Blurring the Line between Physics and Imagination: A Glimpse of Neural Rendering's Future
Marco Salvi, Principal Research Scientist, NVIDIA
Abstract
In this talk, I will discuss the transformative impact of machine learning techniques, which are breathing new life into real-time rendering. Advances in novel scene representations and image reconstruction approaches have emerged alongside sophisticated generative models that do not rely on the physics of light transport.
These developments are bringing about a major shift in how we generate images, challenging traditional rendering pipelines. I will explore some of the possibilities that lie ahead as these distinct approaches may converge, seamlessly blending physics and imagination to create realistic and accessible computer-generated imagery.
Bio
Marco Salvi is a Principal Research Scientist at NVIDIA, where he works on developing high-performance software and hardware rendering algorithms for the post-Moore's law era.
His research interests span a broad range of topics, from anti-aliasing and order-independent transparency to ray tracing hardware, texture compression and neural rendering. Marco has made numerous contributions to rendering APIs, including raster order views and micro-meshes, and his early work on real-time neural image reconstruction has led to the development of NVIDIA DLSS.
Prior to becoming a researcher, Marco worked at Ninja Theory and LucasArts architecting advanced graphics engines, performing low-level optimizations and developing new rendering techniques for games on two generations of Playstation and XBOX consoles.
Marco holds an M.S. in Physics from the University of Bologna, Italy.
Install the app
How to install the app on iOS
Follow along with the video below to see how to install our site as a web app on your home screen.
Note: This feature may not be available in some browsers.
You are using an out of date browser. It may not display this or other websites correctly.
You should upgrade or use an alternative browser.
You should upgrade or use an alternative browser.
Game development presentations - a useful reference
- Thread starter liolio
- Start date
Enough with these vaseline smuged blurry graphics! Call me when they have a talk called "Sharpening the line between physics and imagination"
Update: Sebbi's presentation isn't up on video yet, but Natalya Tatarchuk posted the slides just now.
Also another great presentation in slide format from REAC. Ubisoft's Dunia Engine long-term shader pipeline vision. They go over how they evolved their shader pipeline over the course of Farcry 4-6. They also reference shader compilation issues in many games with images from Digital Foundry on one of the slides.
Also another great presentation in slide format from REAC. Ubisoft's Dunia Engine long-term shader pipeline vision. They go over how they evolved their shader pipeline over the course of Farcry 4-6. They also reference shader compilation issues in many games with images from Digital Foundry on one of the slides.
They really did credit DF with motivation for the presentation. Alex's efforts are paying off.
This is really smart though probably won't work as well for games with lots of unique interiors / environments.
- Render the world behind the loading screen
- Spinning the character around itself
- This primes the virtual textures and shader variations
DegustatoR
Legend
Too bad Dunia seems to be dead with Ubisoft moving FC to Snowdrop instead.
I would give credit to the entire DF team, as they extensively covered the struggles with stutters in Far Cry 4, where it was caused by the paging of megatextures. Since then, it seems that they have made a significant effort to eliminate the stutter across the engine and ensure that it did not return with DX12. This initial criticism and extensive coverage of stuttering in press served as a kind of vaccination against stuttering for the Dunia teams. Wonder whether Epic will follow the suit, given that the responsibility on them is much higher. The sad part is that it still took Alex's intervention to prompt them to take action (and only in UE 5).They really did credit DF with motivation for the presentation. Alex's efforts are paying off.
Last edited:
Too bad Dunia seems to be dead with Ubisoft moving FC to Snowdrop instead.
Really? Hadn’t heard that. It makes sense though. Ubisoft has too many open world engines.
davis.anthony
Veteran
Not sure if this has been posted.
A look at Far Cry's shader pipeline
A look at Far Cry's shader pipeline
Frenetic Pony
Veteran
Really? Hadn’t heard that. It makes sense though. Ubisoft has too many open world engines.
Supposedly Far Cry and AC will both be sticking to their respective engines while everything else gets moved to Snowdrop, they're trying to avoid development complications
Real-Time Ray Tracing of Micro-Poly Geometry with Hierarchical Level of Detail

Real-Time Ray Tracing of Micro-Poly Geometry with Hierarchical Level...
In recent work, Nanite has demonstrated how to rasterize virtualized micro-poly geometry in real time, thus enabling immense geometric complexity.
 www.intel.com
www.intel.com
Nice. 
Unfortunately, the only way to do this is to apply for a job at Intel, NV, or AMD. Not so nice.
But at least there is growing awareness about static meshes not being enough...
EDIT: Still not done with reading the whole paper, but some comments anyway.
From the paper we now know Intel uses BVH6, while AMD uses BVH4 according to ISA.
The papers proposal differs from my Nanite example used in discussions.
I had proposed to convert the LOD hierarchy, which may be a BVH8 for example, directly into the HW format of BVH6/4/?.
Beside the branching factor, advanced HW may have some more constraints, e.g. speculated treelet compression for NV.
