decades. Just fool them with enough of RT and AI snakeoil to prentend increased value for the extra money.
Yes, maybe i should express myself more restrained, saying the same thing more gently. I just can't becasue i think their Poker games hurt the games industry as a whole much more than the old promises of photorealism could help it.
The solution really is obvious and easy: Accept big HW speedups are thing of the past, and focus on other things like efficiency, form factor, minimized costs. Benefit for everybody, and we have no other choice anyway.
I wonder why most people can not even consider a stagnation on HW power. Seriously, i fail to understand the desperate desire on doubling down teraflops again and again at any cost.
But i wonder even more which platform makes the race in the end. If PC can't evolve, recent high end mobile GPUs already look very promising on paper. That's not cheap either, but small and efficient.
Seems whoever dares to tackle the sweet spot middle ground would win gaming, but nobody actually does.
Bondrewd
Veteran
Bumped L0/L1 capacity also means smaller LLC parts like N33 have considerably higher memperf over N23.That'll be 1536 bytes/clock for N32 (1.5x N21, 2x N22) and 768 bytes/clock for N33 (same as N22, 3x N23) so crazy bandwidth numbers all around
S'just nice.
Or you can do what AMD did and focus on tiles and raw PPA.so the only way to get serious speedups is to have serious higher price as well.
There's a limit to that obviously but still a way saner approach that burning N5/N3e/N2/you-name-it wafers for lulz.
DegustatoR
Legend
That would be true if 6800XT wouldn't exist in the world.The problem is Nvidia and Nvidia fans using the crypto priced Ti versions of Ampere as comparisons to justify the new pricing, ignoring the rest of the stack as it's not convenient for them.
Exactly.The problem is Nvidia and Nvidia fans using the crypto priced Ti versions of Ampere as comparisons to justify the new pricing, ignoring the rest of the stack as it's not convenient for them.
4080 16GB vs 3080 10GB($700):
35-40% more performance for 70% higher price. Narrative - atrocious value for a new generation part.
4080 16GB vs 3080Ti($1200):
25-30% more performance for the same price. Narrative - bit underwhelming, but an ok improvement in value.
4080 16GB vs 3090Ti($2000):
20% more performance for $800 less. Narrative - insane improvement in performance per dollar, absolute steal.
These are drastically different narratives depending on which point of comparison you choose to use even though we're talking about the same part in all three. And personally, I'd say it's absurd to use cards that were considered 'terrible value' when they released, like the 3080Ti and 3090Ti, as any point of comparison because they will inherently flatter a newer part. And that's exactly why some people do this, dishonestly.
Frenetic Pony
Veteran
Those who are able to spend $1200 on a GPU will spend as much on a GPU no matter what it's named. Those who are able to spend $800 would not spend $1200 on GPU just because it would be named differently. It's weird to even suggest the opposite.
No it's not. That's like suggesting the entire field of marketing is a lie, all just worthless, obviously the only thing anyone on earth concentrates on is fair benchmarks. Which people in this very forum prove wrong, let alone the rest of the world.
People believe marketing. They believe marketing a lot. The entire crypto craze was marketing and it was worth hundreds of billions (much of which has vanished now). The entire high end fashion industry is marketing. There's people out there that will literally buy a 4090 because it's the "most expensive one" even if the 7900 was twice as fast. Seen people claim that doing anything less would make them feel cheap.
We live in a world where people run around claiming the earth is flat, the moon landing was faked, and you can get healed by crystals. "Gamers" fall for it just as much, Nidia fanbois will pay a 50% markup in price for performance just to get the Nvidia name. They'll pay for ultra uwu guns skins and shout the heavens about how much their Overwatch waifu's costumes cost. The power of marketing should not be underestimated at all.
Last edited:
Tiles are the same one trick pony as the magic tm infinity cache and the PPA is a zero sum game, where you mostly trade 1 parameter for another with rare exceptions.did and focus on tiles and raw PPA
As an evolution suggests, specialization is your best friend when it comes to efficiency. Moreover, there is just 1 way of rendering things right and that's RT, not 1000s, so specialization has a perfect sense.
