siggraph 2023 stuff is being posted, including Sebastian Aaltonen's talk, which was supposed to be very good.
Install the app
How to install the app on iOS
Follow along with the video below to see how to install our site as a web app on your home screen.
Note: This feature may not be available in some browsers.
You are using an out of date browser. It may not display this or other websites correctly.
You should upgrade or use an alternative browser.
You should upgrade or use an alternative browser.
Game development presentations - a useful reference
- Thread starter liolio
- Start date
I don't know this person, but it's an interesting watch
Edit: Kind of interesting. Basically saying forward rendering is better because without SSR you can save a lot of bandwidth and scale to lower end gpus. The trade off is pixel overdraw because of shading being down as quads. Kind of makes me wonder about a lot of gpus because I feel like compute is scaling faster than memory bandwidth and memory latency.
triangle visibility buffering is not considered here.
Edit: Kind of interesting. Basically saying forward rendering is better because without SSR you can save a lot of bandwidth and scale to lower end gpus. The trade off is pixel overdraw because of shading being down as quads. Kind of makes me wonder about a lot of gpus because I feel like compute is scaling faster than memory bandwidth and memory latency.
triangle visibility buffering is not considered here.
Last edited:
Frenetic Pony
Veteran
I don't know this person, but it's an interesting watch
Edit: Kind of interesting. Basically saying forward rendering is better because without SSR you can save a lot of bandwidth and scale to lower end gpus. The trade off is pixel overdraw because of shading being down as quads. Kind of makes me wonder about a lot of gpus because I feel like compute is scaling faster than memory bandwidth and memory latency.
triangle visibility buffering is not considered here.
Yeah this is exclusively for super, super, super low end hw targets. As soon as you get anything approaching modern triangle counts you start getting triangle overdraw using forward very quickly.
Frenetic Pony
Veteran
siggraph 2023 stuff is being posted, including Sebastian Aaltonen's talk, which was supposed to be very good.
The Call of Duty terrain one is fascinating, because it helps show why Call of Duty looks so ancient now, at least in terms of multiplayer. Hadn't quite realized how wide their platform target is, "32mb is a lot of memory on some platforms" is just, damn.
On the other hand, if visuals really do sell (I'm not convinced how much this is actually the case) it just means someone that targeted even say, Switch 2 mobile @30fps, as a minimum platform would easily be able to dominate Cod visually.
Sparse Virtual Shadow Maps inspired by UE5.
Sparse Virtual Shadow Maps
Devlogs and tutorials about GPGPU and graphics programming
ktstephano.github.io

Conditional Resampled Importance Sampling and ReSTIR | NVIDIA Real-Time Graphics Research
Recent work on generalized resampled importance sampling (GRIS) enables importance-sampled Monte Carlo integration with random variable weights replacing the usual division by probability density. This enables very flexible spatiotemporal sample reuse, even if neighboring samples (e.g., light...
Capcom is uploading a lot of videos on RE Engine to their youtube page, covering many topics
DegustatoR
Legend

How Northlight makes Alan Wake 2 shine
Showcasing new Northlight technology in Alan Wake 2
 www.remedygames.com
www.remedygames.com
cheapchips
Veteran
GDC talk on Frostbite's procedural terrain tools and workflows.
Some strange things in that one.
16xSSAA certainly would be nice to have as common AA method..
A Gentle Introduction to ReSTIR Path Reuse in Real-Time
Video of a presentation in supplemental section.DavidGraham
Veteran
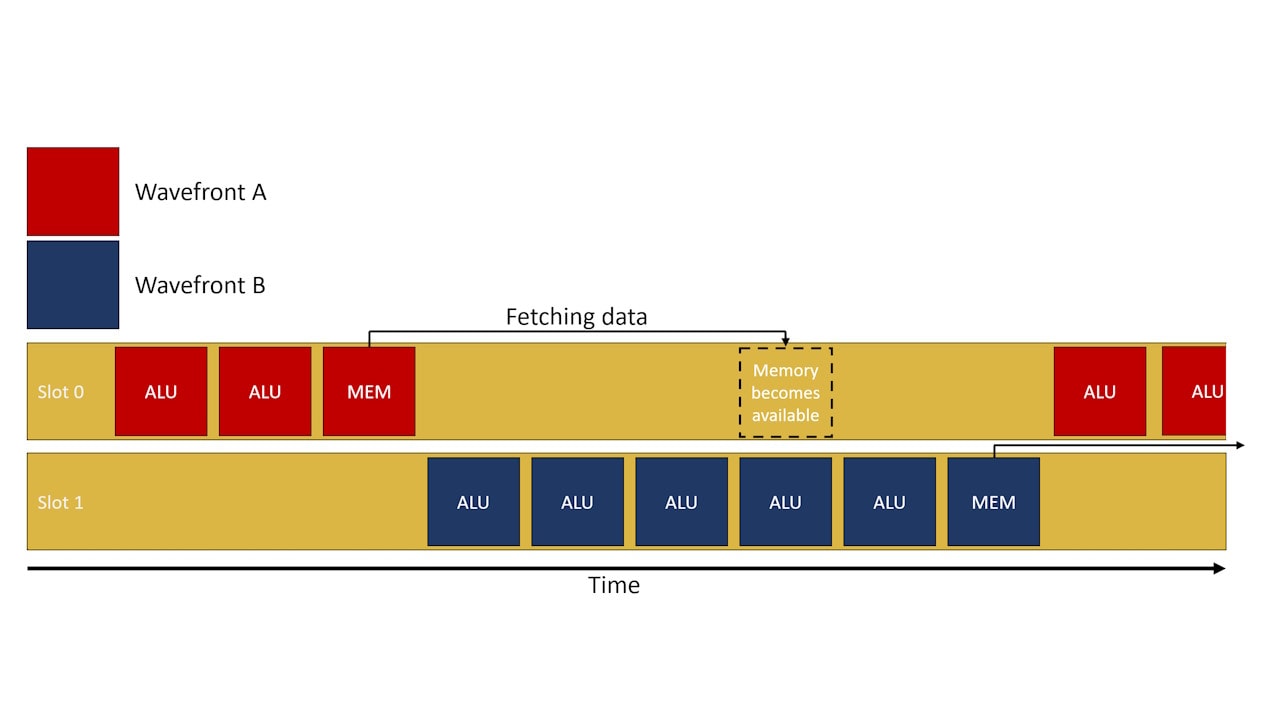
AMD posted an informative blog about GPU occupancy.
 gpuopen.com
gpuopen.com
So occupancy going up can mean performance goes down, because of that complex interplay between getting the most out of the GPU’s execution resources while balancing its ability to service memory requests and absorb them well inside its cache hierarchy. It’s such a difficult thing to influence and balance as the GPU programmer, especially on PC where the problem space spans many GPUs from many vendors, and where the choices the shader compiler stack makes to compile your shader can change between driver updates.
Occupancy explained
In this blog post we will try to demystify what exactly occupancy is, which factors limit occupancy, and how to use tools to identify occupancy-limited workloads.
gpuopen.com
Tiled deffered shadow used for FF16
DavidGraham
Veteran

