Good point. DLSS would completely break with mods.
You are using an out of date browser. It may not display this or other websites correctly.
You should upgrade or use an alternative browser.
You should upgrade or use an alternative browser.
Nvidia DLSS 1 and 2 antialiasing discussion *spawn*
- Thread starter DavidGraham
- Start date
-
- Tags
- nvidia
That's not correct. DICE/4A only needs to provide the full solution to nvidia (textures, code, etc). How it's trained is fully determinant by nvidia - which to be honest, I'm unsure how nvidia trains the system. Training would not involve providing screen shots, the NN is not looking at the players position and extrapolating what image it has been trained on and trying to fill in the blanks. That would be an interpretation of what it's doing, but that's actually not what it's doing.That's assuming DICE/4A has provided all the source screens already. Keep in mind that ultrawide resolutions aren't even an option yet since DLSS needs to be trained on every single resolution separately and ultrawide hasn't been done. Whether it's in a queue at Nvidia or DICE hasn't provided non-standard resolutions yet, who knows.
And what happens when there's a significant change in rendering, enough to make the existing DLSS training obsolete and they need to provide ALL the resolution sources again to Nvidia for re-training.
Its trained material will enable it to apply to a variety of different resolutions, but how successful it will be on those resolutions is a matter of tweaking the output model, but not necessarily a matter of tweaking training data.
What makes deep learning different from other algorithms is its innate ability to adapt and select an answer on how both it's modelling and training. Depending on how complex the model is, ti will do so, and successfully even with things it has never seen. I wouldn't use these 2 cases as being definitive by any means. It's most certainly a different type of challenge than most image reconstruction experts have to face, the challenge of getting the processing time very low. But once again, not unlike something they've had to do for self driving cars for instance.
I'm okay with commentary that it sucks today. But for me, it's a matter of time when nvidia finds the right way to model and you're going to get a steep increase in performance very quickly.
How does ML performance change? That is, let's say it is taking 7ms per frame at the moment. How can that be sped up? Is there a minimum time but quality over that time can be increased?
If the model changes, yea, you can speed up the speed. We can do some really inefficient models with poor performance and some really effective models. Some ML algorithms are very fast with lots of attributes, some really slow with tons of attributes. etc. etc.How does ML performance change? That is, let's say it is taking 7ms per frame at the moment. How can that be sped up? Is there a minimum time but quality over that time can be increased?
So it really depends on how they want to build their model. It's quite a bit of work, and I suspect that the goal for any company to partake in this exercise is to do to the best of their ability, standardize the model for all games. Customization would get grossly expensive (outside of customizing their importing of data)
I'm thinking the training data looks like
- The models and respective textures of everything in the game (u,v) coordinates
- World/Level position data of each of those entities
- not sure if they would take lighting data, perhaps PBR values, but that sounds like more along DirectML and not what nvidia is doing.
You'd take 360 degree training of the models+textures in isolation, combine it with world/level (x,y,z) coordinate data.
Screen shots is an impossibility, just too many variations to ML off a world of screenshots.
I'm clueless how many models or what models they would run. But for me, DLSS is already impressive (lol honestly surprised how fast this was released), the question is really, how to get it up to better quality and better performance, because as a real time application this is what matters -- whereas with standard image reconstruction, time is a non issue.
Input features would be world position data for everything on the screen, camera position, screen buffer, motion vector.
Output would be the higher resolution picture.
Last edited:
Are better models dependent on more data? What size resources would something like this take (I appreciate that might be a broad answer!)? Reconstruction tends to work in megabytes for screen-res buffers. I envision ML datasets becoming huge, but I've no idea really!
Generally more data is better for NN. That would be a general statement.Are better models dependent on more data? What size resources would something like this take (I appreciate that might be a broad answer!)? Reconstruction tends to work in megabytes for screen-res buffers. I envision ML datasets becoming huge, but I've no idea really!
How the data is setup for training will matter more than the data itself and that can dramatically improve accuracy and be smaller in data footprint.
I also imagine that ML datasets for this type of exercise could be massive, but i've been heavily mistaken from time to time.
The neat thing about ML is that scientists can come up with novel methods for training/modelling that results in very good performance with less data, or is heavily transferrable, or is very quick etc.
One can't determine that until it's proven itself.
Since the faux 4k is noticeble i wouldnt mind a superconputer/tensor cores take care of it att less or no cost to performance.
Reconstruction on a 1.8TF PS4 to Spider-Man/HZD quality takes a few ms.
From what resolution are those 1.8TF base consoles reconstructing? Arent they just running 1080p, or something like that?
Always thought its the Pro thats dealing with faux resolutions to 4k.
I'm okay with commentary that it sucks today. But for me, it's a matter of time when nvidia finds the right way to model and you're going to get a steep increase in performance very quickly.
