Would it be possible for AMD to add a separate die for 128 MB eDRAM L4 cache similar to Intel Crystalwell? Intel Crystalwell is only used with 2-channel memory controllers. Would it be hard to scale this kind of cache design to support bandwidth required for 4/6/8-channel memory controller? An additional die would of course add cost, but we are talking about 1000$+ EPYC CPUs, not consumer products. They already have 4 CPU dies.
Install the app
How to install the app on iOS
Follow along with the video below to see how to install our site as a web app on your home screen.
Note: This feature may not be available in some browsers.
You are using an out of date browser. It may not display this or other websites correctly.
You should upgrade or use an alternative browser.
You should upgrade or use an alternative browser.
Crystalwell would be the L4 variant, which put it in the cache coherence hierarchy. For EPYC, it might exceed the probe filter/directory's ability to track lines. Earlier versions of Hypertransport assist could not fully cover a whole 8-socket system if all caches hit the same home node. EPYC doubtless has increased the capacity to more closely match the capacity of the L2 and L3 caches for a total of 8 dies in a system, but a coherent EDRAM die could easily exceed the total capacity of all caches in the system--and only if one were present system-wide.
The Skylake version where the EDRAM is memory-side would avoid this, since it would transparently sit in between a memory request and an actual DRAM access at the home node, but other than maybe halving DRAM latency for a hit, AMD's CCX, package, and socket latencies would be unchanged. Bandwidth-wise, I suppose it would be counting on an improvement to interposer or fan-out packaging like Nvidia and Intel are planning on. Otherwise, the chips lack the pads, bandwidth, or power efficiency to do better than what they have currently for within a socket, much less 2P.
Something would need to be done for the data fabric on-chip as well. Part of Zen's philosophy of "balance" which pervades everything is that the low, sustained, and best-case are rather close. The on-die fabric as we know it would scale a crossbar whose complexity and delivery either matches everything or will strangle the EDRAM.
The Skylake version where the EDRAM is memory-side would avoid this, since it would transparently sit in between a memory request and an actual DRAM access at the home node, but other than maybe halving DRAM latency for a hit, AMD's CCX, package, and socket latencies would be unchanged. Bandwidth-wise, I suppose it would be counting on an improvement to interposer or fan-out packaging like Nvidia and Intel are planning on. Otherwise, the chips lack the pads, bandwidth, or power efficiency to do better than what they have currently for within a socket, much less 2P.
Something would need to be done for the data fabric on-chip as well. Part of Zen's philosophy of "balance" which pervades everything is that the low, sustained, and best-case are rather close. The on-die fabric as we know it would scale a crossbar whose complexity and delivery either matches everything or will strangle the EDRAM.
One presentation stuck out more than the rest. Intel presented a deck that outlined what it considers to be its advantages against AMD’s EPYC CPUs. The slides generated a lot of controversy over the last week, but they haven't been presented in context
http://www.tomshardware.com/reviews/intel-amd-die-fabric-slides,5125.html
So Apparently it was all out fault because we stupid mortal took Intel presentation out of context.
Can someone with knowledge explain me in which context I can say that AMD CPUs are "glue together" my brain can't figure out one.
digitalwanderer
Legend
Sorry mate, you misspelled that last bit. Fixed it for ya.Tom's serving Intel as some kind of sycophant.
")
Zen's split-cache design is a more server centric design than Intel's desktop-server balanced design. AMD performs best in NUMA aware server workloads. Intel's architecture is a slightly bit better fit for desktops (including gaming). AMD basically re-purposed their server chip to desktop and kept all the server features enabled. Intel on the other hand disables features from consumer products, even when they exist in the hardware. The vendor lock-in slides are telling the same story. Intel not compatible with open standards supported by AMD = good, AMD not compatible with Intel's proprietary patented tech = bad.
The most funny thing about these slides is that Intel tries to spin their market segmentation to be a positive thing for their customers. They are practically admitting that they are milking their customers money and brag about it in their slides. These slides have some valid points, but most of Intel's arguments are actually bad for Intel customers instead of the other way around. The lack of optimization slides are a prime example of bad marketing. EPYC is already beating Intel in the Anandtech benchmarks, and Intel is openly admitting that AMD does this with software that isn't yet optimized for their architecture. The direct conclusion is that EPYC will be even better in the future. Is this what Intel wants to tell their customers?
The most funny thing about these slides is that Intel tries to spin their market segmentation to be a positive thing for their customers. They are practically admitting that they are milking their customers money and brag about it in their slides. These slides have some valid points, but most of Intel's arguments are actually bad for Intel customers instead of the other way around. The lack of optimization slides are a prime example of bad marketing. EPYC is already beating Intel in the Anandtech benchmarks, and Intel is openly admitting that AMD does this with software that isn't yet optimized for their architecture. The direct conclusion is that EPYC will be even better in the future. Is this what Intel wants to tell their customers?
in which context I can say that AMD CPUs are "glue together" my brain can't figure out one.

You are just a stupid mortal. This is the right context.

P.S.: Make a sacrifice in my name.
When I saw the desktop glued together chips statement across the net last week, I thought that's not so bad, a lot of noise over that. Up to AMD to show why it's not, or why it's a better design.
When I looked through the slides though, boy do they go for it, the glued together statement seemed to be the one I have the least issue with.
It's almost like they threw that in there on purpose, people focused on that and miss all the other stuff they put in there. Then come out, justify it, or say it's out of context and the rest kind of flies under the radar.
Do I think that's why they did it, no, but sure seems to have turned out like that.
When I looked through the slides though, boy do they go for it, the glued together statement seemed to be the one I have the least issue with.
It's almost like they threw that in there on purpose, people focused on that and miss all the other stuff they put in there. Then come out, justify it, or say it's out of context and the rest kind of flies under the radar.
