Install the app
How to install the app on iOS
Follow along with the video below to see how to install our site as a web app on your home screen.
Note: This feature may not be available in some browsers.
You are using an out of date browser. It may not display this or other websites correctly.
You should upgrade or use an alternative browser.
You should upgrade or use an alternative browser.
- Status
- Not open for further replies.
DegustatoR
Legend
Where does it say that it's using "the same hardware"? Using the same SIMD isn't the same as "using the same h/w". FP64 math still runs on dedicated ALUs, which is also why GCN has variable FP64 rates between it's versions. Also I believe that RDNA has a separate 2-lane FP64 unit inside each WGP? Not sure on the details.Using the same hardware as for FP32 and all other formats.

This is a surprisingly difficult thing to find good data on, but the best I could do is here:Where does it say that it's using "the same hardware"? Using the same SIMD isn't the same as "using the same h/w". FP64 math still runs on dedicated ALUs, which is also why GCN has variable FP64 rates between it's versions. Also I believe that RDNA has a separate 2-lane FP64 unit inside each WGP? Not sure on the details.

Difference Between AMD RDNA vs GCN GPU Architectures | Page 2 of 2 | Hardware Times
With the launch of the Big Navi graphics cards, AMD has finally returned to the high-end GPU space with a bang. While the RDNA 2 design is largely similar to RDNA 1 in terms of the compute and graphics pipelines, there are some changes that have allowed the inclusion of the Infinity Cache and the …
 www.hardwaretimes.com
www.hardwaretimes.com
Looks like the ratio of FP32 : FP64 : Transcendental is 32:2:8 with dedicated blocks for each if I'm interpreting it correctly, at least for RDNA1.
Attachments
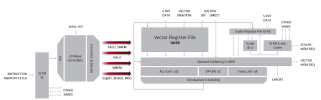