Its that what i mean, offcourse it sucks but aside from that the tech/idea seems to be forward thinking. Consoles with their limited tech could use a supercomputer for offloading. They might not have tensor cores but hopefully something similar, if they are needed.
D
Deleted member 2197
Guest
A high level explanation on how Nvidia does training. They do mention based on gamer feedback and screenshots they are adding different techniques and data pool is increasing. Wonder how long training takes on the Saturn V computer as it ranks 28th in TOP 500 worldwide in performance and most efficient.That's not correct. DICE/4A only needs to provide the full solution to nvidia (textures, code, etc). How it's trained is fully determinant by nvidia - which to be honest, I'm unsure how nvidia trains the system.
Picture below does decent job explaining dnn's in high level. There are many layers to work with features with increasing complexity and finally in the end output layer is produced.
There is a lot of choice on what kind of layers and precision to use for them. And devil is likely in details.
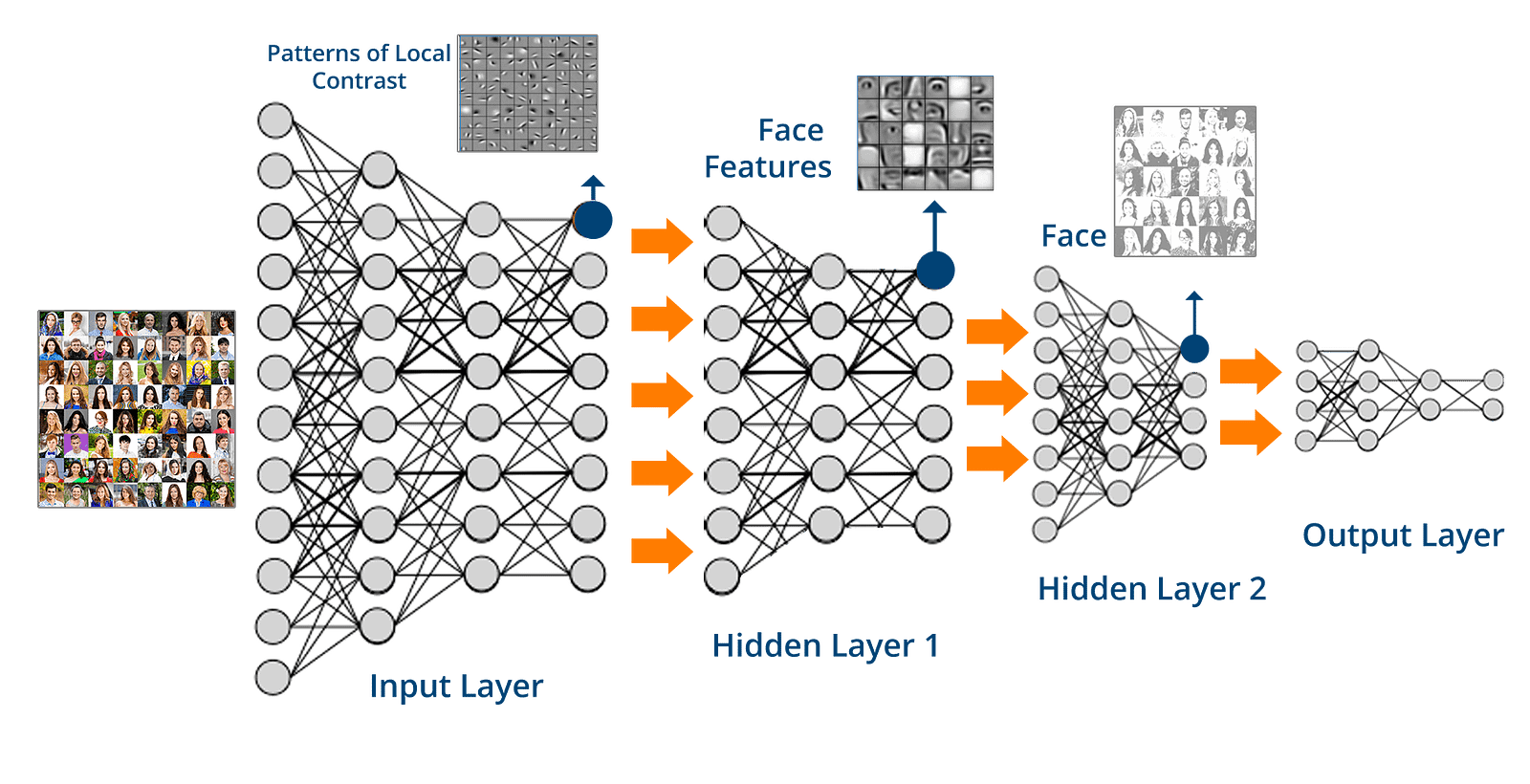
There is a lot of choice on what kind of layers and precision to use for them. And devil is likely in details.