Unfortunately for the whole industry, hovewer, everybody, joej included, wants to reinvent the wheel. If you want to be fast in 1000s of algorhithms you have to produce bloated HW, that's it.
So hopefully this addresses Joej's question on why there is the desperate desire on doubling down teraflops again
Bondrewd
Veteran
Oh no, my boy.Tiles are the same one trick pony
Oh no.
This is but a tiny taste of what's to come.
Good news we're not moving away from hybrid renderer garbage for at least a decade to come.Moreover, there is just 1 way of rendering things right and that's RT
So the 'correct' way kinda does the pissoff maneuver for a looooooooot while longer.
Jawed
Legend
Apparently this is an AMD slide:
Any ideas where it comes from?
Any ideas where it comes from?
Bondrewd
Veteran
The tech brief slide deck which is somewhere here.Any ideas where it comes from?

AMD RDNA 3 GPU Architecture Deep Dive: The Ryzen Moment for GPUs
Swimming with the next generation GPUs
Yes. From my perspective AMD always does the right thing. The origin of my NV attitude was the day i bought some midrange GCN to estimate console performance of my stuff, and then it blew even a Titan out of the water in terms of performance. I felt like being scammed all the years before.Or you can do what AMD did and focus on tiles and raw PPA.
There's a limit to that obviously but still a way saner approach that burning N5/N3e/N2/you-name-it wafers for lulz.