So there's no way for a 32-bit ALU to do a 64-bit operation over multiple cycles and using multiple register banks?
I assume in the old VLIW days, the individual ALUs in a SIMD could work together to do it? That was always the impression I got with this.
View attachment 6758
It's the same hardware, has always been.Where does it say that it's using "the same hardware"? Using the same SIMD isn't the same as "using the same h/w". FP64 math still runs on dedicated ALUs, which is also why GCN has variable FP64 rates between it's versions. Also I believe that RDNA has a separate 2-lane FP64 unit inside each WGP? Not sure on the details.
That's exactly what they're doing to my understanding.So there's no way for a 32-bit ALU to do a 64-bit operation over multiple cycles and using multiple register banks?
I assume in the old VLIW days, the individual ALUs in a SIMD could work together to do it? That was always the impression I got with this.
View attachment 6758
For larger 64-bit (or double precision) FP data, adjacent registers are combined to hold a full wavefront of data.
DegustatoR
Legend
As far as I know it's not and has never been "the same hardware". How do you explain the differences in FP64 rates to FP32 on GCN if "it's the same hardware"?It's the same hardware, has always been.
As far as I know it's not and has never been "the same hardware". How do you explain the differences in FP64 rates to FP32 on GCN if "it's the same hardware"?
There's a difference between using 2x 32-bit registers bonded together as inputs and outputs with dedicated and separate 64-bit ALU which seems to be what RDNA1/2 are doing, versus reusing the actual ALUs the way VLIW4/5 did: https://www.anandtech.com/show/4061/amds-radeon-hd-6970-radeon-hd-6950/4
AMD's RDNA whitepaper does a pretty good job of explaining all this on pages 8-14: https://www.amd.com/system/files/documents/rdna-whitepaper.pdf
"The SIMDs use separate execution units for double-precision data. Each implementation includes between two and sixteen double-precision pipelines that can perform FMAs and other FP operations, depending on the target market. As a result, the latency of double-precision wavefronts varies from as little as two cycles up to sixteen. The double-precision execution units operate separately from the main vector ALUs and can overlap execution."
They're not removing any FP64 ALUs. The existing ratio is 16:1, they're doubling the FP32 ALUs, and the resulting ratio will be 32:1, i.e. the same number of FP64 ALUs will remain per WGPIf the article that was previously posted is correct, then AMD will be further reducing FP64 performance with RDNA 3. That should lead to some transistor savings correct? That would, of course, then be used for other things.
Regards,
SB
And why would every GPU not have a 2:1 ratio if it were free?As far as I know it's not and has never been "the same hardware". How do you explain the differences in FP64 rates to FP32 on GCN if "it's the same hardware"?
And why would every GPU not have a 2:1 ratio if it were free?
Well, even if the capability is there in hardware, there's almost always product segmentation shenanigans going on with FP64.
See Radeon VII: https://www.anandtech.com/show/13923/the-amd-radeon-vii-review/3
Or GK110: https://www.anandtech.com/show/7492/the-geforce-gtx-780-ti-review
And why would every GPU not have a 2:1 ratio if it were free?
As mentioned above, to arbitrarily control it by forcing FP64 operations to go to dedicated units.
Do games (graphics or compute workloads) ever need it? Or it's strictly for non-gaming applications? Do the consoles have dedicated FP64 units?
I'm not talking product segmentation though, I'm talking where it's not available in hardware, even for cards ostensibly destined for use in a data centre. Vega 10, Polaris 10, Fiji, Tonga, Tahiti, Pitcairn all ended up in DC cards, none feature half rate FP64 at the hardware level. For that matter, why waste the engineering time designing GCN to vary the rate from 1/2 to 1/16 if it's free? Likewise on the nvidia side, 102 and 104 cards end up in DCs, none feature half rate FP64.Well, even if the capability is there in hardware, there's almost always product segmentation shenanigans going on with FP64.
Product segmentation is already done by driver/firmware restrictions, they don't somehow laser off hundreds of FP64 SIMDs. You used to be able to flash consumer nvidia GPUs to professional ones with some PCB modding, though they've since fixed that 'loophole'As mentioned above, to arbitrarily control it by forcing FP64 operations to go to dedicated units.
Do games (graphics or compute workloads) ever need it? Or it's strictly for non-gaming applications? Do the consoles have dedicated FP64 units?
Last edited:
2:1 is not free. While it requires no additional register bandwidth (as it is identical), one has to put in bigger ALUs (capable of handling more bits).They're not removing any FP64 ALUs. The existing ratio is 16:1, they're doubling the FP32 ALUs, and the resulting ratio will be 32:1, i.e. the same number of FP64 ALUs will remain per WGP
And why would every GPU not have a 2:1 ratio if it were free?
2:1 costs you quite a bit of transistors (for instance, multipliers need to be able to handle a 54x27 bit multiplication and the adders need to be able to add two of such results), 4:1 only a moderate amount (one needs 27x27 bit multipliers, that's why the VLIW GPUs often had 4:1), and for 16:1 the effort is really small (one can do with the normal 24x24 bit multipliers required for FP32 anyway).
They were using the same hardware in the VLIW and GCN architectures (multi precision ALUs). They only switched over to separate FP64 ALUs with RDNA as far as I understand (that's probably the reason the RDNA whitepaper mentions it).As far as I know it's not and has never been "the same hardware". How do you explain the differences in FP64 rates to FP32 on GCN if "it's the same hardware"?
And how do you get different FP64 rates for multiprecision ALUs in different GPUs? One puts different ALUs in different chips. It can be that simple.
DegustatoR
Legend
GCN has variable FP64 rate to FP32 between versions.They were using the same hardware in the VLIW and GCN architectures (multi precision ALUs).
Hence it's not "using the same h/w".And how do you get different FP64 rates for multiprecision ALUs in different GPUs? One puts different ALUs in different chips. It can be that simple.
Yes, AMD build different versions of their multi precision vector ALUs and put them in different GPUs. But if you look at one of them (prior to RDNA) FP32 and FP64 was handled by the same hardware in the sense that the same ALUs were responsible for FP32 and FP64 (no separate FP64 ALUs as in RDNA GPUs).GCN has variable FP64 rate to FP32 between versions.
Hence it's not "using the same h/w".
4:1 only a moderate amount (one needs 27x27 bit multipliers, that's why the VLIW GPUs often had 4:1)
How did it work with VLIW? Was just one of the ALUs in a set fatter and capable of 64-bit?
I thought they somehow combined multiple ones to make it work, like how a RDNA 32-bit ALU can do 2X16.
How did it work with VLIW? Was just one of the ALUs in a set fatter and capable of 64-bit?
I thought they somehow combined multiple ones to make it work, like how a RDNA 32-bit ALU can do 2X16.
By combining. By the distributive property of multiplication:
Code:
(a+b) * (c+d) = a*c+a*d+b*c+b*dIf you are multiplying two 54-bit numbers, you can split each of them into 2 27-bit numbers. Remember, 64-bit floats have 53-bit mantissas, and 32-bit floats have 24-bit mantissas. So, to provide for 4:1 throughput with 64-bit requires you to increase the size of your multipliers by ~27%. (They grow as a square of their width.) This is not free, but is far from the massive increase in size that is needed to go up to 2:1.
Well, Ponte Vecchio gets away gluing 63 chips together (of which 47 are functional and 16 to spread thermal load better), so no too manyThat's a lot of chiplets to glue together.
- Status
- Not open for further replies.
Similar threads
- Replies
- 1K
- Views
- 179K
- Replies
- 15
- Views
- 2K
- Replies
- 7
- Views
- 2K
- Replies
- 85
- Views
- 10K