CDNA 2 did not exist in 2020, too. Oak Ridge knew what nVidia will bring to the market. They have decided to go with a less advanced infrastructure.Seriously, you need to fix your hostility.
Slingshot interconnect launched in 2020 was definitely not outdated when they specced Frontier and the nodes it uses. Optical NVLink was nowhere near ready when those systems were specced.
Install the app
How to install the app on iOS
Follow along with the video below to see how to install our site as a web app on your home screen.
Note: This feature may not be available in some browsers.
You are using an out of date browser. It may not display this or other websites correctly.
You should upgrade or use an alternative browser.
You should upgrade or use an alternative browser.
Nvidia Hopper Speculation, Rumours and Discussion
Yes, they knew, and they still chose what AMD and HPE had on offer. Not only would have NVLink delayed the project, it might not have been available at all without going full NVIDIA, which they clearly didn't want to do.CDNA 2 did not exist in 2020, too. Oak Ridge knew what nVidia will bring to the market. They have decided to go with a less advanced infrastructure.
DavidGraham
Veteran
They rushed the super computer out the door, likely at a great discount from AMD, and the results speak for itself, A single H100 wipes the floor with several "MI250" that are only good for compute density but suffer from severe suboptimal performance at the card level (it's just two GPUs stitched together) and at the bigger scale, due to the slower interconnect .. almost nobody else is using MI250, while A100s and H100s are used left and right everywhere else.Yes, they knew, and they still chose what AMD and HPE had on offer. Not only would have NVLink delayed the project, it might not have been available at all without going full NVIDIA, which they clearly didn't want to do.
Yeah, only three MI250X systems in Top10 at Top500 list. That's still one more than A100, no H100's in sight. NVIDIA does have couple GV100's there too though.They rushed the super computer out the door, likely at a great discount from AMD, and the results speak for itself, A single H100 wipes the floor with several "MI250" that are only good for compute density but suffer from severe suboptimal performance at the card level (it's just two GPUs stitched together) and at the bigger scale, due to the slower interconnect .. almost nobody else is using MI250, while A100s and H100s are used left and right everywhere else.
HPCG list is incomplete because it hasn't been run on all the systems, but still MI250X fits in top 3 spot.
as usual you provide regular bullshit.They rushed the super computer out the door, likely at a great discount from AMD, and the results speak for itself, A single H100 wipes the floor with several "MI250" that are only good for compute density but suffer from severe suboptimal performance at the card level (it's just two GPUs stitched together) and at the bigger scale, due to the slower interconnect .. almost nobody else is using MI250, while A100s and H100s are used left and right everywhere else.

Frontier Testing and Tuning Problems Downplayed by Oak Ridge - High-Performance Computing News Analysis | insideHPC
Everything about the Frontier supercomputer, the world’s first exascale system residing at Oak Ridge National Laboratory, is outsized: its power, its scale and the attention it draws. In HPC circles, the attention and talk have increasingly focused on performance problems as the lab gets the...
 insidehpc.com
insidehpc.com
DavidGraham
Veteran
Nvidia coprocessors can be found in 154 of the TOPP500 supercomputers; only seven of the supercomputers are using AMD Instinct cards.Yeah, only three MI250X systems in Top10 at Top500 list.

ISC ’22: The AMD-Intel-Nvidia HPC race heats up
At the International Supercomputer Conference, processor rivals AMD, Intel, and Nvidia talk up recent successes, future plans.
 www.networkworld.com
www.networkworld.com
Good PR. Just try to read between the lines though.Frontier Testing and Tuning Problems Downplayed by Oak Ridge - High-Performance Computing News Analysis | insideHPC
Everything about the Frontier supercomputer, the world’s first exascale system residing at Oak Ridge National Laboratory, is outsized: its power, its scale and the attention it draws. In HPC circles, the attention and talk have increasingly focused on performance problems as the lab gets the...
Whitt declined to blame most of Frontier’s current challenges on the functioning of the Instinct GPUs. “The issues span lots of different categories, the GPUs are just one.”
“A lot of challenges are focused around those, but that’s not the majority of the challenges that we’re seeing,” he said. “It’s a pretty good spread among common culprits of parts failures that have been a big part of it. I don’t think that at this point that we have a lot of concern over the AMD products. We’re dealing with a lot of the early-life kind of things we’ve seen with other machines that we’ve deployed, so it’s nothing too out of the ordinary.”
D
Deleted member 2197
Guest
Why just link the article he submitted? They are definitely having HW failure issues every few hours and is something I doubt they anticipated when the system was planned.as usual you provide regular bullshit.
Frontier Testing and Tuning Problems Downplayed by Oak Ridge - High-Performance Computing News Analysis | insideHPC
Everything about the Frontier supercomputer, the world’s first exascale system residing at Oak Ridge National Laboratory, is outsized: its power, its scale and the attention it draws. In HPC circles, the attention and talk have increasingly focused on performance problems as the lab gets the...
D
Deleted member 2197
Guest