But AMDs problem is: They fail to take advantage. They never tried to sell a vision or an idea. They never tried to educate game devs about what compute could be used for. They never marketized their compute advantage to consumers at all.
Meanwhile people say NV did catch up and has the lead with compute performance too. Personally i believe this only once i see it myself, but well - who cares about that now.
What AMD should do now is making this gaming PC on a chip that i want to happen. Chip would be expensive, but the rest of the PC costs almost nothing. And it shouldn't be that hard to generate some volume with such system, besides impressing the world with competing Apple, not just Intels NUC gimmicks.
Much better marketing arguments than path traced retro games, and a real future.
Intel should do the same, ofc. So we still have comptition. Maybe NV even gets their x86 license along the process, for fair reasons.
Make the paltform interesting again! ; )
Jawed
Legend
It seems there's another slide deck, as seen here:
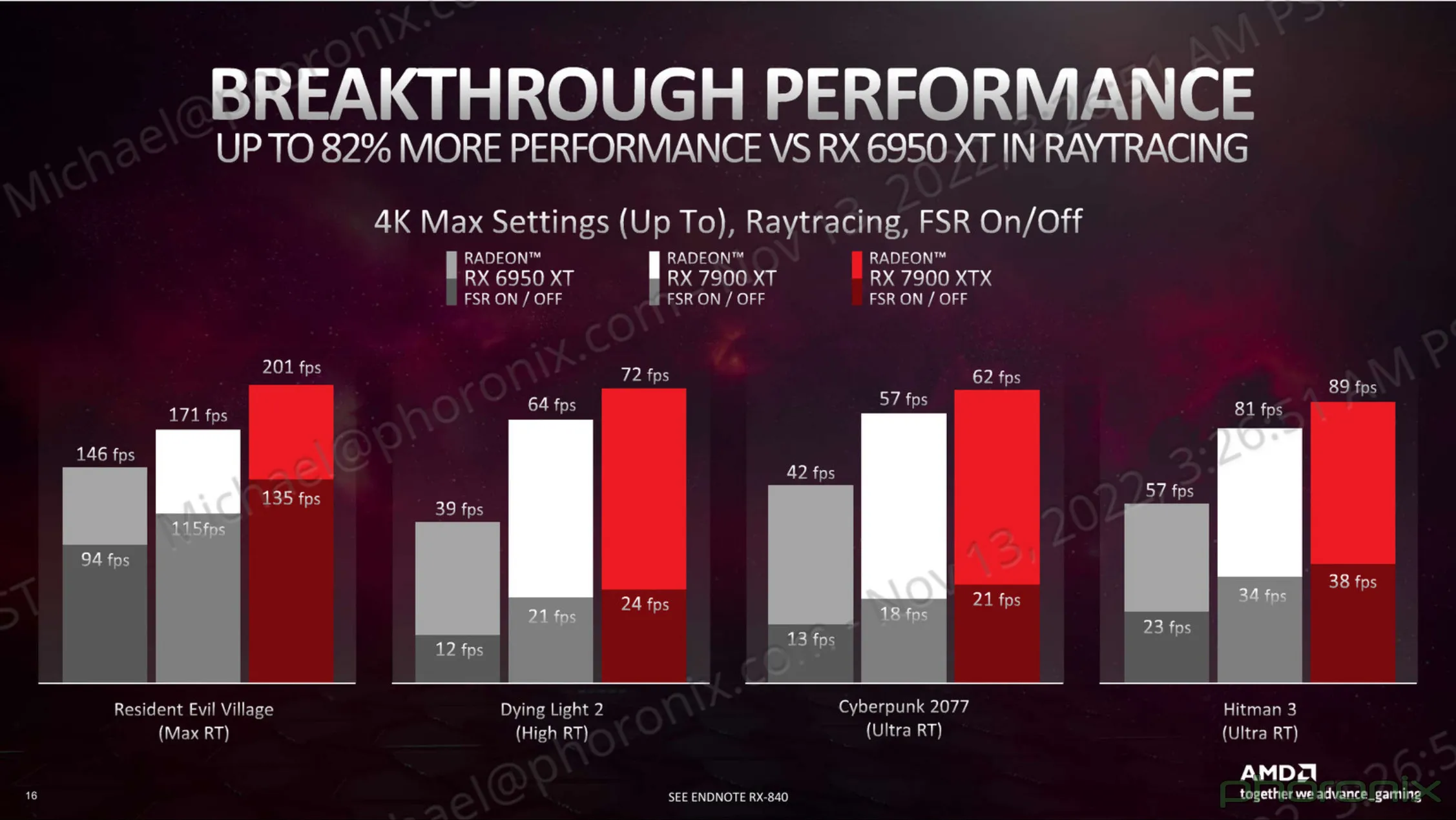

Just fool them with enough of RT and AI snakeoil
Im surprised the pc platform isnt dead yet, it should be and everyone on consoles seeing your comments still
")
Tbh and more serious, i think the death of pcgaming, the notion RT and AI are scams (nv), consoles and APU wishes deserve their own topic and have little to do in this RDNA3 specification discussion.
