Jawed
Legend
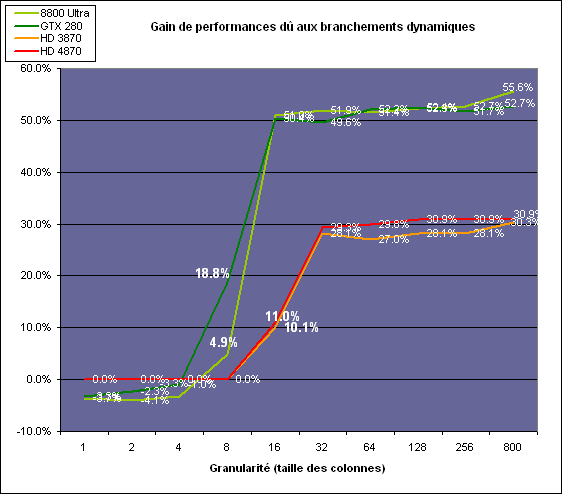
Trouble is "as much as you'd expect" is ill-defined - clearly G92's extra ALUs and TMUs are bringing a useful performance gain:That's precisely my point. When setup, fillrate, and BW are equal, game performance isn't affected as much as you'd expect by having double the ALU and TEX. Adding only ALUs will have an even smaller effect.
http://www.xbitlabs.com/articles/video/display/asus-en9600gt_12.html#sect3
(note: G92 here has a 10% more bandwidth than OC'd 9600GT)
http://www.computerbase.de/artikel/...hd_4850_rv770/20/#abschnitt_performancerating
Though at the same time I personally feel that 50% extra performance is the lowest margin one should pay for when choosing between GPUs.
The point about GT200b is that in comparison with G92b, setup, fillrate and BW will all increase. So when I propose adding ALUs (and TMUs) to G92b (and not forgetting the prodigal MUL and improved efficiency of GT2xx texturing) it's alongside other basic gains in capability.
I'm really intrigued to see what happens with NVidia's ROPs when they get ~double the bandwidth per ROP. They should fly - they've long been strangled by GDDR3.
NVidia can't lower the ALU:TEX ratio. And don't forget attribute interpolation "silently" consumes some ALU capability - so you can't do a direct comparison with ATI's ALUs/mm.Again, exactly my point. I don't think adding math to G92b (or, almost equivalently, chopping everything else from GT200) will do much.
The problem being that G92 is held back by not having enough BW per ROP. Don't forget it nominally has twice RV770's per clock Z rate.You do realize that a few sentences before this you attributed G94's speed to its ROPs/BW, right?
If 16 ROPs are useful to a 4 cluster GPU, you can't say 32 ROPs are excessive for a GPU with 10 even faster clusters.
")
So G94 with 128-bit GDDR5 and 8 ROPs, with twice the bandwidth per ROP, would prolly have been a really nice, and small, thing. Trouble being, of course, the timing of GDDR5.
I'm not sure what you're saying here - both GPUs would have the same per-clock colour rate, while GT200b would have twice RV770's Z-only rate.You can be sure that GT200 would take a hit with half the ROPs, and likewise RV770 would be notably faster with double the ROPs.
Though, per-Z/per-clock, NVidia's ROPs appear to need an overhaul, even after GDDR5 arrives as MSAA performance seems a bit lacking. Maybe, in adjusting to the burst length of GDDR5 (which is presumably non-trivial), NVidia can get a bump in per-ROP efficiency here?
GT200's increased performance per TMU indicates NVidia was using an excess of units in G8x/G9x to attain desired performance.There's no easy fix here. These adjustments that you're suggesting will change perf/$ by a few percentage points at best. NVidia didn't really make any mistakes in the balance between the execution units. RV770 simply raised the bar on how good each part of a GPU -- TMU, ROP, MC, ALU, TEX, scheduling, etc -- can be for a given silicon budget.
GT200's increased per-ALU performance with increased register-file size per SIMD indicates that G8x/G9x had too little register file.
NVidia increased the size of batches, which cut the cost of scheduling/operands in GT200 - again it seems NVidia made the batches too small in G8x/G9x - though there are other issues there...
We'll see a similar thing when NVidia introduces GDDR5 - the "excess Z-rate per ROP" will get utilised more effectively.
Jawed