Install the app
How to install the app on iOS
Follow along with the video below to see how to install our site as a web app on your home screen.
Note: This feature may not be available in some browsers.
You are using an out of date browser. It may not display this or other websites correctly.
You should upgrade or use an alternative browser.
You should upgrade or use an alternative browser.
The slide concerning shadow tags explains how AMD handles the extra communication needed to snoop the L2s since the L3 cannot serve as a filter. The shadow tags are a mirror of the L2 tag arrays distributed amongst the L3 slices, which in itself would still incur a significant cost. The tag check is serialized with a 32-way comparison of a small number of bits in the shadow tags, then a secondary check on the tags that are potential hits.
It states 76% power savings, although it doesn't say how many bits are compared and I'm curious if this is an average that smooths out the power consumption of whatever worst-case match there is.
That remaining 24% power consumption would still be an increment above if the L3 were inclusive and it served as a snoop filter, but perhaps AMD saw performance or power gains in freeing up the L3 capacity.
It states 76% power savings, although it doesn't say how many bits are compared and I'm curious if this is an average that smooths out the power consumption of whatever worst-case match there is.
That remaining 24% power consumption would still be an increment above if the L3 were inclusive and it served as a snoop filter, but perhaps AMD saw performance or power gains in freeing up the L3 capacity.
Precisely Keller himself stated as the main reason that K12 would be the most performant one (among both designs), because they could get rid of the X86 decoding.
Since they scraped skydrive, they become silent about K12, yep
Yeah I remember Keller saying that K12 would be faster than Ryzen.
Now that Ryzen is done I hope AMD finds a way to continue K12's development and release it in the not so distant future.
An ARM CPU that is faster than x86 and compatible with standard AM4 motherboards would be very interesting and would put AMD in an unique position compared to everybody else.
It shouldn't be too hard to turn that into an ARM chip by replacing the instruction decoder I guess.
The decoder would be one element, but replacing it would be insufficient since it doesn't govern a lot of the behavior of the CPU or the architecture.
The virtual memory system doesn't necessarily mesh, so the TLBs would need to change. The instruction TLBs are in the branch prediction pipeline, although if they are somewhat abstracted perhaps this can avoid replumbing the whole predictor block. This might serve to abstract away the TLBs from the Icache, which may be taking physical addresses out of the predictor--although that might be tweaked if one architecture bumps up the bit count there.
The data TLBs and load/store subsystem have reason to change. The TLBs need to, although I suppose K12 might be able to live with the stricter requirements of the x86 memory queues. That might leave some changes off the table, although more relaxed may have trade-offs.
The AGUs or their equivalents would behave differently, the flags generated in the pipelines would have substantial similarities without fully matching. The FP pipeline would have some notable disagreements.
I suppose there could be some generalization of the low-level details so that the schedulers and other pipeline elements might be more interchangeable, but alternately it may be that AMD built different versions of the same block, with some blocks related to processor control and microcode being significantly different.
That remaining 24% power consumption would still be an increment above if the L3 were inclusive and it served as a snoop filter, but perhaps AMD saw performance or power gains in freeing up the L3 capacity.
I don't think the cost is as high as you make it seem. With an inclusive L3, aggregate cache capacity would be 8MB instead of 10MB. Since each L2 is 8-way set-associative, an inclusive L3 would have to be at least 32-way set-associative to avoid false evictions. The L3 in Zen is 16-way set associative, so they end up having to check 48 tags instead of 32 on a snoop.
Also, the way I read it, AMD has optimized the checking of shadow tags for power, so the checking of the 32-way shadow tags only takes 24% the power of a normal 32-way parallel tag-comparator. They do this, by first having a 32-way comparison of a small number of the tag bits (say... four), and then check the subsequent positive candidates for hits.
This two-stage tag comparison is obviously slower than a full 32-way comparator, but if you hit, you get to read out from a L2 with its shorter access-time (so total time ends up being at least as fast as an inclusive L3). On a miss, the probing agent would have to get the data from a different CCX or from DRAM where the added .3 or .6ns is in the noise.
Cheers
TLBs would be easy. The ARM v8 supports one of 4, 16 or 64KB pages sizes. Which one is implementation specific, AMD could just roll with 4KB pagesThe data TLBs and load/store subsystem have reason to change. The TLBs need to, although I suppose K12 might be able to live with the stricter requirements of the x86 memory queues.
although I suppose K12 might be able to live with the stricter requirements of the x86 memory queues.
AMD could just use the strong memory ordering model of x64 in their ARM v8 implementation, wrt. correctness it is a superset. It takes a lot of hardware to make a strong memory ordering model fast, but once you do it is as fast as a weak memory ordering model (because hardware knows more at runtime about fencing hazards than a compiler at compile time). The question is if a ARM v8 implementation would be better off with a custom, cheaper, LS unit and spend the silicon elsewhere.