All-AMD Powered & World's First Exascale Supercomputer, Frontier, Has Been Running Into Issues Ever Since It Powered On
The all AMD-powered & world's first exascale supercomputer, the ORNL Frontier, has been running into issue ever since it powered on.
The ORNL Frontier boots up but can only produce a maximum of 1 FP64 ExaFLOPS, whereas the system was designed to deliver 1.685 FP64 ExaFLOPS. While no word has been given regarding the specific issues, a few rumors are coming to light.
So now it turned from A100 and H100 to "Nvidia coprocessors" already?Nvidia coprocessors can be found in 154 of the TOPP500 supercomputers; only seven of the supercomputers are using AMD Instinct cards.
ISC ’22: The AMD-Intel-Nvidia HPC race heats up
At the International Supercomputer Conference, processor rivals AMD, Intel, and Nvidia talk up recent successes, future plans.
Might have bolded other part too, you know, the one he specifes that majority of issues aren't GPU related. Or that they'd have concerns about the AMD hardware part of the puzzle.Good PR. Just try to read between the lines though.
DavidGraham
Veteran
The original statement is almost no one is using MI250, there are only 7 machines using it, and two of them are DOE ones (and having major problems), vs dozens of NVIDIA V100, A100 and H100. Heck the announced H100 ones already outnumber MI250 despite being released 2 years ago.So now it turned from A100 and H100 to "Nvidia coprocessors" already?
Don't have to, it's already PR crap, the fact of the matter is, the machine is having trouble due to the GPUs and the Interconnect, they have already downgraded the original performance target by 40%, GPU/interconnect problems are responsible for that, as the bulk of the performance relies on them, then there are the constant failures every day, the interconnect plays a major part in this too.Might have bolded other part too
Last edited:
Grace-Hopper Superchip Whitepaper: https://resources.nvidia.com/en-us-grace-cpu/nvidia-grace-hopper?ncid=so-twit-569967
NVLink C2C enables applications to oversubscribe the GPU’s memory and directly utilize NVIDIA Grace CPU’s memory at high bandwidth. With up to 512 GB of LPDDR5X CPU memory per Grace Hopper Superchip, the GPU has direct high-bandwidth access to 4x more memory than available with PCIe. Combined with NVIDIA NVLink Switch System, all GPU threads running on up to 256 NVLink-connected GPUs can now access up to 150 TB of memory at high bandwidth. Fourth generation NVLink allows accessing peer memory using direct loads, stores, and atomic operations, enabling accelerated applications to solve larger problems more easily than ever.
DegustatoR
Legend

NVIDIA Grace Hopper Superchip Architecture In-Depth | NVIDIA Technical Blog
The NVIDIA Grace Hopper Superchip Architecture is the first true heterogeneous accelerated platform for high-performance computing (HPC) and AI workloads. It accelerates applications with the…
 developer.nvidia.com
developer.nvidia.com
I'm confused, what exactly is new in async copy interleaved with compute threads?Found this comparision interesting:
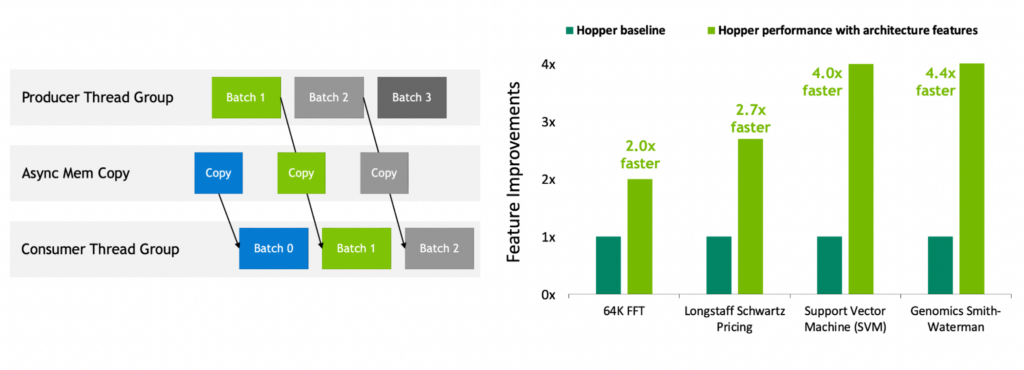
Shows how far ahead nVidia really is with their hardware. The problem today is not compute performance. That is cheap. But how to make use of it is the biggest obstactle.
TopSpoiler
Regular
From the Hopper Architecture In-depth article:I'm confused, what exactly is new in async copy interleaved with compute threads?
Asynchronous execution
The NVIDIA Hopper Architecture provides new features that improve asynchronous execution and enable further overlap of memory copies with computation and other independent work, while also minimizing synchronization points. We describe the new async memory copy unit called the Tensor Memory Accelerator (TMA) and a new asynchronous transaction barrier.
So tl;dr (thoroughly, just quick browse read on (hopefully all) relevant parts) it's just better at it than before especially when Tensor Cores are used?From the Hopper Architecture In-depth article:
The difference would however suggest that it's "everything off vs everything on" instead of "everything last gen had vs everything hopper has" on the graph.
TopSpoiler
Regular
TMA is dedicated hw for address generation and mem copy operation.So tl;dr (thoroughly, just quick browse read on (hopefully all) relevant parts) it's just better at it than before especially when Tensor Cores are used?
The difference would however suggest that it's "everything off vs everything on" instead of "everything last gen had vs everything hopper has" on the graph.
TopSpoiler
Regular

NVIDIA H100 80GB PCIe Hands on CFD Simulation
We take the NVIDIA H100 80GB PCIe card for a spin with a FluidX3D CFD simulation tool to see how the new card performs
 www.servethehome.com
www.servethehome.com
TopSpoiler
Regular
The Green 500 should use HPCG metric or provide the separate list that uses HPCG metric like the Top 500.