What's the market? HPC? There's a lot more involved that just providing good hardware in HPC space and space is also a significant factor.A bit off topic, but I've always wondered why AMD never produced APU pcie cards. What would stop them putting raven ridge on a pcie board with a lot of ram, essentially an add-on SOC?
Would there be some value in them adding a small CPU component to all their products on the otherside side of the PCIe bus?
Install the app
How to install the app on iOS
Follow along with the video below to see how to install our site as a web app on your home screen.
Note: This feature may not be available in some browsers.
You are using an out of date browser. It may not display this or other websites correctly.
You should upgrade or use an alternative browser.
You should upgrade or use an alternative browser.
Magnum_Force
Newcomer
I wasn't thinking of a specific market, more of a value add to existing markets, gaming included.
AMD seemed to think there was value in adding in a custom audio accelerator in the way of Tenscilla DSP, however I would have thought a small x86 processor, bobcat for example, put on every gpu they manufactured would have been a better fit. They could have recommended devs use it to offload audio processing initially.
AMD seemed to think there was value in adding in a custom audio accelerator in the way of Tenscilla DSP, however I would have thought a small x86 processor, bobcat for example, put on every gpu they manufactured would have been a better fit. They could have recommended devs use it to offload audio processing initially.
Facebook co-designed Xeon D with Intel. There is certainly a big need for a power efficient 8-16 core CPU. Especially if it is a SoC and integrates networking, etc.For what it's worth, 45W 8-core CPUs are an intriguing proposition as well, but I don't know that there's a market for that.
Facebook quote: Three years ago we started working with Intel to define the details of a new processor called Broadwell-D, part of Intel's Xeon line of processors, that was better suited to data center workloads rather than enterprise.
The first Xeon D (D-1540) was a low clocked (2.0 GHz base, 2.6 GHz turbo) power optimized Broadwell 8-core (16 thread) SoC with 45W TDP. Since then Intel has also released 12 and 16 core models with 45W and 65W TDPs. 16 core 45W model runs at 1.3 GHz (base) and 2.1 GHz turbo. If AMD is able to enter this market with Zen, they will sell a huge amount of chips. But power/watt is the most important factor in this market, and they must beat Intel to succeed.
Intel is selling their top of the line Xeon D 8-cores at ~600$. Xeon D profit margins seem to be significantly lower compared to top of the line i7 8-cores (6900K = ~1100$). It would be interesting to see what happens if AMD enters this market with Zen. Zen seems to be perfectly fit for this market. But AMD needs to integrate everything to the same SoC in order to be relevant. CPU alone isn't enough.
Last edited:
itsmydamnation
Veteran
Intel is selling their top of the line Xeon D 8-cores at ~600$. Xeon D profit margins seem to be significantly lower compared to top of the line i7 8-cores (6900K = ~1100$). It would be interesting to see what happens if AMD enters this market with Zen. Zen seems to be perfectly fit for this market. But AMD needs to integrate everything to the same SoC in order to be relevant. CPU alone isn't enough.
They have, PCI-E, south bridge(NVME and SATA no idea if it supports SAS), Network are all on Chip. The one thing that i want to see is if the rumored SOC based Crypto engines really exist, then it will be really competitive in any web environment.
edit: original rumor
http://www.fudzilla.com/media/k2/items/cache/bdff5e4df5710735d8a1ecdc5dd9efcf_XL.jpg
It would be better to use gpgpu for that. That's why amd don't have a dsp anymore and now use the gpu for that. Also If you want to really process audio you would need more than just a small cpu. Good dsp are the size of an Xbox one s.
Enviado desde mi HTC One mediante Tapatalk
Specially when they can dedicate specific CU's count to this. ( as they have shown by the past ). something like virtualization inside the chip.
Facebook co-designed Xeon D with Intel. There is certainly a big need for a power efficient 8-16 core CPU. Especially if it is a SoC and integrates networking, etc.
Facebook quote: Three years ago we started working with Intel to define the details of a new processor called Broadwell-D, part of Intel's Xeon line of processors, that was better suited to data center workloads rather than enterprise.
