probably doesn't have faster int4 and int8 computation capablilities as xsx that you can use in ml
it may. int4 and int8 is supported on RDNA1, but it's possible that explicit customizations to the CU are required to support RPM for int4 and int8. It supports FP16 RPM by default.
what it likely doesn't have the ML add-on to support mixed precision/weight operations. So if you're using a lot of algorithms that are mixing 8, 4, and 16 you're not going to see the speed improvements you'd expect. This is also supported on RDNA1, but the CUs needed to be explicitly customized for this according to AMD white paper.
Some variants of the dual compute unit expose additional mixed-precision dot-product modes in the ALUs, primarily for accelerating machine learning inference. A mixed-precision FMA dot2 will compute two half-precision multiplications and then add the results to a single-precision accumulator. For even greater throughput, some ALUs will support 8-bit integer dot4 operations and 4-bit dot8 operations, all of which use 32-bit accumulators to avoid any overflows.
edit: to put it more succinctly, higher precision produces better results from a quality perspective. Higher precision however has drawbacks on computation and bandwidth. Lower precision has faster computation and lower bandwidth requirements.
After you create your model using high precision, you may, run an application of some sort, or if the ML library you are using supports it, it will port your model (or automatically run) to a mixed precision model. What it does is look for specific weights areas that do not benefit from high precision and lower them. Those specific weights that do require them it will keep them high. So therefore having mixed precision dot products are critical to supporting optimized networks in this fashion.
This is my understanding, but I've never tried it (rather tested against it, since I only have access to Pascal cards and not Volta). But this is a core feature of Tensor Cores since their introduction. I think Pascal may support as low as mixed int8 precision and int16 precision but not int4.
I believe Ampere supports int4 mixed precision, not sure about Volta (it does not). I'm honestly not well versed in this stuff, I'd have to read a lot to see which architectures support what. But I think you get the idea here.
Nvidia marketing materials compare fixed vs mixed precision. You lose approximately < 0.25% accuracy on your network but performance is 3X. This is worth a trade off.
edit 2:
Just going to address one more point with respect to Nvidia tensor cores vs having to do ML on compute. Tensor cores are specifically tuned to performing Deep Learning/Neural Network type machine learning, they are not at all that much useful for other algorithms. So you still need standard compute for all other forms of ML.
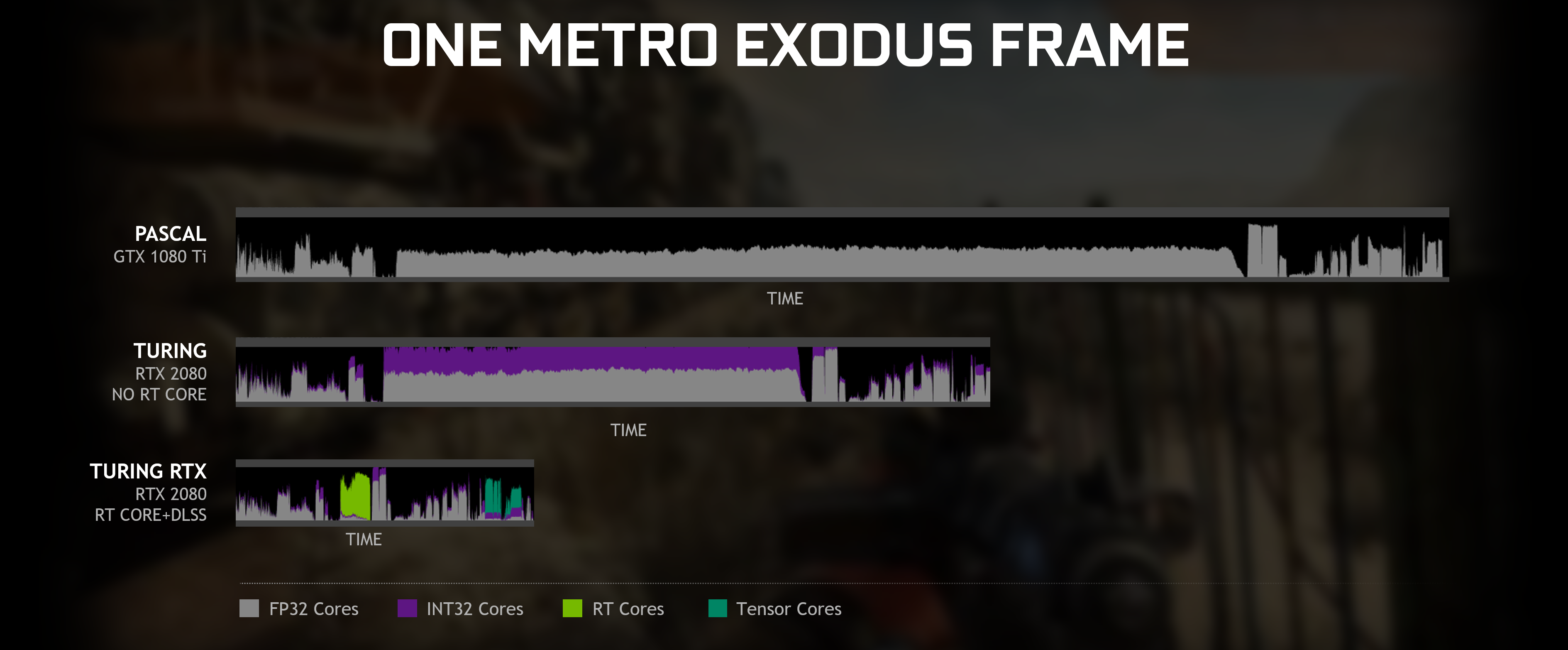
WRT DLSS >> DLSS replaces the MSAA step that would normally be handled by your GPU. During this time it will DLSS and the final results will be spit back for the rest of the pipeline to continue. When Turing/Ampere offloads the work away from the CUDA cores to Tensor Cores to do this, the pipeline, as I understand from reading, is stalled until DLSS is complete. So you can't really continue rendering normally until DLSS is done. You can (edit: maybe not) do async compute while waiting for DLSS to complete since your compute is free to do whatever as you offloaded this process to Tensor Cores.
