Nebuchadnezzar
Legend
This is quite big news, Samsung gets customers to fill their manufacturing capacity and STM gets top-notch node process, it will be quite a hit if the A9600 would be manufactured on it.
Follow along with the video below to see how to install our site as a web app on your home screen.
Note: This feature may not be available in some browsers.
This is quite big news, Samsung gets customers to fill their manufacturing capacity and STM gets top-notch node process, it will be quite a hit if the A9600 would be manufactured on it.
Dedicating resources to ST-E while Apple's capacity needs are still growing very well might suggest that Apple is preparing to shift some of that production away from Samsung in the fairly near term.

http://www.stericsson.com/press/ST-Ericsson_Pressbackgrounder_Smartphones.pdfBut Mali is in a position to gain share by way of smartphone application processors in the recent Samsung Exynos 4212 and 4412 and ST-Ericsson NovaThor A9500 and U8520 processors.
***edit: I'm not sure but considering the rather high frequencies of the SGX544s in the 8540 and 9540 the SoCs might be manufactured under Samsung's 28nm.....ST-Ericsson’s powerful NovaThor™ U8500, U8520 and L8540 ModAp platforms with integrated application processors, modems and connectivity. In fact, the NovaThor U8500 platform was selected by leading manufacturers such as Samsung, Sony Mobile Communications and Motorola, to power some of their 2012 smartphones.
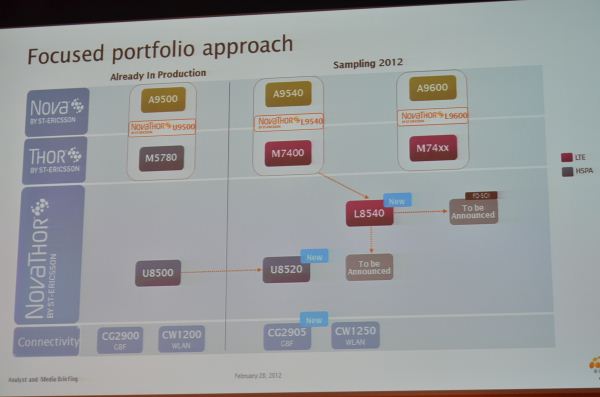
So it's not U8420 bur rather U8520, and it seems to be a direct shrink of the U8500?
Why didn't they just use their own Exynos 4212? Because of the integrated baseband?
Probably because of the baseband. Samsung never shied away from buying SoCs from other manufacturers if it should have a requirement their own SoCs don't include.
tangey,
I think but am not sure that the CPU cores in the SIII mini are clocked at 1GHz.
To help its partners, Imagination is already working with leading silicon foundries to implement high performance mobile GPU-based systems delivering unheard-of levels of memory bandwidth, using the latest PowerVR Series6 GPUs combined with wide I/O memory and advanced 3DIC assembly and process technologies. Imagination is also working with foundries and EDA vendors to ensure that licensees of all of Imagination’s IP (intellectual property) cores can benefit from well-defined tool flows and optimized libraries to achieve the most aggressive speed, area and power consumption targets.
")
That is a pretty vague statement regarding memory bandwidth. And why would they need "unheard of" levels of memory bandwidth when TBDR GPU's are supposed to require less memory bandwidth vs. other GPU's?
Will that generation of GPUs be used ONLY for gaming? When those GPUs will launch we'll be able to compare them with other next generation GPUs and we'll see how perf/mm2 and/or perf/W looks like in real time achievable fillrates, geometry througput and others.On a side note, it's interesting (although not unexpected given the source and given the marketing push behind the Series 6 architecture) to see that he defines GPU horsepower as GFLOP throughput. That is a bit misleading IMHO. GPU's used for gaming are almost never compared on a GFLOP/w or GFLOP/mm^2 basis, because this metric often doesn't correlate well with real world gaming performance.
Since when do IHVs quote theoretical floating point throughput in achievable rates anyway? Other than that when the time comes we'll also see how Rogue fares with GPGPU.On the other hand, this metric is useful for high performance computing, but even then the metric would only be useful when looking at real world achievable and measureable GFLOP throughput rather than maximum theoretical GFLOP throughput.
Just because an architecture needs less bandwidth overall than other architectures, it shouldn't mean that when performance rises by a large degree that bandwidth requirements aren't also rising.
Will that generation of GPUs be used ONLY for gaming?
They've stated elsewhere that Rogue is by 5x times more efficient than the current generation.
Since when do IHVs quote theoretical floating point throughput in achievable rates anyway?
From the so far announced next generation GPU IP cores ST Ericcson quoted for its future Novathor A9600 over 210 GFLOPs, over 5 GTexels fillrate (without overdraw) and over 350M Tris. ARM has quoted for its Mali T604 72 GFLOPs, 2 GTexels fillrate, both being 4 cluster designs.
There's no such thing as "enough" bandwidth. Ironically all so far SoC hw units share the very same bandwidth, meaning it's obviously not just for the benefit of the GPU.Obviously raw bandwidth requirements will increase over time. It is just ironic that ImgTech would promote "unheard of" levels of memory bandwidth rather than bandwidth-saving technologies of their TBDR architecture
As long as the gaming industry is thriving, then GPU's will be used primarily for gaming right? That said, do note that we are talking here about SoC's meant primarily for use in handheld devices (ie. smartphones, tablets). Gaming on these handheld devices could stress the GPU more than just about any other type of application available today. GPGPU and high performance computing is largely irrelevant on smartphones/tablets, especially those due out in the near future or next year.
I think you are reading too much into that marketing note. When they say 5x more efficient, I think they mean 5x more GFLOPS in one Series 6 (Rogue) "cluster" vs. one Series 5 "core". The word "cluster" is a very generic term.
IHV's quote this for high performance computing products, not for consumer-focused gaming GPU's.
As noted above, the word "cluster" is a very generic term and could mean almost anything. By the way, weren't these NovaThor 9600 specs announced more than 1.5 years ago? This product may not even make it to market until middle to end of 2013.
I don't think it means IMG is going to deliver unheard levels bandwidth. This quote was phrased badly (intentionally perhaps?). It just means they are working on chips that are built to USE unheard levels of bandwidth.I don't think it deserves a new thread (yet):
http://www.xbitlabs.com/news/mobile...ilor_PowerVR_Graphics_Cores_to_Foundries.html
http://www.imgtec.com/News/Release/index.asp?NewsID=699
Hmmmm....
I don't think it means IMG is going to deliver unheard levels bandwidth. This quote was phrased badly (intentionally perhaps?). It just means they are working on chips that are built to USE unheard levels of bandwidth.
EDIT: edit for clarity
There's no such thing as "enough" bandwidth. Ironically all so far SoC hw units share the very same bandwidth, meaning it's obviously not just for the benefit of the GPU.
For most platforms, system latency is quickly becoming the bottleneck. The traditional CPU centric approach was to rely on dedicated memory with fixed predictable access times (tightly coupled memory, for example) and hope Out of Order (OoO) execution and branch prediction would mask latency issues. This proved to be a tolerable “good enough” solution as long as the cost and performance metrics were reasonable.
Therefore it becomes clear that, as embedded technologies move forward, common solutions such as increasing clock frequencies, adding additional caches or increasing the number of CPU cores on a chip will just make matters more complicated rather than deliver leaps in performance gain. As processors try to take control of the system resources, the bus fabric becomes a convoluted matrix and large latencies will unequivocally start to appear. These will in turn corrode the overall system performance and waste power, therefore going to a dual-core CPU might only give a 30% to 70% improvement.