You may have valid points, its just undesirable seeing the same arguments repeated in every topic and discussion over and over again. I think most got idea now about your views and ideas regarding the things mentioned.
Last edited:
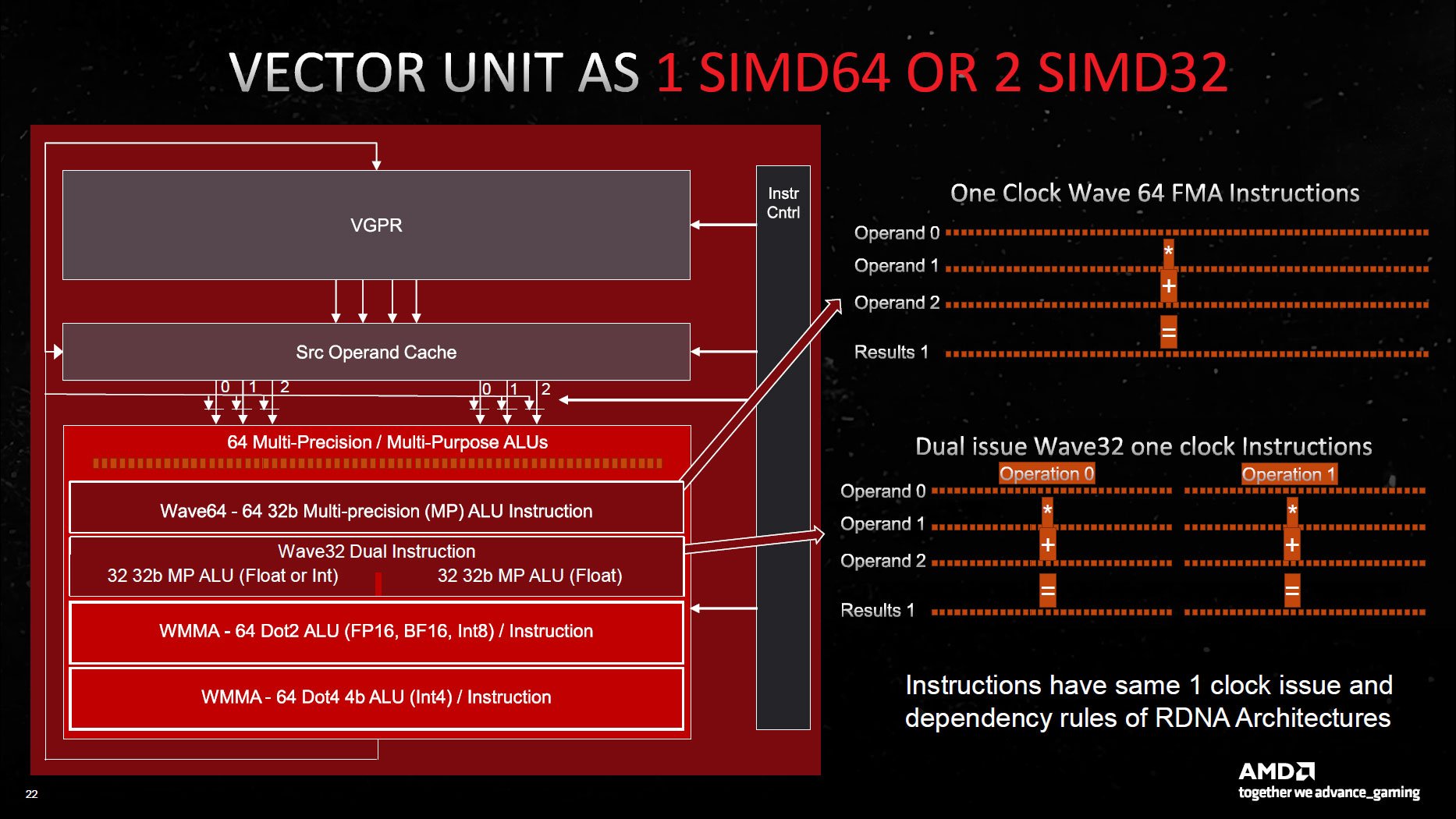
On the SIMDs, is there any idea here on how often it will dual issue ? I mean vaguely of course. I assume it's most of the time or it would hardly seem worth it.
Is wave32 the norm?
How can wave64 do any type of operation across all the ALUs, but in wave32 mode half the ALUs can do only floats?
What exactly is VOPD?
Is wave32 the norm?
How can wave64 do any type of operation across all the ALUs, but in wave32 mode half the ALUs can do only floats?
What exactly is VOPD?
Jawed
Legend
VOPD - see the speculation thread, there's nothing more to say, frankly.On the SIMDs, is there any idea here on how often it will dual issue ? I mean vaguely of course. I assume it's most of the time or it would hardly seem worth it.
Is wave32 the norm?
How can wave64 do any type of operation across all the ALUs, but in wave32 mode half the ALUs can do only floats?
What exactly is VOPD?
Pixel shaders seem likely to be wave64.
RDNA 2 seems to perform best with wave32 for ray tracing. Compute shader appears to have been the original motivation for AMD to introduce native 32-work item hardware threads in RDNA. It also seems to go well with vertex shading, as far as I can tell (which isn't much).