The first Xeon D (D-1540) was a low clocked (2.0 GHz base, 2.6 GHz turbo) power optimized Broadwell 8-core (16 thread) SoC with 45W TDP. Since then Intel has also released 12 and 16 core models with 45W and 65W TDPs. 16 core 45W model runs at 1.3 GHz (base) and 2.1 GHz turbo. If AMD is able to enter this market with Zen, they will sell a huge amount of chips. But power/watt is the most important factor in this market, and they must beat Intel to succeed.
Intel is selling their top of the line Xeon D 8-cores at ~600$. Xeon D profit margins seem to be significantly lower compared to top of the line i7 8-cores (6900K = ~1100$). It would be interesting to see what happens if AMD enters this market with Zen. Zen seems to be perfectly fit for this market. But AMD needs to integrate everything to the same SoC in order to be relevant. CPU alone isn't enough.
I don't know whether AMD can afford to allocate resources to that right now, but if I'm not mistaken, Naples is already an SoC (well, an MCM made-up of SoCs) with lots of PCIe lanes and two 10Gb Ethernet links, so it seems fairly well-suited to that job, provided that its power curve looks good at low clocks.
Beyond that, I'm sure AMD would be delighted to make a semi-custom SoC for Facebook/Google/Amazon/etc.
I wasn't thinking of a specific market, more of a value add to existing markets, gaming included.
AMD seemed to think there was value in adding in a custom audio accelerator in the way of Tenscilla DSP, however I would have thought a small x86 processor, bobcat for example, put on every gpu they manufactured would have been a better fit. They could have recommended devs use it to offload audio processing initially.
I thought about this a few years ago, with the two primary ideas being: 1) merging the volumes for APU and low-end discrete silicon in the face of rising costs and AMD's losing share in both and 2) providing a serial resource for certain heterogeneous compute situations where data transfer for discrete cards and the poor serial performance of the GPU side made even the strongest GPUs uncompelling.
However, it seems for point 1 that the justification did not arise. Perhaps this is in part due to the extra complexity, or costs not rising to that level or because the general slowdown in process nodes + rebranding was the reaction to the problem. Another possibility related to Jaguar or another core is that x86 in particular might incur special attention with AMD's WSA, and might have levied extra payments or restricted the choice of which foundries low-end GPU could be routed to.
The scenario for point 2 has generally just been ignored, perhaps to the detriment of AMD's HSA adoption.
There are apparent scenarios where some of this does occur, but typically it's more in the phone realm where AMD is a non-player rather than the power and cost ranges it is stuck in.
The DSP audio block may have been more important to AMD at the time for its co-development with the consoles and their ability to leverage the customizability of Tensilica's solutions and the inadequate latency/synchronization handling of GCN at the time, given how little impact or attention the PC space or AMD gave to discrete or AMD's implementations.
The shift to GPGPU with GFX8 and above at least in part comes from AMD figuring out the high-priority and CU reservation features. However, this is not a perfect mapping to what the DSP block offered. Perhaps the DSP TrueAudio was more limited than AMD wants to go, or the GPGPU method is kind of an over-engineered solution for the same types of load. A CU or the possibly larger number of CUs that are the minimum granularity for reservation, is much more silicon, power, and much more context to manage if the desired workload really was satisfied by the DSP blocks. Probably, a CU is also less amenable to customization.
Perhaps AMD is hoping its more generic interconnect will allow custom DSPs to show up without having to be given an architectural carve-out like TrueAudio did.
Isn't that kind of less virtualized than the old method that had software submit a workload and the GPU figured it out without giving any details?Specially when they can dedicate specific CU's count to this. ( as they have shown by the past ). something like virtualization inside the chip.
The creation of what looks like SMP on the same die due to the CCX structure seems to also indicate a focus on a more modest instancing per CCX, rather than shooting for a core arrangement that could get more ambitious.I don't know whether AMD can afford to allocate resources to that right now, but if I'm not mistaken, Naples is already an SoC (well, an MCM made-up of SoCs) with lots of PCIe lanes and two 10Gb Ethernet links, so it seems fairly well-suited to that job, provided that its power curve looks good at low clocks.
The rumor I remember hearing though was 4x1GbE for Zen (I hope I'm wrong), which is not really competitive - Xeon-D has 2x10GbE controllers on die.They have, PCI-E, south bridge(NVME and SATA no idea if it supports SAS), Network are all on Chip.
itsmydamnation
Veteran
Your 1 has lost its mate 0The rumor I remember hearing though was 4x1GbE for Zen (I hope I'm wrong), which is not really competitive - Xeon-D has 2x10GbE controllers on die.
