Orion
Regular
Games are not designed to take advantage even of average speed nvmes, it's as if nvmes do not exist. They load no faster than sata ssd.Nobody said devs were lazy. You program for the hardware that's common...
System RAM is vastly faster in both transfer rates and latency than PS5's SSD... So Cerny can be right that there ARE bottlenecks (because of course there are) but it can ALSO be right that games simply aren't being designed atm to take advantage of the fastest NVMe drives and most certainly not RAMdisks.
Even pc exclusives, like star citizen, that are designed taking in mind nvidia titans and ssds in their recommendations, do seem to ignore nvmes too... how strange. Or maybe it is not that they are ignoring but that they can't do anything about the bottlenecks.
Laziness or an inability to realize a benefit from current PC hardware are the only two possibilities that come to your mind? You don't think current-gen consoles and many PCs not having SSDs has had an effect on developers choice to not push the envelope further on the use of streaming in their engines up to now?
There are games that have an ssd speed up substantially faster than any other game benefits from ssd. So they are taking advantage of ssds, and have optimized heavily for it, which is why they substantially exceed all other games in the market in terms of loading. Yet even these games load no faster in nvmes than in sata ssds.
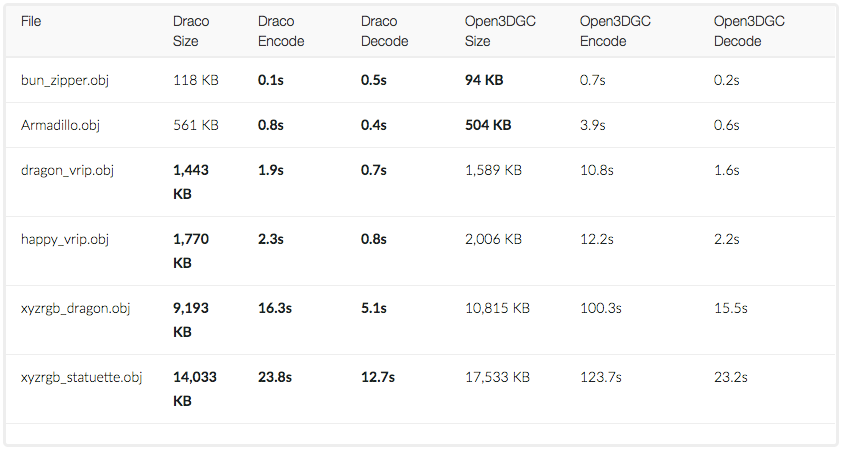
")
