Yes, that's correct. AMD specifically stated the fact, that a good compiler for GCN is much easier to write than for the VLIW architectures, as a distinct advantage of the new architecture in their presentation.I had to diverge and google search some of the terms you used (round robin , So really what AMD did here is add to their scheduling capabilities to increase their ALU utilization rate , and If I understood your post correctly , the compiler has less to work for now (now that clauses are gone) .
Edit:
Hiroshige Goto did a good job drawing a diagram visualizing the round robin scheduling. The picture only shows the instructions for the vector ALUs, putting all existing issue ports in makes it probably a bit convoluted when you also introduce a time axis like he did. The pictures from the AMD's architecture presentation show all ports, but not how it works with the round robin issue, so basically one would have to put both together to get the complete picture.
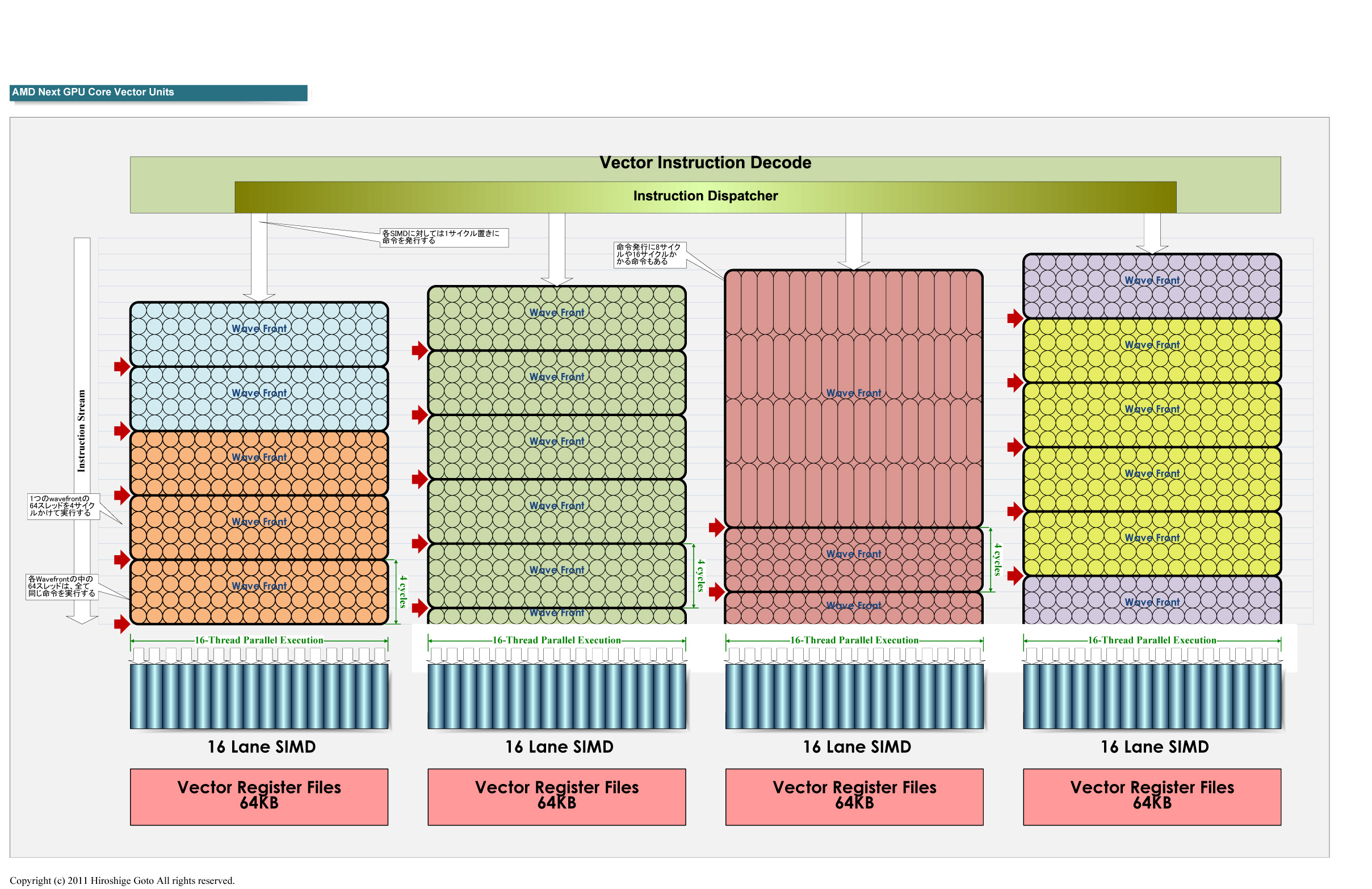
The issue basically "moves" each clock cycle to the next vec16 ALU (SIMD engine), after 4 cycles it starts over at the beginning. Each small circle in one of the rectangular blocks represents one element of a wavefront, the block itself an instruction for the whole wavefront. The elongated ellipses stretching over 4 cycles represents an instruction which takes longer (double precision or transcendental for instance, in this case 4 times as long, but can also be something else as AMD stated half rate DP will be possible in some models).
That is very dependent on the code you run.In a hypothetical reality , how much more performance does a GCN core (with 1532 ALUs @880 MHz) achieve over a Cayman core running at the same frequency and with the same number of ALUs ?
Starting from a few corner cases, where it may be slower than Cayman (the minimum would be half speed, but extremely unlikely), I would guess it's maybe 20% faster for code showing good (not perfect, that would be a draw) utilization (and not much fine grained control flow) on the old VLIW architecture with the extreme being a speedup by a factor of 10 or so (again extremely unlikely).
I would guesstimate the average speedup of the shader performance (you can only say something about this isolated issue, not about the game performance) over a wide range of code (which is not memory access limited) is a speedup of the pure shader performance by maybe 30 to 40% compared to Cayman.
AMD restructured the memory hierarchy too, now there is a real read/write L1 like Fermi has (but the local memory is separated, AMD unified the general purpose L1 with the Texture L1 which is still separate in nvidia's designs). But I have no idea how this works out for the performance side of things.
Last edited by a moderator:
")