")
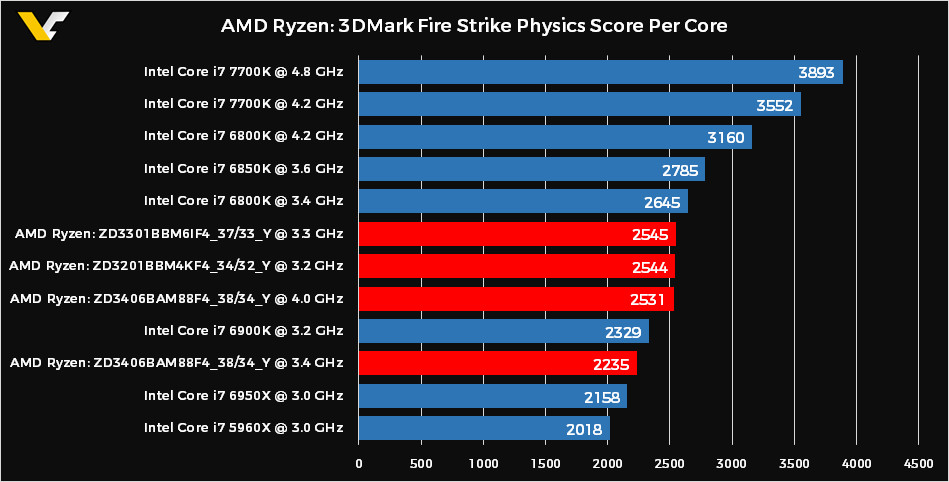
So what's with the physics score per core not changing for Ryzen between 3.2Ghz and 4Ghz?
Thoses are not the same processor (4 -6 and 8 cores ). they have divide the result score for each by the number of cores, hence why .
The problem wit this benchmark is it dont scale much by cores ( it is not a linear increase ), so defacto on this case, mhz are not counting much even if the 8cores have faster clock. If the benchmark had a linear increase by cores, result will be different.
You can look at the 10cores Intel 6950x .. you can see it dont scale well 2cores more even with lower clocks should be way faster than the 8cores 6900..
Anyway, it seems clock for clock that the Ryzen architecture is slighty faster single thread or not than the Intel counterpart.. if they OC well that could quickly become an Overclockers dream.
I someone doubt it yet, as it seems AMD have decide to decline their cpus range based on clock speed ( quadcore seems have lower clock speed than 6 and 8 cores.. ) but if AMD pull a quadcore at 4.2-4.4 ghz... i dont see how they can not been faster than the 7700K or anything can pull Intel witth their current architecture.
In reality Intel IPC have not much evolve thoses last generations, they are just clocked higher. In facto i have not change my CPU ( 6cores 4930K) ( quad channel DDR3 ) as performance gains was absolutely not relevant ( i can go up as high as 5.3ghz with it with my H2o). only an 8cores will be more interessant ( hence why i was starting to be interested by the 6900K.. but now, with Ryzen.... well you see what i mean )..
Edit:
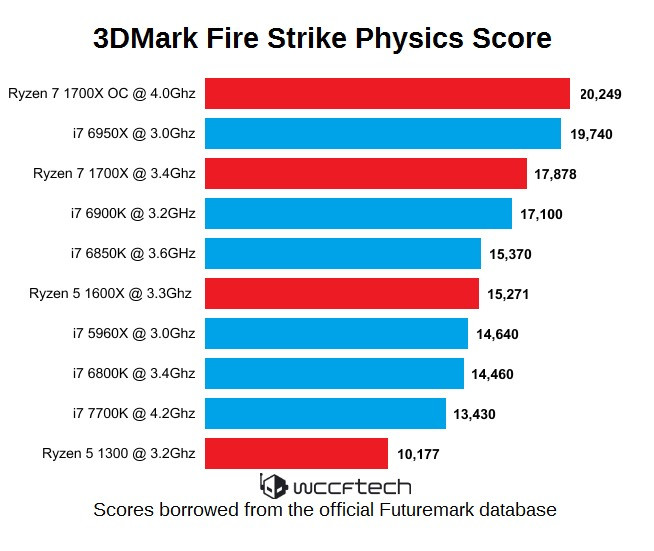
I was read some last benchmark ( cinebench ) and effectively if thoses scores are confirmed .. it seems that Ryzen is largely overpass Intel in IPC clock for clock performance.. the architecture seems way more effifcient.. meaning. a 3.8ghz Zen core will overpass a 3.8ghz Intel ( last generation ) ..without problem..
