Why did you assume otherwise? I can't recall the SF/Interpolator patent in detail but I don't remember anything indicating a scheduling dependency on ALU ops.
It's just another "ALU". Also, to be multi-threaded it requires another load of distinct scheduling/arbitration hardware to be dedicated to it. Finally, for a while it was supposed to be the home of the missing MUL (maybe it still is, past caring). Oh, and of course, Bob said I had a dependency clash, which can't happen if they're multi-threaded...
I'm not saying it's impossible, just that it seems costly and not my first-choice assumption.
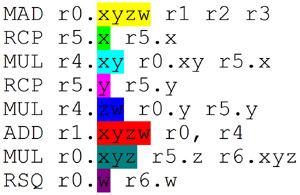
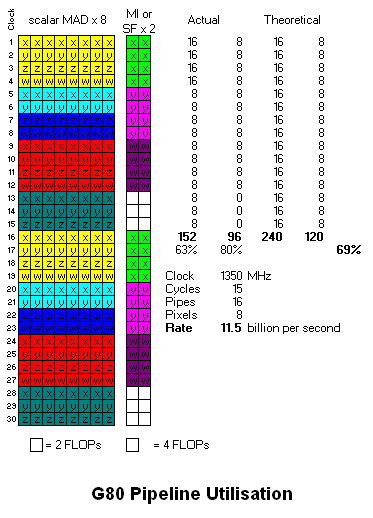
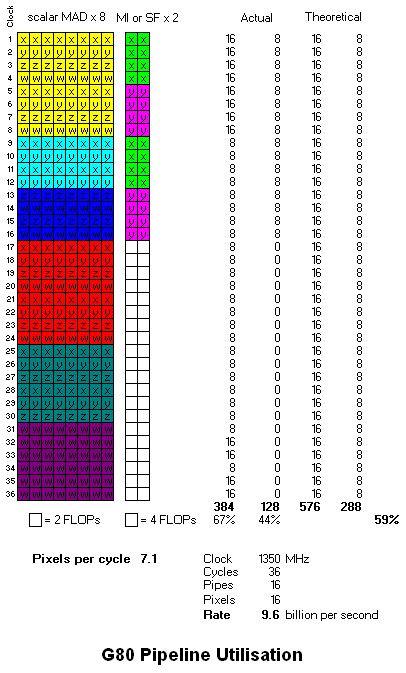
In the meantime, I've thought of a different way to schedule G80:
Here I have "doubled-up" the scheduling of pixels in a batch. I should quadruple-up the pixels in a batch, because that's how it actually executes. But that would make the diagram nearly twice as long, and wouldn't make any difference to the solution I've found for this code sample. If the code sample had a MAD-pipeline scalar instruction, then that might have necessitated the quadrupled-up diagram.
This solution doesn't require multi-threaded MAD and SF units, because what I've shown all comes from a single thread (batch).
So, as far as I can see, by ordering instruction-issue by program counter within a batch (not by pixel) it's possible for G80's compiler to maximise MAD utilisation - whether pixel or vertex or geometry shader - i.e. whether 32 or 16 object batches are issued. This seems like a pretty compelling solution to me. I think it's still possible for holes to appear in the MAD unit, if there's too many SF (or MI) instructions in the dependency chain.
(Grouping by PC is how I solved the scheduling in R600 - but it took a while for me to transfer the concept to G80

)
Jawed