You are using an out of date browser. It may not display this or other websites correctly.
You should upgrade or use an alternative browser.
You should upgrade or use an alternative browser.
GPU Ray Tracing Performance Comparisons [2021-2022]
- Thread starter DavidGraham
- Start date

neckthrough
Regular
Understood. Good luck!Thanks, but no i won't show off to the public soon. Actually i work on necessary preprocessing tools, then i have to finalize LOD, and only after that i will start work on actual demo renderer. (Actually i only have debug visualization of surface probes.)
Goal is to sell it to games industry, and if that fails make some game myself using it.
D
Deleted member 2197
Guest
It will be interesting to see how any performance related differences hold up at 5nm, or if it will be a one-sided story.If we relate performance to Watts, it turns out AMD does better. I did not know power differences are that big currently and had ignored this, but Watt is no bad measure to compare, since TF makes no more sense after NV doubled FP units.
Which facts to ignore?Only if you ignore facts:
View attachment 5678
Are you saying a RTX 3090 pulls double the wattage of a 6900 XT?
If not...you need to redo your math about performanc per Watt as NVIDIA outdoes AMD by nealy 100% here.
This benchmark does not include power draw, and you don't even tell the workload / game it is about.
The Crytek Benchmark did include power draw. But the difference is no 2x.
However, i don't want to ignite another useless fanboy war. Even compute benchmarks are almost useless for me, i have to measure with my project to change my own, personal impression of AMD having still the edge, eventually.
Ofc. RTX is faster in a DXR game. I know this as any other does. It might be interesting to figure out how RT Cores help to reduce power draw, versus AMDs approach of offloading RT work to CUs.
But not to me. At this point, API restrictions is all i'm concerned about. Neither performance nor power draw of monster GPUs.
Which was clear already when the debatte has started.After all the debating, were still at the point where HW rt is faster than software.
The point was: Software RT starts with smaller achievement due to performance, but may progress faster in the long run because no restrictions or conventions which turn out bad.
And sadly, this point now is relevant, as EU5 shows. Already now, only 3 years later.
We have a problem, and we should fix it. Ignoring the problem does help as much as pointing out an obvious fixed function performance advantage.
Which facts to ignore?
This benchmark does not include power draw, and you don't even tell the workload / game it is about.
The Crytek Benchmark did include power draw. But the difference is no 2x.
However, i don't want to ignite another useless fanboy war. Even compute benchmarks are almost useless for me, i have to measure with my project to change my own, personal impression of AMD having still the edge, eventually.
Ofc. RTX is faster in a DXR game. I know this as any other does. It might be interesting to figure out how RT Cores help to reduce power draw, versus AMDs approach of offloading RT work to CUs.
But not to me. At this point, API restrictions is all i'm concerned about. Neither performance nor power draw of monster GPUs.
I don't care either...but claiming a "perfomance per Watt" when the facts are different is bad.
AMD's perfomance drops off fast when not doing "RT light"...to the point where we are looking at half the performance compared to NVIDIA, at not the double wattage makes me want to ask to document your claim...because the numbers do not add up in favour of your claim.
Simple as that.
But my 'claim' was in context of a compute raytracing benchmark, and the perf / watt advantage is as true as those numbers shown from the benchmark are correct.
Well, forget about it.
While we nitpick about perf, RTX and Rolls Royce vs. Bentley, end users do not even notice a difference after accidently using iGPU for 4 years: hihihihi
Well, forget about it.
While we nitpick about perf, RTX and Rolls Royce vs. Bentley, end users do not even notice a difference after accidently using iGPU for 4 years: hihihihi
But my 'claim' was in context of a compute raytracing benchmark, and the perf / watt advantage is as true as those numbers shown from the benchmark are correct.
Well, forget about it.
While we nitpick about perf, RTX and Rolls Royce vs. Bentley, end users do not even notice a difference after accidently using iGPU for 4 years: hihihihi
I am aware of the large demographic for consoles
While we nitpick about perf, RTX and Rolls Royce vs. Bentley, end users do not even notice a difference after accidently using iGPU for 4 years
The iGPU is a very capable 2400G. The dGPU is a 1050Ti. Still pretty dumb to not notice for 4 years but somewhat understandable if he didn’t know what to expect from the card.
Clearly the issue here is that the customer had the wrong expectations from their hardware not that they had low standards or didnt care. They seem to care very much given the tweaking they did to squeeze more fps out of their games. Somehow they didn’t put 2 and 2 together.
Even compute benchmarks are almost useless for me, i have to measure with my project to change my own, personal impression of AMD having still the edge, eventually.