And when we start to compare price and tdp this even more impressive..
< 95W vs 140W ,,, price tag at 259$ vs 610+ $ .... ( 1600x vs 6850K 6 cores vs 6cores )
If thoses numbers are confirmed.. thats really refreshing ...
Last edited:
http://wccftech.com/intel-core-i7-7740k-core-i5-7640k-amd-ryzen/
Intel bumps high end desktop quad-core CPUs (both i5 and i7) to 112W. Immediately when we get competition, the TDP headroom gets used. Also rumors tell that the new i5 has hyperthreading. First time for quad core i5. Competition is a nice thing
In comparison all AMDs 4 core Ryzens are 65W. AMDs architecture seems to be designed for slightly lower clocks. This is great for 8/16+ core designs (servers) and low power quads (laptops), but they can't competete against Kaby lake's high clock rate (at 112W) on desktops and workstations. When TDP is no problem, Intel's 4.3 GHz 112W quad will beat AMD quads in every situation and six-core models in most cases. But the AMD 65W six/eight core will be drastically more power efficient than a quad core Intel 112W. Zen has definitely changed things
Intel bumps high end desktop quad-core CPUs (both i5 and i7) to 112W. Immediately when we get competition, the TDP headroom gets used. Also rumors tell that the new i5 has hyperthreading. First time for quad core i5. Competition is a nice thing
In comparison all AMDs 4 core Ryzens are 65W. AMDs architecture seems to be designed for slightly lower clocks. This is great for 8/16+ core designs (servers) and low power quads (laptops), but they can't competete against Kaby lake's high clock rate (at 112W) on desktops and workstations. When TDP is no problem, Intel's 4.3 GHz 112W quad will beat AMD quads in every situation and six-core models in most cases. But the AMD 65W six/eight core will be drastically more power efficient than a quad core Intel 112W. Zen has definitely changed things
Last edited:
AMD being the energy efficient part? what a time to be alive.
But AMD could take the same path and boost Ryzen TDP and clockspeed to stay close to Intel why offering more cores for the price. Also this Intel chips use the 2066 platform and will use Qchannel so I'm expecting a price deference not linear to the performance gain.
Also can someone please explain me how is that the turbo freq is the same as the base? I can't understand.
But AMD could take the same path and boost Ryzen TDP and clockspeed to stay close to Intel why offering more cores for the price. Also this Intel chips use the 2066 platform and will use Qchannel so I'm expecting a price deference not linear to the performance gain.
Also can someone please explain me how is that the turbo freq is the same as the base? I can't understand.
You would assume that. However Intel has been finetuning their architecture for many generations already, and Zen is AMDs first iteration of a brand new architecture. We should expect improved IPC and perf/watt in the next Zen iteration. Possibly also increased clock ceiling, if AMD sees desktops and workstations as a top priority.That remains to be seen, but Zen spends a bit less on per-thread performance and very high clock speeds, so it would make some sense for it to be slightly more efficient in highly-threaded applications, at the right clock speeds.
But first we will see APUs (2 and 4 cores + GPU). That allows AMD to get back into laptops. Desktops are a niche market nowadays.
Coffee Lake will introduce 6-core mainstream Intel processors: http://wccftech.com/intel-coffee-lake-2018-cpu-details/. There will also be 6-core models with iGPU.
It will be interesting to see whether Intel keeps their server/workstation 8-core pricing (1000$+) and intends to fight AMD 8-core Zen desktop CPUs with higher clocked Coffee Lake 6-core CPUs.
It will be interesting to see whether Intel keeps their server/workstation 8-core pricing (1000$+) and intends to fight AMD 8-core Zen desktop CPUs with higher clocked Coffee Lake 6-core CPUs.
Similar threads
- Replies
- 70
- Views
- 13K
- Replies
- 90
- Views
- 18K
- Replies
- 220
- Views
- 92K