Apparently, the new DLSS version doesn't require per game training and instead uses a general purpose algorithm, that can be updated across the board for all DLSS titles without the involvement of developers, it also doesn't put restrictions on resolution, as it works on ALL resolutions, it doesn't also restrict DLSS use to certain RTX GPU models, and most importantly provides a much much larger performance boost.
HardwareUnboxed who previously called DLSS dead, are now extremely impressed with the new DLSS model.
This means that they've changed strategy, but I have a feeling that NVIDIA:s answers aren't completely truthful.
(Note, these aren't perfect quotes and I've shortened some, just watch the videos at the timestamps)
11:37
Why NVIDIA felt like going back to AI? They reached the limits of the shader version, and with tensors they have better image quality, handling of motion, supports all resolutions etc. Implementation in control required hand tuning and didn't work well in other games.
24:47
NVIDIA says it's not their plan to have a shader version as well for other cards. It doesn't work well in other games.
27:45
Initial implementations were ”more difficult than expected” and “quality was not where we wanted it to be”. Decided to focus on improving it rather than adding it to more games.
The reason being it seeming like they're using parts of the algorithm in Control as a baseline, then use AI with tensors to make it a bit cleaner.
Why I'm saying such a controversial statement is because:
a) NVIDIA said so themselves in the blog about Control:
“With further optimization, we believe AI will clean up the remaining artifacts in the image processing algorithm while keeping FPS high.”
b) The algorithm in Youngblood produces the exact same artifacts that their Control algorithm produces when it comes to the sparks and embers, something NVIDIA highlights/shows that their slower AI research algorithm doesn't do.
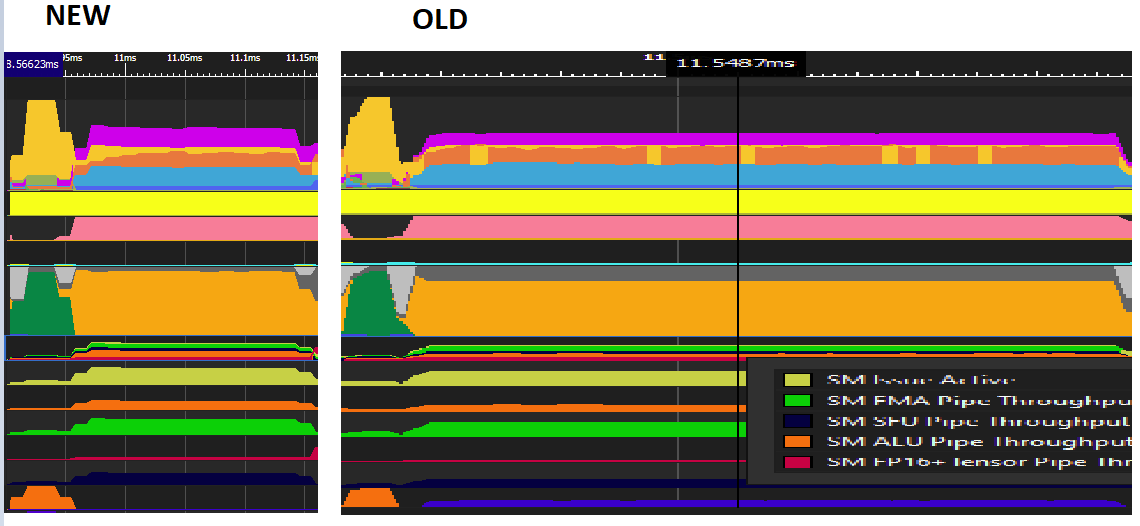
c) These parts look a bit similar. I've stretched out one so the timescales are roughly the same, just to make things a bit clearer. (The frame captures are from dorf earlier in this thread).
The left part is the new algorithm, that lasts a lot shorter than the old one in Control (right). It also appears sooner than the one in Control, which would make sense given what was said in a). I also noticed right now, this might be what their new GDC talk mentions:
"DLSS, deep learning based reconstruction algorithm, achieves better image quality with less input samples than traditional techniques."
Hopefully we'll get some answers during NVIDIA:s talk.
Their explanation as to why they have DLSS only for RTX cards is that they must use the tensor cores.
Yet when they were doing ray tracing, they had no problem whatsoever to show that RT was possible run on slower cards with no RT cores, except with many times lower performance.
They have a full shader based implementation in Control, yet they won't let you run it on 1600 series cards. Isn't that peculiar? Wouldn't they want to show that RTX is far, far superior to GTX as they did with ray tracing? They would just need to enable it on 1600 series and the performance would be many, many times worse, right? Well, we know that adding the 1600 series to Control would show that the tensor cores wouldn't be adding anything in that situation. They obviously would execute faster for the new version, we just don't know how much faster.
Besides, even if they really wanted to prove that the new version is much faster on RTX, they could use DirectML to create a general version. AMD actually supports DirectML upscaling on everything newer than Vega. During Siggraph 2018 Microsoft actually presented a DirectML super-resolution model that was developed by NVIDIA.
"This particular super-resolution model was developed by NVIDIA.". I find it very unfortunate that NVIDIA has had multiple opportunities to show how much better RTX is, and yet fail to show it.
As for me, I think the main problem today is that ML and rendering don't seem to be executed in parallel. If we look at games, if you had for example a 4k image taking 16ms to render, then rendering it at 8ms from a lower resolution, and then upscaling with ML in 8ms, would end up being the same thing if done sequentially. However, if we were to render frame1, then upscale frame1 at the same time as we render frame 2, we'd be doubling the frame rate. Now it goes from "meh" to "amazing". Of course, the architecture needs to allow such execution.

")