The asymmetric float/int + float thing across the 32 + 32 lanes is confirmed here:

which seems to marry up with Super-SIMD as I wrote about here:
AMD: RDNA 3 Speculation, Rumours and Discussion
Correct, in the current market AMD mostly exists as a pricing lever in the eyes of consumer population. So they're not gonna actively compete on price or try to push major GPU volumes etc. Consumers are so dim that a 6700xt can currently be had for $3xx on ebay. That's fantastic deal, Metro EE...
 forum.beyond3d.com
forum.beyond3d.com
Here we can see discussion of a side ALU and a full ALU, which aligns with the float/int + float arrangement. Notice this slide refers to the Compute Unit Pair and does not mention "Work Group Processor":
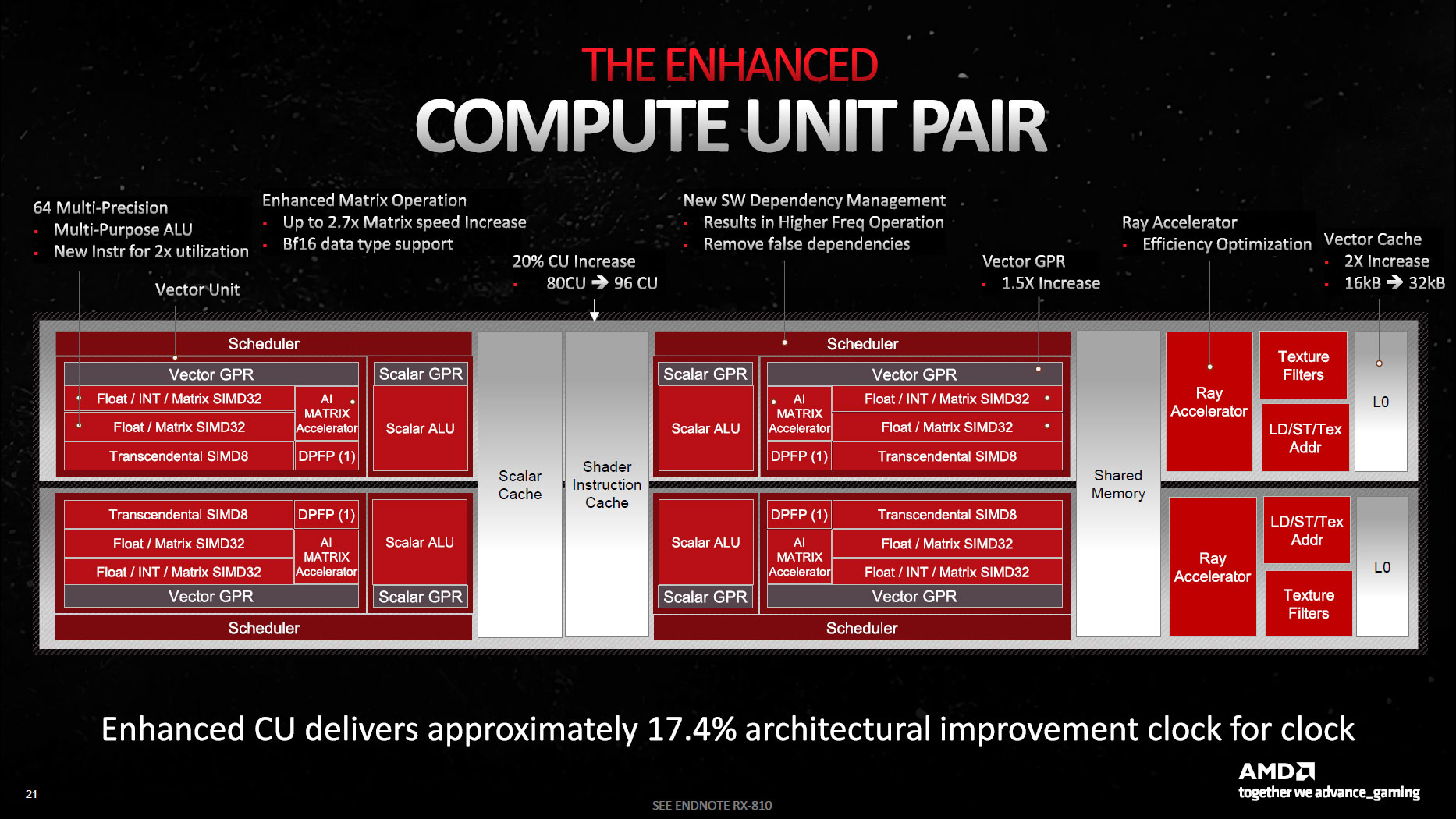
This slide makes me think that AMD is describing ALU functions as separate units, when in fact they are existing units that are repurposed. I think that's what "64 Multi-Precision" is describing as well as "Multi-Purpose ALU".