In the paper they avoid such conversion complexity. Instead they just take the current lodcut of visible clusters and build a BVH from scratch over them per frame.
That's an option i've had in mind, and we could do this already by making each cluster a 'mesh/model' with it's BLAS only needed to be build on LOD changes,
and one TLAS to conncet them all. That's really all we could currently do to make granular LOD traceable.
But the cost of building such a big TLAS over so many clusters feels way to high for me. In they paper they say it's practical for realtime, but imo that's a yes for research, but still a no for games on affordable HW.
People would still mostly turn RT off for a better experience, and it stays an optional feature.
Right now i somehow miss the point of the paper. I hoped they utilized native HW access to do things not possible using DXR.
But maybe they did it just to use existing libraries like Embree BVH builders more easily.
Instead of rasterization, we decompress each selected cluster into a small bounding volume hierarchy (BVH) in the format expected by the ray tracing hardware.
Unfortunately, the only way to do this is to apply for a job at Intel, NV, or AMD. Not so nice.
But at least there is growing awareness about static meshes not being enough...
EDIT: Still not done with reading the whole paper, but some comments anyway.
From the paper we now know Intel uses BVH6, while AMD uses BVH4 according to ISA.
The papers proposal differs from my Nanite example used in discussions.
I had proposed to convert the LOD hierarchy, which may be a BVH8 for example, directly into the HW format of BVH6/4/?.
Beside the branching factor, advanced HW may have some more constraints, e.g. speculated treelet compression for NV.
In the paper they avoid such conversion complexity. Instead they just take the current lodcut of visible clusters and build a BVH from scratch over them per frame.
That's an option i've had in mind, and we could do this already by making each cluster a 'mesh/model' with it's BLAS only needed to be build on LOD changes,
and one TLAS to conncet them all. That's really all we could currently do to make granular LOD traceable.
But the cost of building such a big TLAS over so many clusters feels way to high for me. In they paper they say it's practical for realtime, but imo that's a yes for research, but still a no for games on affordable HW.
People would still mostly turn RT off for a better experience, and it stays an optional feature.
Right now i somehow miss the point of the paper. I hoped they utilized native HW access to do things not possible using DXR.
But maybe they did it just to use existing libraries like Embree BVH builders more easily.
Last edited:
HPG 2023 livestreaming started today
 www.youtube.com
www.youtube.com
The program:
 www.highperformancegraphics.org
www.highperformancegraphics.org
- YouTube
Auf YouTube findest du die angesagtesten Videos und Tracks. Außerdem kannst du eigene Inhalte hochladen und mit Freunden oder gleich der ganzen Welt teilen.
www.youtube.com
The program:
High-Performance Graphics 2023: Program
High-Performance Graphics 2023 Program
www.highperformancegraphics.org