I don’t think it’s helpful to the discussion to ignore tons of public data while claiming that your special workload is the only thing that is shaping your opinion on compute. It would be really great if you can share some more details about the workload and the performance you’re seeing on different hardware. You said your solution isn’t like DXR or Crytek or SDF or voxels. So what is it like?
DegustatoR
Legend
UE5 doesn't show anything of the sort.The point was: Software RT starts with smaller achievement due to performance, but may progress faster in the long run because no restrictions or conventions which turn out bad.
And sadly, this point now is relevant, as EU5 shows. Already now, only 3 years later.
It's doing s/w tracing through a much more simplified scene than you'd get even by using proxy meshes for h/w RT.
From IQ PoV UE5's approach is s/w < proxies < true Nanite meshes. The latter isn't possible on DXR 1.1 h/w but that doesn't make the s/w approach better than using proxies.
And that's even before we get to performance where I'd expect the h/w RT with proxies when implemented properly to actually outperform the s/w approach while simultaneously offering a better IQ.
I don’t think it’s helpful to the discussion to ignore tons of public data while claiming that your special workload is the only thing that is shaping your opinion on compute. It would be really great if you can share some more details about the workload and the performance you’re seeing on different hardware. You said your solution isn’t like DXR or Crytek or SDF or voxels. So what is it like?
While i do respect his civil-approach of outing his opinions on the subject (which is worth alot imo), its quite odd how basically everyone and everything and their dog has quite different findings. I have never seen anyone claiming console/amd rt solution to be 'better' in any way (maybe not flexibility), and if so, it doesnt even remotely come close to make up for the speed/performance Ampere (and turing) has to offer.
Digital Foundry/Alex has given his inputs here aswell, along with the tons and tons of benchmarks and even more important, gaming data that show real world ray tracing performance.
IMO, if your seriously intrested in ray tracing and want to flex its abilities to the best extend, be it as a dev or as a gamer, you really have to reside to the pc space and then in special the nvidia's offerings, not to forget DLSS because RT, even HW accelerated, is and will remain a performance hog relatively seen to other effects.
Not saying AMD does that bad with their RT solutions on their RDNA2 gpus, atleast not on pc since there they have much more BW, raw compute and other refinements like infinity cache to throw at it. Im sure RDNA3+ will have increased ray tracing capabilities, customized CU's or some other form of hardware acceleration to keep pace with NV.
And still, AMD's dGPU's are quite far behind Ampere, competing or even behind Turing. Consoles are below that even.
Devs will have to be creative on consoles (like usual...), see rift apart for example (just upscaled reflections). But, your going to be limited still, dev magic can only do so much.
The software solution is going to be too slow for now, the PS2 could do bump mapping, or anything basically in software. It was very, very flexible for its time, and some nice things have been achieved with alot of dev time and input, speed was a huge problem though and effects like bump mapping didnt see much or any use due to just that, speed.
Abit like the decompression units for the SSD's in these consoles, software but... lol, CPU would just struggle too much now.
Last edited:
The workload is pretty various. Overall it's similar to the Many LoDs paper. The scene is represented by a hierarchy of surfels. Initially i generated those at lighmap texel positions from quake levels, using mip maps to form the hierarchy.I don’t think it’s helpful to the discussion to ignore tons of public data while claiming that your special workload is the only thing that is shaping your opinion on compute. It would be really great if you can share some more details about the workload and the performance you’re seeing on different hardware. You said your solution isn’t like DXR or Crytek or SDF or voxels. So what is it like?
There are dynamic objects too, and like DXR i rebuild the top levels every frame to have one BVH for the entire scene.
Each surfel is an irradiance probe. They interreflect with all other surfels to solve rendering equation, utilizing caching in the probes to get infinite bounces for free. Interreflection also utilizes a 'lodcut' of the scene, like ManyLODs or Michael Bunnels realtimje AO/GI did before. Visibility is resolved with raytracing. I use the actual surfel representation (so discs, not detailed triangles) for occluders. One workgroup updates one probe, so all rays have the same origin, and scene complexity is small due to lodcut. Enables some optimizations of the raytracing problem and is good enough for GI.
Tu support BRDF, i also generate a small spherical cap environment map for each surfel (4x4 or maybe now 8x8, but's its prefiltered). That's lower res than the Many LOD paper has used, so my reflections are pretty blurry and support for smooth materials is limited.
Spatial resolution of probes was 10cm (near the camera), targeting last gen. Shadows are blurry too as they come from just 10cm discs. Fine for large are lights, but bad for small / point lights. Traditional shadow maps thus are still necessary if we need those details. RT could care for sharp reflections. (On the long run i think RT should replace SMs entirely, and personally i'd like to use it for all direct lighting.)
