Sorry, but I don't see how divergence is directly related to warp swapping (though there may be secondary reasons)
You introduced the 2-way model of ARM, so I contrasted it with the 2-way models in R600 and G80, neither of which works in the way ARM does (or at least what I understand of ARM from your description: the code contains a predication flag per instruction to indicate paths). In order to entirely skip instructions the GPUs have to evaluate the predicate for the batch as a whole.
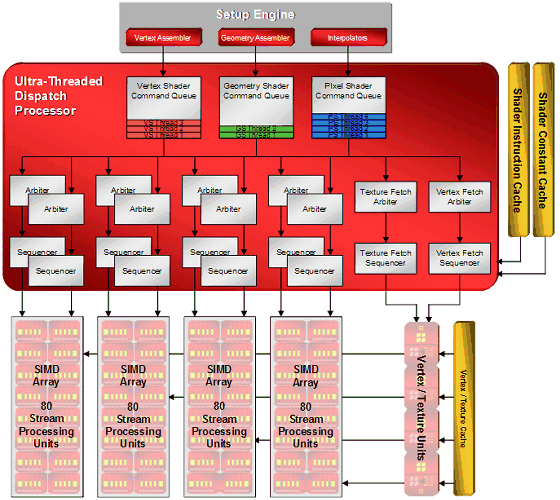
R600 has to do a batch swap to perform this evaluation - the sequencer unit that does this is outside of the ALU pipe.
The compiler for G80 serialises a branch if it's short. This implies to me that G80 evaluates the predicate status for the entire batch within the ALU pipe and flushes the pipe once it determines the clause no longer contains instructions to be executed. In effect this evaluation is only compiled if the clause is long enough for it to be worth flushing.
: if some threads don't take a branch while others do, then then the processor can simply continue executing the threads that don't branch. No need to swap the warp.
I can see why it could beneficial to swap a warp to avoid a bubble, but that would be a consequence of the VLIW instruction set and not of the SIMD nature.
R600 has an explicit "swap now" compiled into its assembly code.
Thinking about it, G80 may be simply flushing the pipe and jumping. This presumes that the operands required by the new instruction are ready. I can't help thinking that these operands cannot be guaranteed to be ready, which would then force a batch swap.
I'm more interested in the low level bookkeeping. Do you see fundamental flaws in my suggested implementation? At first, I thought some kind of divergence stack would be needed to unwind different levels of divergence, but now I don't think that's necessary. (In case of subroutines, you obviously still need a stack, but that's orthogonal.)
Let's ignore explicit predication, since that's trivial anyway, and only look at real divergent branches.
OK.
At the assembly level, you always know what the next instruction to execute will be so, knowing that, isn't it indeed just not a matter of temporarily deactivating a thread until the program counter passes the reactivation mark? Seems really straightforward. I have the feeling that my example would break down in some really stupid case, but I can't pinpoint what as long as you can guarantee that there always will be, eventually, as point of reconvergence. (Only a restriction if you want to support setjump/longjump like behavior.)
I'm not sure if you're referring to instruction-paging here (not sure if it's relevant)...
Interesting. Free-wheeling now: that seems to indicate that they control divergence globally per warp instead of per thread, with a stack that's 16 deep and 16 wide. If indeed the instructions themselves determine whether or not it's a nesting/predication barrier, then that's all you need. In my system, things would be distributed per thread, each having their own 32-bit wide barrier activation toggle pointer + their own logic to calculate the next toggle pointer. Conceptually, I'd think my system is simpler, but maybe not if you want to avoid bubbles...
I'm still trying to understand what you're suggesting: are you suggesting that each object has its own address pointer, set to the address of the instruction it is due to execute next?
Well, for what it's worth, G80 appears to bubble, so bubbling would be a match for the system you're describing.
Edit: one possible reason to go the stack way is that it's less area. I only realized later that you need such a stack per warp, not per multi-processor. So in one case you have threads_per_warp^2 bits per warp,
It needs to be the nesting level not squared.
while in the other you'd need threads_per_warp*address_width. Could be significant enough when you're dealing with thousands of warps.
In G80 each multiprocessor can only support a maximum of 24 warps (each of 32 objects). Alternatively 48 warps of 16 objects when vertex shading, I presume.
In R600 all we know is that there's a vague "low-hundreds" of batches, but I'm not aware of anything more specific. R5xx is 128 batches per SIMD, I can't think of any reason why it'd be different in R600. I expect they both share the same predication system for branching.
CTM documentation for R5xx says that nesting is upto 32 deep, but only 64 batches per SIMD are supported. Otherwise nesting is limited to 6 deep (but subroutines and loops are not supported in this mode). I wasn't aware of these modes until now...
Jawed
") ), today it's a SIMD array of scalar ALU's. The terminology we use today is completely in line with the language used in the past so I don't understand the complaints.....
), today it's a SIMD array of scalar ALU's. The terminology we use today is completely in line with the language used in the past so I don't understand the complaints.....