http://www.beyond3d.com/articles/xenos/index.php?p=08
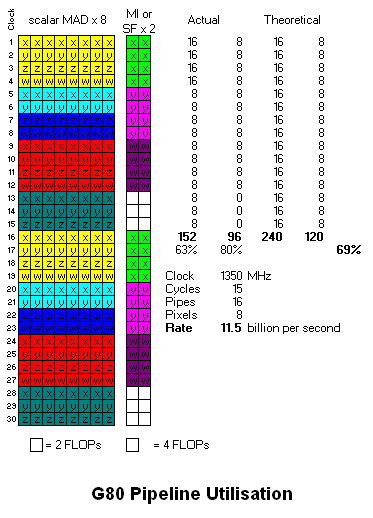
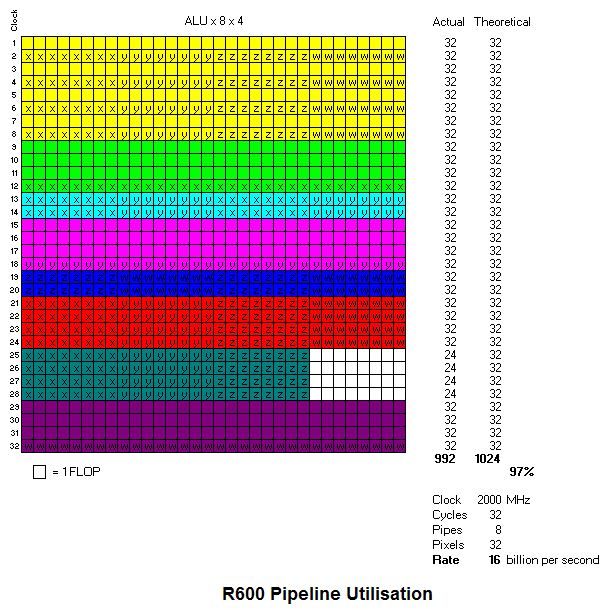
See Jawed your diagram doesn't take the threading into account. Look at the rather large discrepancy between your tests and ATI's.
This is in fact the basis of my claim that scalar is not necessarily better then vec4 because it all depends on the implementation. I think R580 has brute force, but is far from using ALU's efficiently.
The Xenos shader contains a large number of independent groups of pixels and vertices (threads) which are 16 wide. In order to hide the latency of an instruction for a given thread, a number of other threads are used to "fill in the gaps". By doing this, the ALU's are fully utilized all the time, and the shader can have direct data dependency on every instruction and still run full rate. Xenos has a very large number of these independent threads ready to process, so there are always enough independent instructions to execute such that the ALU's are fully utilized. Each of these different threads can be executing a different shader, can be at different places within the same shader, can be pixels or vertices, etc.
With this complex organisation, the threading mechanisms, the number of threads that are active, or ready to be active so the system hides latency effectively, ATI's testing indicates an average of about 95% efficiency over the shader array in general purpose graphics usage conditions
See Jawed your diagram doesn't take the threading into account. Look at the rather large discrepancy between your tests and ATI's.
This is in fact the basis of my claim that scalar is not necessarily better then vec4 because it all depends on the implementation. I think R580 has brute force, but is far from using ALU's efficiently.
Last edited by a moderator:
") ).
).