AFAICT address generation of x64 is a superset of ARM v8. In ARM you have the following address generation rules: base, base+index, base+scaled index and PC relative modes.The AGUs or their equivalents would behave differently, the flags generated in the pipelines would have substantial similarities without fully matching
The only problems are the index modes with pre and post increment. Here you have instructions generating two results (ie. the loaded value and the updated base register). There are also instructions that pop two values off the stack. This doesn't mesh well with a an execution engine where each op generates one result. These instructions would have to be cracked in two.
Cheers
It's a trade-off AMD made differently than Intel, given the choice to make the L2 large enough that a backing L3 could get away with lower associativity.Since each L2 is 8-way set-associative, an inclusive L3 would have to be at least 32-way set-associative to avoid false evictions.
I guess AMD felt emphasizing the L2 was a win for them.
The line is "76% less power than accessing L2 tags directly", which I interpret as a description of the whole shadow tag check process versus broadcasting to all 4 L2s and checking them.Also, the way I read it, AMD has optimized the checking of shadow tags for power, so the checking of the 32-way shadow tags only takes 24% the power of a normal 32-way parallel tag-comparator. They do this, by first having a 32-way comparison of a small number of the tag bits (say... four), and then check the subsequent positive candidates for hits.
This would mean the savings come out of a hypothetical total of 32 tag comparisons and the costs of the snoop broadcasts+responses across the center of the CCX and going through the L2 interfaces. That baseline is more expensive energetically than a plain 32-way comparison, which is where this might add more consumption absent gains this arrangement enables elsewhere.
This may or may not be true, based on the status of the L2 line, and perhaps based on the line's history of sharing. AMD's L3 apparently retains the old behavior from prior generations where it's mostly a victim cache until it decides to retain lines it determines are being frequently shared between cores.This two-stage tag comparison is obviously slower than a full 32-way comparator, but if you hit, you get to read out from a L2 with its shorter access-time (so total time ends up being at least as fast as an inclusive L3).
Their behaviors are somewhat different. For example, Zen supports PTE coalescing like ARM V8 does, but they don't settle on the same size.TLBs would be easy. The ARM v8 supports one of 4, 16 or 64KB pages sizes. Which one is implementation specific, AMD could just roll with 4KB pages
That would be part of what is left on the table. The depth and number of buffers/queues would be affected by how expensive they are.AMD could just use the strong memory ordering model of x64 in their ARM v8 implementation, wrt. correctness it is a superset. It takes a lot of hardware to make a strong memory ordering model fast, but once you do it is as fast as a weak memory ordering model (because hardware knows more at runtime about fencing hazards than a compiler at compile time).
More outstanding accesses might be possible if the constraints on checking them are relaxed. On the other hand, a strong pipeline makes cases with synchronization cheaper and more consistent than a broader L/S system that needs heavyweight fencing.
digitalwanderer
Legend
Ok, so there is a bright side!Windows 8 won't work with Ryzen!
That doesn't sound like a good compromise... The number of memory instructions needing synchronization in common code base is several orders of magnitude smaller compared to basic load/stores. Faster and more energy efficient loads & stores are more important than faster release/acquire atomics/barriers. x64 memory model is too strict. ARMv8 memory model is very well balanced.That would be part of what is left on the table. The depth and number of buffers/queues would be affected by how expensive they are.
More outstanding accesses might be possible if the constraints on checking them are relaxed. On the other hand, a strong pipeline makes cases with synchronization cheaper and more consistent than a broader L/S system that needs heavyweight fencing.
Herb Sutter's presentation (from a few years ago). 0:54-> talks about ARMv8 (vs x64, POWER, ARMv7):
https://channel9.msdn.com/Shows/Going+Deep/Cpp-and-Beyond-2012-Herb-Sutter-atomic-Weapons-2-of-2
I am not a hardware engineer, but my educated guess is that looser memory model (reordering loads and stores) would affect many places in the OoO machinery. Keller saying that K12 has better performance than Zen would point out to the direction that AMD planned to customize the chip to take advantage of the looser ARMv8 memory model.
Last edited:
digitalwanderer
Legend
They do make square waffles, it all depends on what waffle iron you use.
Btw wouldn't make sense to tried to make square waffles? the amount of area lost in circular ones is huge.
Same principle why trees are round (mostly) a wafer is round. It's a crystal, it grows from the center outwards.
This may depend on what workloads are part of the set. Zen and K12 are ranging from consumer to HPC and high(er) end servers.That doesn't sound like a good compromise... The number of memory instructions needing synchronization in common code base is several orders of magnitude smaller compared to basic load/stores.
The mix of synchronization and the scale in terms of software complexity and core andsocket counts can vary significantly.
That K12 was meant to be a sibling to Zen also means that there is a desire to transfer applications or knowledge built on a strongly-ordered architecture to a weaker one, which brings in some thorny issues.
The other direction is easier since it might just mean the core ignores something.
x86 is dominant in much of the server space. Power is weaker, although even it has taken on stronger semantics in recent iterations, and the big-iron Z-arch is strongly ordered as well.