Khronos Releases Maximal Reconvergence and Quad Control Extensions for Vulkan and SPIR-V
The SPIR™ Working Group has developed two new SPIR-V extensions (and corresponding Vulkan® extensions) to provide shader authors with more guarantees about the execution model of shaders. These extensions formalize behavior many authors have previously taken for granted, so that they can now be...
 www.khronos.org
www.khronos.org
The above extension makes stronger behaviour guarantees behind reconvergence/divergence during subgroup operations. This functionality prevents compilers out of doing specific optimizations for SIMT architectures since they lack lockstep execution guarantees for subgroup operations in the presence of divergence ...
I also stumbled upon an interesting issue from an IHV that claimed that they can't sanely implement wave operations for helper lanes since Direct3D spec authors implicitly assume maximal reconvergence behaviour by default for their API which by contrast is explicitly disallowed in that specific case for Vulkan as per footnote in the aforementioned blog post ...
Alan Baker said:
- In cases where all remaining invocations in a quad are helpers, implementations may terminate the entire quad - maximal reconvergence cannot be used to require these remain live.
https://lfranke.github.io/trips/
Sharper than Spherical Gaussians.
Interesting method. They splat points bilinear to 2x2 pixels and two mips of a framebuffer pyramid. Larger points go to lower res mip levels, solving the holes problem.
I use the exact same thing to generate my GI environment maps. (Remembering when i've asked how to get in contact with Dreams devs, this was the proposal i wanted to make. Use mip maps instead rendering entire cubes from large points. )
)
However, to make this a general rendering method, they also have to solve transparency / depth sorting. (Which i do not, since visibility is already known in my case)
And they use something like a list of 16 fragments per pixel in the paper, similar to OIT approaches.
That's slow of coarse.
I've had tried a faster option: Each point only goes into one pixel, using depth comparison as usual to find the closest point.
After that, reconstruct antialiased image by weighting winning points from a 3x3 kernel.
I've tried this only on CPU, and it's promising. But there is some popping ofc. TAA might help.
However, after i saw the Spherical Gaussians paper i thought that's really high quality, and it can do proper transparency. Maybe a more expensive method is worth it. Maybe it's time to tackle this transperency problem...
Sharper than Spherical Gaussians.
Interesting method. They splat points bilinear to 2x2 pixels and two mips of a framebuffer pyramid. Larger points go to lower res mip levels, solving the holes problem.
I use the exact same thing to generate my GI environment maps. (Remembering when i've asked how to get in contact with Dreams devs, this was the proposal i wanted to make. Use mip maps instead rendering entire cubes from large points.
)However, to make this a general rendering method, they also have to solve transparency / depth sorting. (Which i do not, since visibility is already known in my case)
And they use something like a list of 16 fragments per pixel in the paper, similar to OIT approaches.
That's slow of coarse.
I've had tried a faster option: Each point only goes into one pixel, using depth comparison as usual to find the closest point.
After that, reconstruct antialiased image by weighting winning points from a 3x3 kernel.
I've tried this only on CPU, and it's promising. But there is some popping ofc. TAA might help.
However, after i saw the Spherical Gaussians paper i thought that's really high quality, and it can do proper transparency. Maybe a more expensive method is worth it. Maybe it's time to tackle this transperency problem...

The Last Night's Game Architecture • Odd Blog
A deep dive into our state-of-the-art technical foundations on Unity.
Similar threads
- Replies
- 2
- Views
- 4K
- Replies
- 25
- Views
- 3K
- Replies
- 21
- Views
- 10K
- Replies
- 90
- Views
- 18K