So that's all standard stuff, which i can talk about without revealing any 'secrets'. Maybe something like 20 compute shaders. I started with OpenGL, then OpenCL (twice faster on NV, surprisingly), finally Vulkan (twice faster again for both due to prerecorded command buffers and indirect dispatch.)
Initial hardware was Fermi / Kepler. Then i bought some 280X to test AMD, which was mid range GCN, and it was twice faster than a Kepler Titan GPU. That's when i became very convinced about AMD compute. After some AMD specific optimizations, mostly about trading random VRAM access vs. caching in LDS, the difference even became larger.
Latest test on that old HW was a 7950 vs. GTX670 using Vulkan, and AMD was a whopping 5 times faster with those GPUs (similar price and also game performance otherwise).
There is nothing special on my work. No frequent atomics to VRAM for example. And i saw this ratio accross all my very different shaders, so it seems no outlier. The project is too large for that, but it surely does not represent typical game workloads either.
Latest new HW i have tasted was FuryX vs. GTX1070. AMD still had a 10% lead if normalizing on teraflops, but obviously NV has fixed its shortcomings about compute perf.
And the improvements on Turing looked promising as well. I just remain sceptical about a lead due to experience. I assume both vendors do pretty similar currently, which is good if so. Kepler vs. GCN was maybe just a bad start for NV, but now the impression is deeply founded in my mind.
Ofc, all this is subjective and just one data point, and you have to weight it yourself when adding to all others.
Edit: AMD model number corrected
Last edited:
DegustatoR
Legend
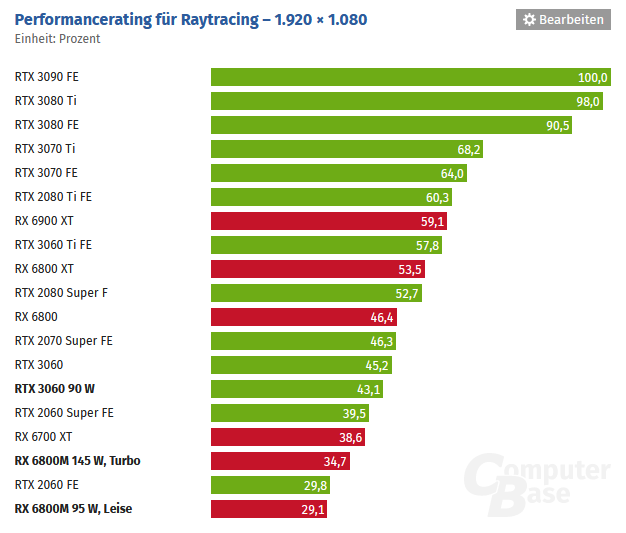
https://www.computerbase.de/2021-07/amd-radeon-rx-6800m-benchmark-test/
On the question of perf/watt with RT.
The workload is pretty various. Overall it's similar to the Many LoDs paper. The scene is represented by a hierarchy of surfels. Initially i generated those at lighmap texel positions from quake levels, using mip maps to form the hierarchy.
There are dynamic objects too, and like DXR i rebuild the top levels every frame to have one BVH for the entire scene.
Each surfel is an irradiance probe. They interreflect with all other surfels to solve rendering equation, utilizing caching in the probes to get infinite bounces for free. Interreflection also utilizes a 'lodcut' of the scene, like ManyLODs or Michael Bunnels realtimje AO/GI did before. Visibility is resolved with raytracing. I use the actual surfel representation (so discs, not detailed triangles) for occluders. One workgroup updates one probe, so all rays have the same origin, and scene complexity is small due to lodcut. Enables some optimizations of the raytracing problem and is good enough for GI.
Tu support BRDF, i also generate a small spherical cap environment map for each surfel (4x4 or maybe now 8x8, but's its prefiltered). That's lower res than the Many LOD paper has used, so my reflections are pretty blurry and support for smooth materials is limited.
Spatial resolution of probes was 10cm (near the camera), targeting last gen. Shadows are blurry too as they come from just 10cm discs. Fine for large are lights, but bad for small / point lights. Traditional shadow maps thus are still necessary if we need those details. RT could care for sharp reflections. (On the long run i think RT should replace SMs entirely, and personally i'd like to use it for all direct lighting.)
So that's all standard stuff, which i can talk about without revealing any 'secrets'. Maybe something like 20 compute shaders. I started with OpenGL, then OpenCL (twice faster on NV, surprisingly), finally Vulkan (twice faster again for both due to prerecorded command buffers and indirect dispatch.)