The Rendering Engine Architecture Conference (REAC) videos are online now.
https://www.youtube.com/@renderingenginearchitectur3543
https://www.youtube.com/@renderingenginearchitectur3543
HPG 2023 has the live streams split up into separate presentation videos now. Well worth a watch
Not a presentation but cool https://developer.nvidia.com/blog/in-game-gpu-profiling-for-dx12-using-setbackgroundprocessingmode/
DegustatoR
Legend
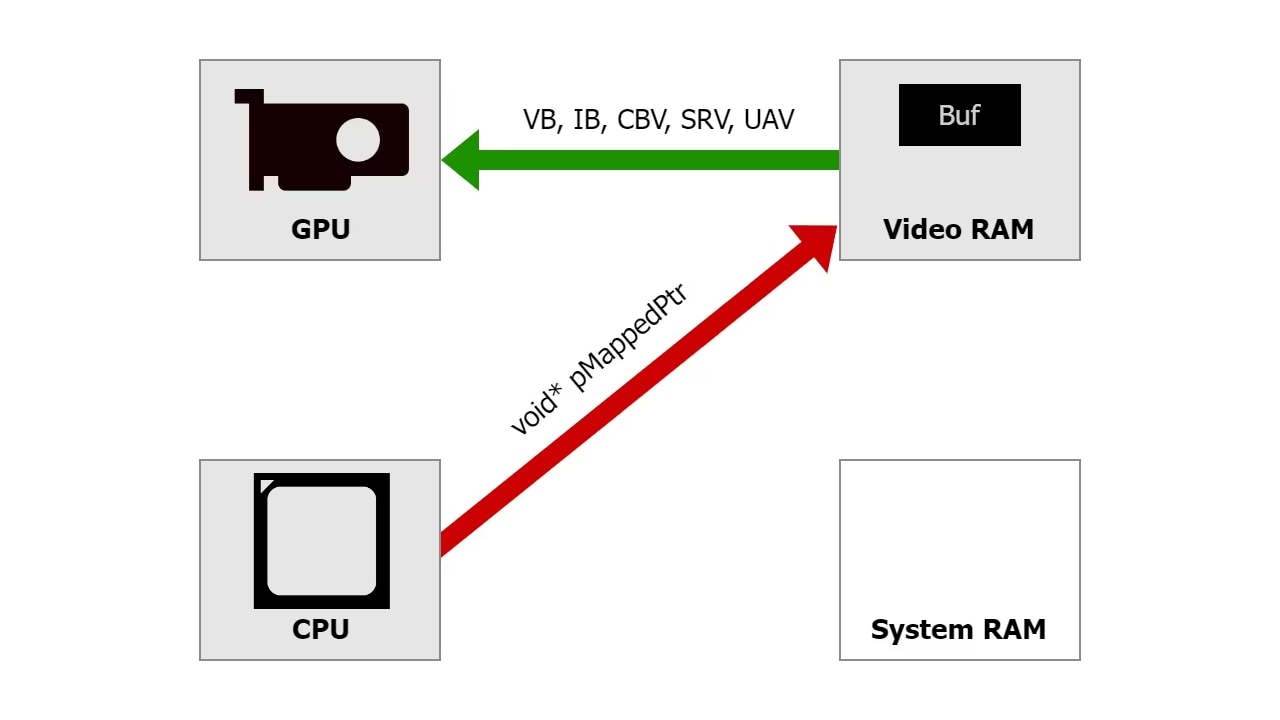
Effective use of the new D3D12_HEAP_TYPE_GPU_UPLOAD flag
The D3D12_HEAP_TYPE_GPU_UPLOAD flag in Direct3D®12 provides a good alternative to other ways of uploading data from the CPU to the GPU. Check out our quick guide to effective use of this flag.
 gpuopen.com
gpuopen.com
https://zheng95z.github.io/publications/roma23
Approach on software RT with interesting performance. Tracing a ray is O(1), and generating the 'acceleration structure' from scratch is linear to scene complexity.
They do a low res voxelization per frame, then generate 2D images from a set of random directions, by rotating the voxels to the direction and storing a slab of 32(or more) bit voxels per texel.
A ray is then snapped to the closest direction, and tracing intersection only requires to test the bits we get from a single fetch. To deal with snapping restrictions they choose different directions each frame and filter temporally.
Precise ray directions work too, but then they need some more texel fetches from the closest image to do a search.
Though, i guess for practical use in video games we would need nested mip levels to support large scenes, so costs would go up by the number of levels.
Due to low detail, it also fails on hard shadows or sharp reflections.
Approach on software RT with interesting performance. Tracing a ray is O(1), and generating the 'acceleration structure' from scratch is linear to scene complexity.
They do a low res voxelization per frame, then generate 2D images from a set of random directions, by rotating the voxels to the direction and storing a slab of 32(or more) bit voxels per texel.
A ray is then snapped to the closest direction, and tracing intersection only requires to test the bits we get from a single fetch. To deal with snapping restrictions they choose different directions each frame and filter temporally.
Precise ray directions work too, but then they need some more texel fetches from the closest image to do a search.
Though, i guess for practical use in video games we would need nested mip levels to support large scenes, so costs would go up by the number of levels.
Due to low detail, it also fails on hard shadows or sharp reflections.
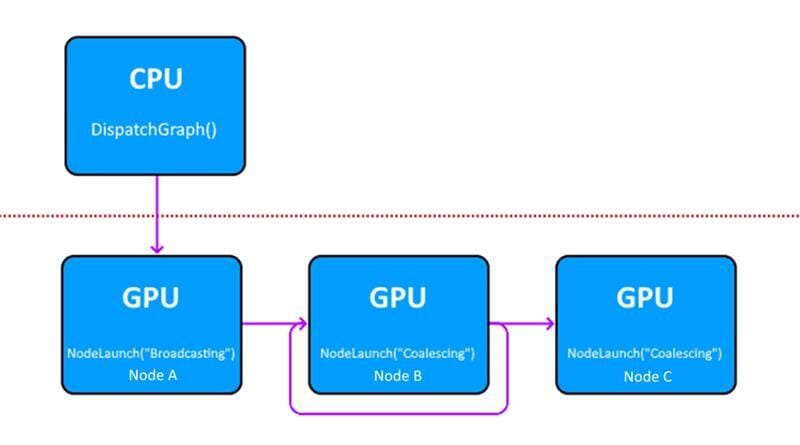
Announcing GPU Work Graphs in Vulkan®
AMD is providing an experimental AMD extension to access GPU Work Graphs in Vulkan. Check out this post for usage examples and resources.
gpuopen.com
An experimental GPU work graph vendor extension for Vulkan released by AMD ...
Now that we can do "persistent threads" style programming, I assume interest will pick up again with topics like GRAMPS ...
Similar threads
- Replies
- 2
- Views
- 4K
- Replies
- 25
- Views
- 3K
- Replies
- 21
- Views
- 11K
- Replies
- 90
- Views
- 18K