Not to say I think this stuff is viable, but you can of course simply daisy chain the memory chips ... you just double the area cost.But this paper contains pretty much all ammunition to shoot down the wireless idea. Following the honored tradition of academic paper double speak, it says 1mw/channel or 1Tb/mm2. Not really too bad, but that's assuming a distance of 30um between transmitter and receiver. Clearly you're going to get issues doing this with a GPU linking to multiple memory chips.")
Install the app
How to install the app on iOS
Follow along with the video below to see how to install our site as a web app on your home screen.
Note: This feature may not be available in some browsers.
You are using an out of date browser. It may not display this or other websites correctly.
You should upgrade or use an alternative browser.
You should upgrade or use an alternative browser.
Ray Tracing Versus Rasterization, And Why Billions Of Dollars Is At Stake
- Thread starter Brimstone
- Start date
Not to say I think this stuff is viable, but since they are pitching it as a method for wafers stacked face up rather than face to face you can of course simply daisy chain the memory chips ... you just double the area cost.But this paper contains pretty much all ammunition to shoot down the wireless idea. Following the honored tradition of academic paper double speak, it says 1mw/channel or 1Tb/mm2. Not really too bad, but that's assuming a distance of 30um between transmitter and receiver. Clearly you're going to get issues doing this with a GPU linking to multiple memory chips.
ShootMyMonkey
Veteran
Well, this is something of a mixed bag because the relative sizes are small and all, but if you're talking about a GPU, you'll basically have to multiply that out by 50x since that same increase will be there 50x over. And unlike a CPU, the vast majority of that die space is functional logic, which itself isn't loaded over with all sorts of self-scheduling, forwarding, OOOE, predictors, prefetchers, god-knows-what-else. Whereas on a CPU, you're basically making an x% increase on <50% of the die area, on a GPU, you're making that same x% increase on what is effectively 80+% of the die.- The incremental cost of double precision and rounding is relatively small. And shrinking. Clearly the multipliers and adders are a solved problem. Additional cost close to zero. The rounding is fairly complicated but not excessive.
- Register files need to double in size, but that's also a fairly small area hit.
Either that, or nVidia, in their infinitesimal wisdom, somehow convinces everybody that half-precision floats are good enough for everything that can ever be conceived by the human mind. That and they'll also prove that pi is exactly 3.If double precision never comes to the GPU, it will be because the grand vision of the GPU as a massive parallel general purpose calculation engine didn't materialize.
If they do that, it will also generate a massive market for AIPUs and advancement in artificial intelligence in general -- after all, if people lack the natural kind, you need an artificial source.
Mmmm... yes and no. Raytracing, I can see the need at some point as scales and complexity and granularity grows... at that point the main value of precision is to make sure that working with large numbers and small numbers at the same time doesn't turn into nothingness. Of course, there are points within there that you also expressly want less precision -- e.g. early rejection of samples because they won't make a meaningful difference to the final visual result -- there are cute ways to cheat away comparisons and branches if you round down to nothing. Physics, I can definitely see it as you start getting into more complicated primitives and higher frequency collision geometry -- there are reasons why a lot of the primitives you *think* are supported in most physics engines (e.g. cylinders) are absolutely not. AI... not much of a problem. Graphics as in the illumination models and color arithmetic and such... pretty much not an issue.But do ray-tracing, game physics, game graphics or AI need DP? As far as I can tell a lot of the emphasis here is on the data-parallel part (ultra high bandwidth, SIMD/vector) rather than precision, per se.
Though the problems are more or less down the road issues -- bandwidth is of course the bigger problem here and now... and I expect it to still be a problem when the name "Xbox 360" refers to the 360th-generation Xbox.
Last edited by a moderator:
Jawed
Legend
Hey my heart sank when I saw the starting point of the 300um spacing.Nice find!
But this paper contains pretty much all ammunition to shoot down the wireless idea. Following the honored tradition of academic paper double speak, it says 1mw/channel or 1Tb/mm2. Not really too bad, but that's assuming a distance of 30um between transmitter and receiver. Clearly you're going to get issues doing this with a GPU linking to multiple memory chips.