Last edited:
ahhh I stand corrected then @MaloA high level explanation on how Nvidia does training. They do mention based on gamer feedback and screenshots they are adding different techniques and data pool is increasing. Wonder how long training takes on the Saturn V computer as it ranks 28th in TOP 500 worldwide in performance and most efficient.
I should have read the print on how DLSS works.
Wow that is incredibly not how I would do it. But I can see this as being one very standard way of doing it. They've trained an AI to actually just do upscaling and AA.
I suppose that's one way to do it. Certainly the cheapest way (in regards to data collection).
Upscaling just on image data would be the most straight-forward, drop in solution if it worked well. How does nVidia update the datasets? Are the driver downloads for DLSS including large data files?
indeed straight up most forward. I think I was in a completely different understanding of what they were trying to accomplish.Upscaling just on image data would be the most straight-forward, drop in solution if it worked well. How does nVidia update the datasets? Are the driver downloads for DLSS including large data files?
The driver would contain the new model for your turing card to run.
nvidia updates their own datasets and trains the model on their network.
You are given the trained model.
Well I believe you're right in that Nvidia are generating the screenshots rather than the developers, so the bottleneck on training is really purely on Nvidia once they have what they need from the game devs.ahhh I stand corrected then @Malo
The problem I have is you assumed DLSS would be better. Faux 4K is noticeable*, so you wanted a better solution. Well, DLSS's Faux 4K (it's just as fake as compute reconstruction) is also very noticeable; far more so. Why not wait and see what are the best solutions for upscaling instead of assuming DLSS was the perfect magic bullet? And why not discuss both technologies equally in terms of pros and cons instead of siding 100% with one for no particular reason?Since the faux 4k is noticeble i wouldnt mind a superconputer/tensor cores take care of it att less or no cost to performance.
Half 4K res in the case of HZD IIRC. We don't know how Insomniac's Temporal Injection works.From what resolution are those 1.8TF base consoles reconstructing?
Why? Why is using ML more forward thinking than using more sophisticated algorithms on compute using ever more local, deep data?Its that what i mean, offcourse it sucks but aside from that the tech/idea seems to be forward thinking.
There's no offloading. The supercomputer trains the model. The GPU then does a helluva lot of work implementing that model. Using ML to upscale is demanding (more demanding than compute at the moment). Ergo, we need to see where ML goes, and where reconstruction goes, and evaluate the different solutions neutrally to ascertain the best options for devs and gamers alike.Consoles with their limited tech could use a supercomputer for offloading.
* There really aren't a lot of complaints from people playing games with good reconstruction though.
D
Deleted member 2197
Guest
The DLSS model updates are part of Geforce Experience, so updates would either be through a driver download or updated directly to GFE from the internet.
yeaWell I believe you're right in that Nvidia are generating the screenshots rather than the developers, so the bottleneck on training is really purely on Nvidia once they have what they need from the game devs.
") thanks for saving my face
thanks for saving my facenvidia's answer:Are better models dependent on more data? What size resources would something like this take (I appreciate that might be a broad answer!)? Reconstruction tends to work in megabytes for screen-res buffers. I envision ML datasets becoming huge, but I've no idea really!
We have seen the screenshots and are listening to the community’s feedback about DLSS at lower resolutions, and are focusing on it as a top priority. We are adding more training data and some new techniques to improve quality, and will continue to train the deep neural network so that it improves over time.
So, yea, more or less more training examples and perhaps some improvements to the algorithms.
D
Deleted member 2197
Guest
Based on previous interview with FFXV Dev, the time for DLSS implementation varies according to game engine.
https://wccftech.com/ffxv-nvidia-dlss-substantial-fps-boost/The implementation of NVIDIA DLSS was pretty simple. DLSS library is well polished so, with DLSS, we were able to reach a functional state within a week or so, whereas it could take months if we implemented TAA on our own. The velocity map and how it’s generated differ depending on each game engine. In order to support that aspect and to keep pixel jitter under control, we needed to modify parameters.
D
Deleted member 2197
Guest
I think you might be correct regarding how the process is currently implemented, though in another Q&A they did mention developers would be providing Nvidia data.Well I believe you're right in that Nvidia are generating the screenshots rather than the developers, so the bottleneck on training is really purely on Nvidia once they have what they need from the game devs.
https://news.developer.nvidia.com/dlss-what-does-it-mean-for-game-developers/Question: How much work will a developer have to do to continue to train and improve the performance of DLSS in a game?
At this time, in order to use DLSS to its full potential, developers need to provide data to NVIDIA to continue to train the DLSS model. The process is fairly straightforward with NVIDIA handling the heavy lifting via its Saturn V supercomputing cluster.
Similar threads
- Replies
- 200
- Views
- 8K
- Replies
- 640
- Views
- 76K
- Replies
- 590
- Views
- 76K
D
- Replies
- 0
- Views
- 2K
- Replies
- 243
- Views
- 34K