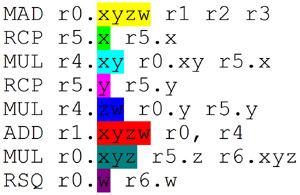
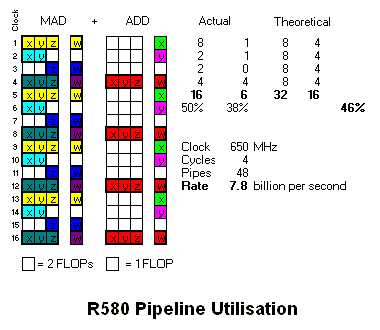
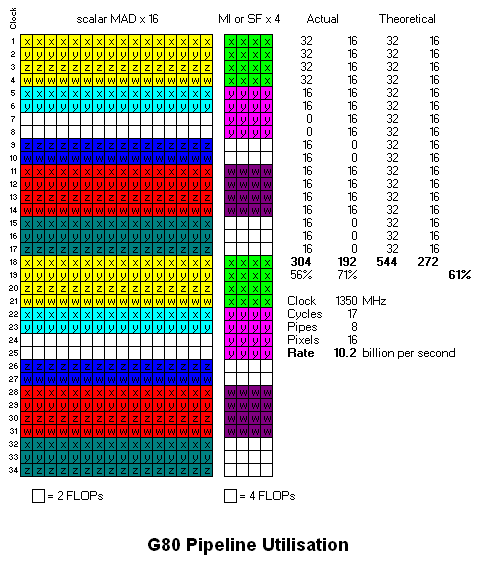
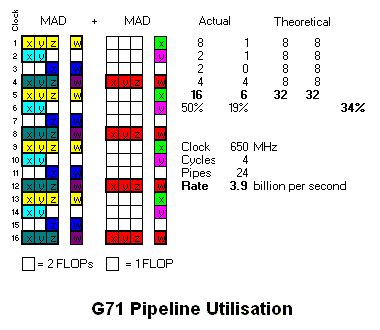
Pigman BABY!!!
Newcomer
How many shader operations can the G80 do per unified shader ALU?
I know the Xenos can do 10 x 48ALU's x 500MHz = 240GFlop/s
Taking in account the G80 does 10 aswell that gives it:
10 x 128 ALU's x 1350MHz = 1728GFlop/s (1,728TFlop/s)
This would mean it's a very big leap up from the G7x and R580 something which isn't as much shown by games.
Why is that?
I know the Xenos can do 10 x 48ALU's x 500MHz = 240GFlop/s
Taking in account the G80 does 10 aswell that gives it:
10 x 128 ALU's x 1350MHz = 1728GFlop/s (1,728TFlop/s)
This would mean it's a very big leap up from the G7x and R580 something which isn't as much shown by games.
Why is that?
")