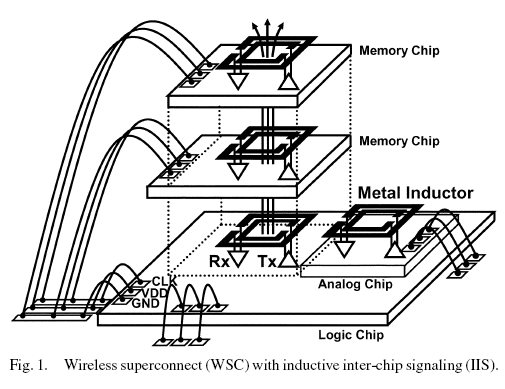
Stacked memory chips is a nice simple application for this kind of signalling technology, all the same. It wouldn't be hard to make a bus that's 1000s of bits wide, at 200 bits per mm2.
Alternatively, it's not hard to imagine a CPU/DPP/GPU die, say 200mm2 with memory chips dotted across its surface, each memory chip interfacing wirelessly to a "channel" on the parent die. Each of say 8 memory chips could have a 1Kb-wide interface, 5Tb/s per chip, delivering 5TB/s total bandwidth.
Because all 9 dies are manufactured independently, you get nice yields.
Packaging of a parent die with daughter memory dies should be doable and setting the distance at 30um twixt correspondent dies doesn't sound hard. The biggest problem is heat produced by the parent die, really...
Actually, the power dissipated in each transmitting transceiver is fairly potent, 1000 bits would consume over 20W - ouch
Sorry to sound so generally optimistic about this kind of stuff
Considering they were using plain signalling, and they rustled this up with bits of tinfoil and a scalpel, I'd say that's pretty impressive!And check out the BER numbers: I don't know the numbers for current memory interfaces, but surely the error rate is multiple orders of magnitudes better than 10er-10. At 1.25Gb/s that's still one error every second.
Jawed
Last edited by a moderator:
Jawed
Legend
Precisely.Whereas on a CPU, you're basically making an x% increase on <50% of the die area, on a GPU, you're making that same x% increase on what is effectively 80+% of the die.
Jawed
It was the closest icon I could find to :raising one eyebrow in utter disbelief that people expect this to be better than connecting it with wires:"On this day in 2006, someone managed to nonplus Simon F on a forward-looking technical point. World-wide disaster was only averted by quick action of international institutions."
Unfortunately, the distance is the key problem. Look as figure 16 to see how the bottom falls out of the SNR number when distance is increased to a mere 400um. Impossible to recover that unless you plan to use the coding techniques that I mentioned earlier and drastically increase the transmit power. Think about what'd be needed to cover mm's instead of um's.
Which would kill the idea in an instant just for electro-magnetic interferance issues, that baby would make a nice radio show for the whole neighbourhood...
Not to say I think this stuff is viable, but since they are pitching it as a method for wafers stacked face up rather than face to face you can of course simply daisy chain the memory chips ... you just double the area cost.
And reduce the bandwidth severely
The bandwith per site stays exactly the same.And reduce the bandwidth severely
As for EM, just box it up.
The bandwith per site stays exactly the same.
Don't get what you're talking about. If you're going to "chain" them, it means that the data has to pass through the chain to the last of the chips. That data must be routed through, and that will put strain on the whole chain, dividing the bandwidth by the number of chips, roughly. Or what do you mean?
EDIT: and I've been looking for the magical box for years to "box it up", but until now it's been a series of design changes, EM-chamber measurings, redesign, measure... until the acceptable solution is found. And this stuff ain't even wireless. Would be nice if it was that easy.
Last edited by a moderator:
You don't say putting a second memory module in your computer halves the bandwith either do you?
Why, in our PC's the interface is parallel. You're talking about a serial interface. So each chip would get a few "lanes" (comparable to PCI-e sort of) if you wish to describe it so. Otherwise we'd be talking about something like Jawed's 1000 bit bus, which is definitely nowhere near being feasible in near future.