With respect to the consoles, the only losses compared to nvidia's solution is
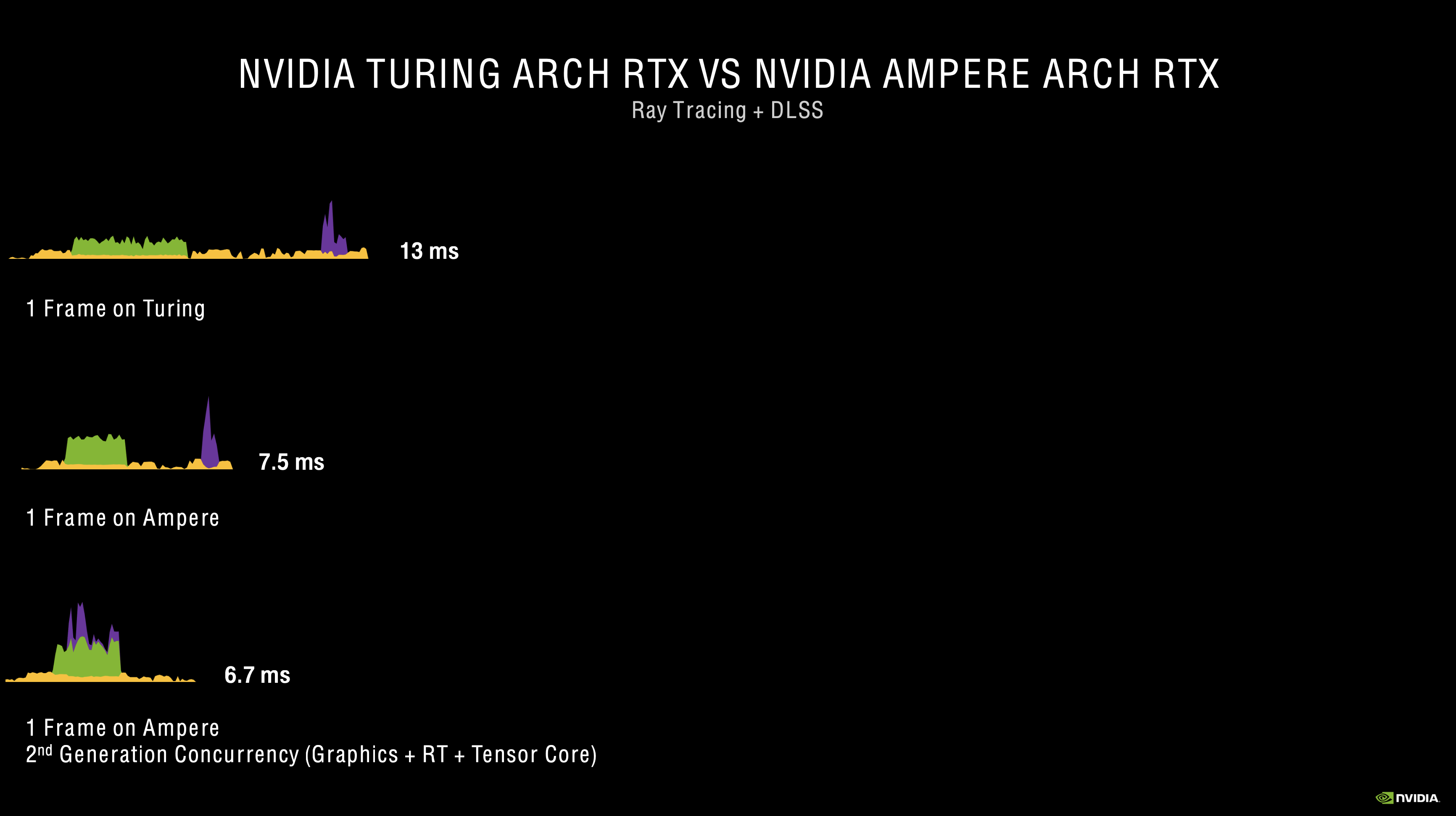
a) tensor cores power through neural networks at a much faster rate than compute
b) they can do async compute since the CUDA cores are no longer in use at this time
that's about all I can speculate. Since neural networks have a fixed run time, it's going to take a fixed amount of ms out of your render. So fixed rendering @ resolution + fixed NN for upscale. You'll only have so much time to meet 16ms and 33ms respectively. It makes sense for the consoles to leverage this for 33ms where it can take advantage of the additional time for quality improvements.