
other than amd or nvidia - which gpu vendor can supply the durango gpu ? ( powervr ?)
It's using an APU, it's obviously AMD.
other than amd or nvidia - which gpu vendor can supply the durango gpu ? ( powervr ?)
It's using an APU, it's obviously AMD.
other than amd or nvidia - which gpu vendor can supply the durango gpu ? ( powervr ?)
Indeed I wish we would have seen those rumored dual FMA unitsCPU leak is boring/depressing in lack of any special customizations, but it does give a couple interesting numbers.

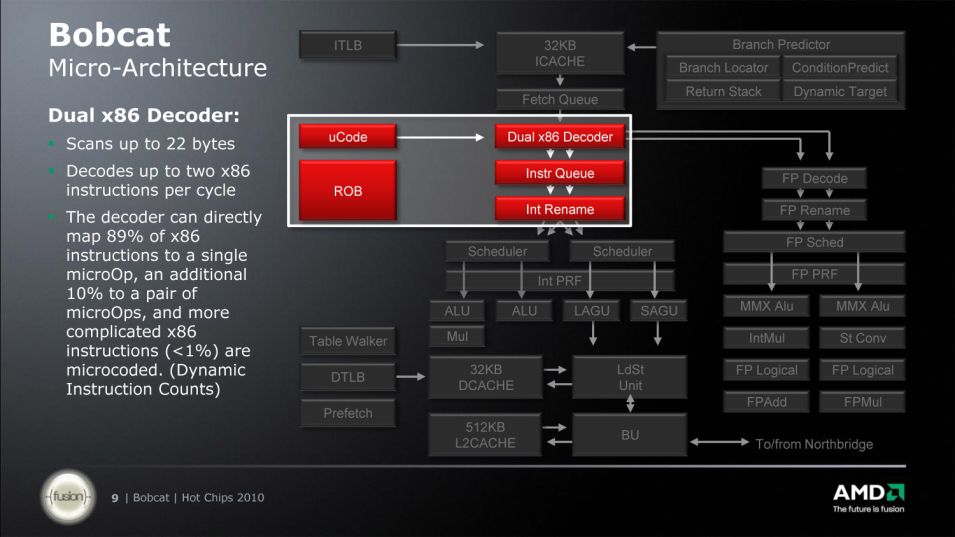
You are right. Who knows for what instruction mix this number comes from. If we take Bobcat as a base, we got this:This claim really surprised me: "On average, an x86 instruction is converted to 1.7 micro-operations" This is very far off from any data I've seen before, which was more like < 1.2 uops/instruction and for a uarch that had worse uops than Jaguar. I'm sure this number came from somewhere but I wonder if it was really for normal code.
I hear that the name of the document is, "Graphics on Durango"
Edit: Maybe they just took a list of all supported instructions and calculated the average, irrespective of how often they are used in usual code.
I think they named it originally macro-ops. Bobcat/Jaguar use them, too. The "fused" macro-ops for instructions with memory operands for instance are split up later in the pipeline. I guess they just named the macro-ops now µops in that diagram because that is what the decoders actually spit out.
Edit: got ninja'd
I think the Bobcat diagram is referring to uops that the output COPs are composed of, and if that's the case dynamic proportion is the only thing that makes really sense. They are calling them COPs in the papers, but good luck getting marketing slides to match engineering terminology.. If they're like the classic macro-ops they should be able to handle three uops for full RMW support (IIRC)Is there any indication how old this Durango document a lot you guys seem to have is?
FEB 2012.
Thanks. So with the VGleaks article we could assume their info is at least slightly more recent.
As we haven't heard of any more Durango developer meetings (where I think this document originates) we have to assume for now little/nothing has changed spec wise.
Yeah, I have seen the doc and to be honest, vgleaks info goes into alot more details than what is in the doc. The only new thing in the doc is that there is a page that compares the raw specs of the 360 and the durango. Funny thing is, according to the spec comparison, although the Xenos has 22.4gb/s to the RAM it seems that typically the gpu only has 16gb/s of bandwidth to itself. That's really about the most interesting new info there, alongside other raw spec comparison.
Is difficult to understand these specs and 7970 in the alpha kits.