To the experts: How many gigaflops for a entry level quality 720p ray-trace or similar? Thanks
I was thinking about a .22nm 200mm2 chip (by ~2012) with 32 c-optimized x86-64 (all non optimized instructions being handled by exceptions) cores at 8GHz (low-power reasons) each with a MMX style SIMD DSP unit capable of 4 MA single-precision per cycle.
It means 32x8x4x2 = 2048 Gigaflops/sec (DSP unit only).
To try to sustain this performance add some edram (128MB 1T-SRAM) and sold the chip in the PCB, use some very fast bandwith memory for the first 4GBytes and some expanded memory up to some 128GB for VM memory.
And maybe some multichip of the above.
I was thinking about a .22nm 200mm2 chip (by ~2012) with 32 c-optimized x86-64 (all non optimized instructions being handled by exceptions) cores at 8GHz (low-power reasons) each with a MMX style SIMD DSP unit capable of 4 MA single-precision per cycle.
It means 32x8x4x2 = 2048 Gigaflops/sec (DSP unit only).
To try to sustain this performance add some edram (128MB 1T-SRAM) and sold the chip in the PCB, use some very fast bandwith memory for the first 4GBytes and some expanded memory up to some 128GB for VM memory.
And maybe some multichip of the above.
Last edited by a moderator:
Im talking about a bus which broadcasts through repeaters. All the chips would share the bandwith (of a single channel or multiple channels, it really doesn't matter to the arguement) just like memory modules in a PC share bandwith. The only way it would reduce bandwith is if you assigned individual channels to a single chip in the stack or you time multiplexed bus access, and there is just no reason to do that.
( http://www.beyond3d.com/forum/showpost.php?p=47981&postcount=34 )
How about 0.0000000000000000001*10^(-23) micron tech with 20 GB eDRAM having 100 TBit bus?
sounds nice? yeah. why not drop out the old pipeline design and make MultiScalar 512 Bit accurancy Pixel RayTracer with huge parallerlism capable pushing more than 2 fully 24 Super Sampled anti-aliased tera pixels per second on polar cordinate iMax compliant format?
why not?
- propably MS wouldn't support it.
Cider gets on my head... need something to eat...
Im talking about a bus which broadcasts through repeaters. All the chips would share the bandwith (of a single channel or multiple channels, it really doesn't matter to the arguement) just like memory modules in a PC share bandwith. The only way it would reduce bandwith is if you assigned individual channels to a single chip in the stack or you time multiplexed bus access, and there is just no reason to do that.
Ok, now I get what you meant. The connection discussed (from Jawed's post) is point-to-point though, how would you deal with latency and signal range?
One article about "Ray Tracing on Programmable Graphics Hardware"
http://graphics.stanford.edu/papers/rtongfx/rtongfx.pdf#search=%22Ray%20tracing%20on%20programmable%20graphics%20hardware%22
http://graphics.stanford.edu/papers/rtongfx/rtongfx.pdf#search=%22Ray%20tracing%20on%20programmable%20graphics%20hardware%22
How you mean signal range? Each chip would only need to communicate with it's direct neighbors. Or do you mean interference wise? By alternating the position of transmitters and receivers in the stack you reduce relative power of the signal from the second closest transmitter on the z-axis to 1/9th, putting a grounded metal layer below/above the transmitter would probably help too.
A couple extra clocks of delay for buffering before retransmitting is unlikely to really make an impact on latency with DRAM.
A couple extra clocks of delay for buffering before retransmitting is unlikely to really make an impact on latency with DRAM.
How you mean signal range? Each chip would only need to communicate with it's direct neighbors.
Oh now I see, I totally missed the part with stacking them vertically. I was all about a horizontal layout with chips next to each other, which would limit the number of possible close neighbours.
Similar threads
- Locked
- Replies
- 10
- Views
- 2K
- Replies
- 37
- Views
- 3K
- Replies
- 608
- Views
- 96K
- Replies
- 90
- Views
- 18K