Do I think that's why they did it, no, but sure seems to have turned out like that.
Intel is simply itched, that AMD would potentially undercut them by using a single die design for all SKU -- from mobile to enterprise solutions, while Intel have to reserve production overhead and QA for multiple sized layouts.
By the way, EPYC is glue-less design, since there's no "glue" (i.e. external bridge logic) linking the CPU clients together.
By the way, EPYC is glue-less design, since there's no "glue" (i.e. external bridge logic) linking the CPU clients together.
Anarchist4000
Veteran
The super budget chips could be an embedded design we haven't seen. Consumer grade NAS or switches with all the PCIE lanes. Similar to the low core Epycs.To add to that, the yields on those Zeppelin dies must be ridiculous. They can essentially pick and choose what product to release, the fact there's no super budget 2 core Ryzen CPU with 3 cores disabled in the CCX is also telling.
Yes the flexibility it gives AMD(and anyone with this kind of design). If a core in a die is bad you can use it on another SKU in ur entire line up rather than being force to sell that die disabling another core for consistency,To add to that, the yields on those Zeppelin dies must be ridiculous. They can essentially pick and choose what product to release, the fact there's no super budget 2 core Ryzen CPU with 3 cores disabled in the CCX is also telling.
"Barclays predicts shares of AMD, one of the market's hottest stocks, will plunge 35%" ... "Curtis cited how Intel's server chips have "faster max clock speeds," which outperform AMD's offering in a wider array of applications. In addition, Intel's server chips have quicker connections to the computer's memory, according to the analyst."
http://www.cnbc.com/2017/07/18/barclays-predicts-shares-of-amd-will-plunge-35-percent.html
I think they took Intel's slide too seriously. OR maybe they took them out of context. OR maybe we are taking them out of context.
http://www.cnbc.com/2017/07/18/barclays-predicts-shares-of-amd-will-plunge-35-percent.html
I think they took Intel's slide too seriously. OR maybe they took them out of context. OR maybe we are taking them out of context.
Were the presentations targeted to customers or consumers, or investors and analysts? The latter class would absolutely love Intel strip-mining their captive customers for profit.The most funny thing about these slides is that Intel tries to spin their market segmentation to be a positive thing for their customers. They are practically admitting that they are milking their customers money and brag about it in their slides.
tongue_of_colicab
Veteran
"Barclays predicts shares of AMD, one of the market's hottest stocks, will plunge 35%" ... "Curtis cited how Intel's server chips have "faster max clock speeds," which outperform AMD's offering in a wider array of applications. In addition, Intel's server chips have quicker connections to the computer's memory, according to the analyst."
http://www.cnbc.com/2017/07/18/barclays-predicts-shares-of-amd-will-plunge-35-percent.html
I think they took Intel's slide too seriously. OR maybe they took them out of context. OR maybe we are taking them out of context.
Or maybe they just don't have a fucking clue. It's not like those kind of people are out for anything other than lining their own pockets.
They dont having "a fucking clue" its the same thing as they beliving Intel's BS marketing slides.Or maybe they just don't have a fucking clue. It's not like those kind of people are out for anything other than lining their own pockets.
Barclays apparently has 51 million worth of AMD stock options or some such due this Friday, so they need to get the stock down as much as possible to prevent loss
(I have no clue how this stuff actually works, just reporting what I heard from a fellow)
edit:
So if I got it right, if they get the stock price down, they can still sell their options at the predetermined value, make crapload of money and buy more stock at cheaper price
(I have no clue how this stuff actually works, just reporting what I heard from a fellow)
edit:
So if I got it right, if they get the stock price down, they can still sell their options at the predetermined value, make crapload of money and buy more stock at cheaper price
Last edited:
Ryzen CPU game comparison with different ram speeds: https://www.computerbase.de/2017-07/core-i-ryzen-ddr4-ram-benchmark/
Looks very competitive here:
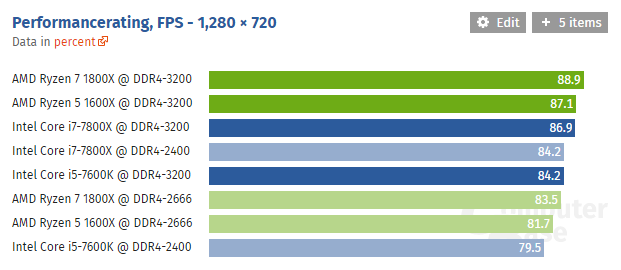
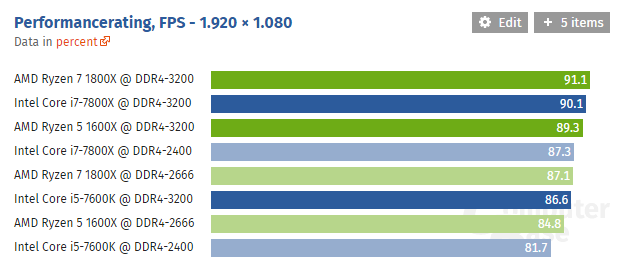
Looks very competitive here:
I can't read german and translator isn't working well with the page but why are the other intel CPUs excluded unless you press the button on the graph to include them?Ryzen CPU game comparison with different ram speeds: https://www.computerbase.de/2017-07/core-i-ryzen-ddr4-ram-benchmark/
I can't read german and translator isn't working well with the page but why are the other intel CPUs excluded unless you press the button on the graph to include them?
Maybe because they only tested ram differences for these CPUs and they only had tests done previously for the other setups?
Similar threads
- Replies
- 85
- Views
- 18K
- Replies
- 90
- Views
- 18K
- Replies
- 220
- Views
- 94K