That's more of a target market concern for K12, although at this point we may not see it where Zen is going.
The other question, which might be addressed in the Sutter video, is the question of what the hardware actually does when it encounters a barrier or the acquire/release operations. Once I am able to watch it, it might go into detail. In the past, such events could severely constrain parallelism by forcing pipeline drains or more global stalls, and even if sections that need synchronization are 1-2 orders of magnitude fewer in static count, the dynamic count can shift. Also, aggressively OoO cores like Zen and K12 can host over 100 memory operations in their buffers--with some that can be speculated past a barrier. How the L/S pipeline reacts can drastically change the cost of the operations despite their rarity, particularly if a design's speculative capability means the probability of having at least one barrier in-flight goes to 1.
ARM V8's method might constrain the cost, although it seems like it wants to scale from some relatively conservative cores to the high-end like K12. An in-order little core with limited speculation has a lower peak to drop from in terms of parallelism and speculation, and a small L/S pipeline tied to a simple hierarchy won't consider a drain as prohibitive as a 72+44 OoO pipeline.
Another synchronization difference, as noted is that Zen (AMD64 in general?) keeps its Icache coherent, whereas ARM does not.
The memory pipeline is one area where I considered the possibility where the "engine" could be bigger. The decoder could be wider, up to the uop issue width. The actual growth in processor width may become gated by the renamer rather than the decoder.I am not a hardware engineer, but my educated guess is that looser memory model (reordering loads and stores) would affect many places in the OoO machinery. Keller saying that K12 has better performance than Zen would point out to the direction that AMD planned to customize the chip to take advantage of the looser ARMv8 memory model.
One item about OoO machinery is that it also affects things in the other direction. The looser memory model makes changes in the other's behavior more clear, if it doesn't try to hide it.
I would have liked to have seen Zen and K12 if the memory pipeline was less restricted. There would have been no better way to compare the benefits and limitations of the two schools of thought than a design with the same implementation competence, overall philosophy, and design targets.
It's a result of how the wafer is created. The wafer must be one large silicon crystal, which is created by starting from from a seed in a vat of molten silicon and slowly growing it outwards.Btw wouldn't make sense to tried to make square waffles? the amount of area lost in circular ones is huge.
The natural tendency would be to grow out equally in all directions since there's no particular way that the atoms care about corners.
However, a sphere doesn't give consistently-sized 2d surfaces, so instead the crystal is slowly lifted so that the sphere stretches into a cylinder.
It's worth losing the area to get an affordable mass-produced ultrapure giant crystal of silicon, versus the expense and likelihood of failure trying to make silicon do something it does not want to do.
In general i dont post things from this site, but well.
Ryzen 7 1700x cpumark benchmarks. ( we dont know if the boost was enabled )... Looking good except 2 benchmarks: Prime numbers and Physics.. but looking at it, i really think that thoses 2 scores have bugged. ( looking the nature of both benchmarks, i dont see why it will be so low ).
http://wccftech.com/amd-ryzen-7-1700x-389-8-core-cpu-benchmarks-leaked/








Ryzen 7 1700x cpumark benchmarks. ( we dont know if the boost was enabled )... Looking good except 2 benchmarks: Prime numbers and Physics.. but looking at it, i really think that thoses 2 scores have bugged. ( looking the nature of both benchmarks, i dont see why it will be so low ).
http://wccftech.com/amd-ryzen-7-1700x-389-8-core-cpu-benchmarks-leaked/
Last edited:
Videocardz found some other results to compare with where the intel counterparts performs better - so dunno if both sites cherry picked in opposite directions... Most of videocardz' are marked PT8 though, ie from the previous version of the test, but that should mean lower results
edit, these are simply the 7 latest supposely stock clocked PT9 6900k results i could find in the db - quite a bit of variation, and looks like wccf and videocardz indeed are at each end of the spectrum
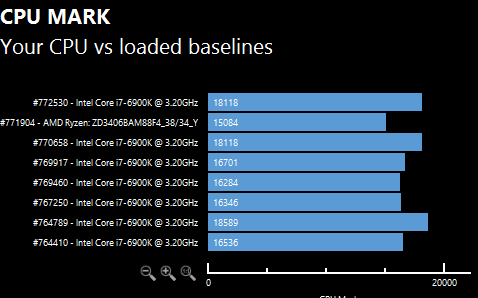
(and we still don't know if #771904 is legit or which actual clocks)

edit, these are simply the 7 latest supposely stock clocked PT9 6900k results i could find in the db - quite a bit of variation, and looks like wccf and videocardz indeed are at each end of the spectrum
(and we still don't know if #771904 is legit or which actual clocks)
Last edited:
digitalwanderer
Legend

The image is a photoshopped one ( not quite sure about the message behind anyway ).Original image with Raja about the new AMD coolers for Ryzen


Similar threads
- Replies
- 85
- Views
- 17K
- Replies
- 90
- Views
- 18K
- Replies
- 220
- Views
- 93K