The slides look like a hurried mess and discussion doesn't seem to clarify much:
This is sort of funny because some places are saying that Navi 31 has 6,144 shaders, and others are saying 12,288 shaders, so I specifically asked AMD's Mike Mantor — the Chief GPU Architect and the main guy behind the RDNA 3 design — whether it was 6,144 or 12,288. He pulled out a calculator, punched in some numbers, and said, "Yeah, it should be 12,288." And yet, in some ways, it's not.
AMD's own slides in a different presentation (above) say 6,144 SPs and 96 CUs for the 7900 XTX, and 84 CUs with 5,376 SPs for the 7900 XT, so AMD is taking the approach of using the lower number. However, raw FP32 compute (and matrix compute) has doubled. Personally, it makes more sense to me to call it 128 SPs per CU rather than 64, and the overall design looks similar to Nvidia's Ampere and Ada Lovelace architectures. Those now have 128 FP32 CUDA cores per Streaming Multiprocessor (SM), but also 64 INT32 units.
In terms of "FLOPS", this does look like it's designed to achieve maximum floating point throughput whether in wave32 or wave64 modes, and when falling back to VOPD when co-issue from a wave32 hardware thread isn't available.
What is unclear is whether two independent hardware threads (2 separate wave32) can dual-issue. AMD has a history of misusing "dual-issue" so we'll have to wait to find out, I suppose.
That they haven't stated it can is probably an answer.VOPD - see the speculation thread, there's nothing more to say, frankly.
Pixel shaders seem likely to be wave64.
RDNA 2 seems to perform best with wave32 for ray tracing. Compute shader appears to have been the original motivation for AMD to introduce native 32-work item hardware threads in RDNA. It also seems to go well with vertex shading, as far as I can tell (which isn't much).
The asymmetric float/int + float thing across the 32 + 32 lanes is confirmed here:
which seems to marry up with Super-SIMD as I wrote about here:

AMD: RDNA 3 Speculation, Rumours and Discussion
Correct, in the current market AMD mostly exists as a pricing lever in the eyes of consumer population. So they're not gonna actively compete on price or try to push major GPU volumes etc. Consumers are so dim that a 6700xt can currently be had for $3xx on ebay. That's fantastic deal, Metro EE...
Here we can see discussion of a side ALU and a full ALU, which aligns with the float/int + float arrangement. Notice this slide refers to the Compute Unit Pair and does not mention "Work Group Processor":
This slide makes me think that AMD is describing ALU functions as separate units, when in fact they are existing units that are repurposed. I think that's what "64 Multi-Precision" is describing as well as "Multi-Purpose ALU".
The slides look like a hurried mess and discussion doesn't seem to clarify much:
In terms of "FLOPS", this does look like it's designed to achieve maximum floating point throughput whether in wave32 or wave64 modes, and when falling back to VOPD when co-issue from a wave32 hardware thread isn't available.
What is unclear is whether two independent hardware threads (2 separate wave32) can dual-issue. AMD has a history of misusing "dual-issue" so we'll have to wait to find out, I suppose.
Jawed
Legend
Yes, that's what I tend to think.That they haven't stated it can is probably an answer.
I wonder if their 17% CU improvement in IPC includes their expectation of 2xfp32 rates. Loosely aligns with the 40-50% perf increase they have shown in rasterized games.Yes, that's what I tend to think.
Jawed
Legend
I suspect you're right, but it wildly contradicts the "extract maximum value from each transistor" statement on that first slide I included.I wonder if their 17% CU improvement in IPC includes their expectation of 2xfp32 rates. Loosely aligns with the 40-50% perf increase they have shown in rasterized games.
Similar threads
- Replies
- 85
- Views
- 10K
- Replies
- 50
- Views
- 9K
- Replies
- 45
- Views
- 5K
- Replies
- 15
- Views
- 2K
- Replies
- 0
- Views
- 2K