Initial hardware was Fermi / Kepler. Then i bought some 280X to test AMD, which was mid range GCN, and it was twice faster than a Kepler Titan GPU. That's when i became very convinced about AMD compute. After some AMD specific optimizations, mostly about trading random VRAM access vs. caching in LDS, the difference even became larger.
Latest test on that old HW was a 5970 vs. GTX670 using Vulkan, and AMD was a whopping 5 times faster with those GPUs (similar price and also game performance otherwise).
There is nothing special on my work. No frequent atomics to VRAM for example. And i saw this ratio accross all my very different shaders, so it seems no outlier. The project is too large for that, but it surely does not represent typical game workloads either.
Latest new HW i have tasted was FuryX vs. GTX1070. AMD still had a 10% lead if normalizing on teraflops, but obviously NV has fixed its shortcomings about compute perf.
And the improvements on Turing looked promising as well. I just remain sceptical about a lead due to experience. I assume both vendors do pretty similar currently, which is good if so. Kepler vs. GCN was maybe just a bad start for NV, but now the impression is deeply founded in my mind.
Ofc, all this is subjective and just one data point, and you have to weight it yourself when adding to all others.
Really interesting, thanks for sharing. Sounds a little like a hybrid between DDGI and Lumen with the added benefit of LODs within the surfel cache.
You should definitely try to get your hands on some newer hardware. Fury and Pascal aren’t really relevant today.
DegustatoR
Legend
5970 doesn't support Vulkan though?Latest test on that old HW was a 5970 vs. GTX670 using Vulkan, and AMD was a whopping 5 times faster with those GPUs (similar price and also game performance otherwise).
And I wonder what is it you're doing in compute for VLIW4 to be 5x faster than scalar.
I did not notice how my 'it's better' would be perceived, and when i realized, it was too late. Sorry for the fuzz and rudeness.I have never seen anyone claiming console/amd rt solution to be 'better' in any way (maybe not flexibility), and if so, it doesnt even remotely come close to make up for the speed/performance Ampere (and turing) has to offer.
Now it's clear i meant API restrictions, not HW performance. Sadly for me the HW is only as good as the API, because there is no other way to use it.
Notice this holds true no matter if we talk about Series S or 3090. Perf. limits are always there and can't be changed.Devs will have to be creative on consoles (like usual...), see rift apart for example (just upscaled reflections). But, your going to be limited still, dev magic can only do so much.
For me there is this magic number of about 10. If perf difference is lower, we can scale. If it's higher, it enables new things not possible on the low end. Usually, within a console generation, we keep below this number. And til yet that's also the case with raytracing.
The topic of 'console holding back PC' (and others) feels pretty artificial. It's like men arguing which football team is better, although they both love football and watch the same games.
Contrary to that, API limits are holding back for real. Independent of HW, better APIs can enable better performance. On the other hand, performance benchmarks always fall back to platform or vendor wars, with no general profit. So it's beyond me why the former is ignored, while the latter becomes public religion. (Well, i see i post this in the wrong thread, but still.)
Devs want to be able to be creative on PC as well. Also this argument is independent of the initial performance we start from.Devs will have to be creative on consoles (like usual...)
Did you use shared memory (LDS) atomics extensively in your shaders?here is nothing special on my work. No frequent atomics to VRAM for example.
Yep, but the reason it's fast is something new. I should get done to limit the risk it will die with me in secret...Sounds a little like a hybrid between DDGI and Lumen with the added benefit of LODs within the surfel cache.
Waiting for reasonable prices. Though, it's just compute and nothing has change here since ages aside subgroup functions and fp16.You should definitely try to get your hands on some newer hardware. Fury and Pascal aren’t really relevant today.
No, 59 series was 1st or maybe 2nd gen of GCN on PC, Vulkan works. Though maybe i remember the model number wrongly. Could be 5950, or even 5870. But i'm sure it's a 3TF GCN model. I still use it for benchmarks.5970 doesn't support Vulkan though?
And I wonder what is it you're doing in compute for VLIW4 to be 5x faster than scalar.
Yes, often but not extensively. I have learned Kepler did emulate this in VRAM(?), so i assume it's the major reason of it being so slow for me.Did you use shared memory (LDS) atomics extensively in your shaders?
IDK what Fermi did, but 670 was exactly as fast as 480 overall, while showing better perf. in cases where atomics to LDS were used.
Whatever, when NV dropped driver support for Kepler recently, i did celebrate it's death
Similar threads
- Replies
- 7
- Views
- 2K
- Replies
- 0
- Views
- 530
- Replies
- 454
- Views
- 69K
- Replies
- 15
- Views
- 3K