Yea, I guess that would have been better than mere resolution scaled images - didn't come to think of it. Oh well, cant go back to the same exact scene again and don't feel like starting over so the postage stamps is all I'm left with.Missing DSR for a ground truth comparison
Install the app
How to install the app on iOS
Follow along with the video below to see how to install our site as a web app on your home screen.
Note: This feature may not be available in some browsers.
You are using an out of date browser. It may not display this or other websites correctly.
You should upgrade or use an alternative browser.
You should upgrade or use an alternative browser.
Nvidia DLSS 1 and 2 antialiasing discussion *spawn*
- Thread starter DavidGraham
- Start date
-
- Tags
- nvidia
The model is the same yes. The amount of hardware required to execute the model is not.Do all cards do DLSS the same..?
Benetanegia
Regular
The amount of hardware required to execute the model is not.
Surely, you're speaking relatively to the amount of total units? Cause otherwise, I'm pretty sure that statement would be wrong.
As in the number of tensor cores between varying cards is not the same.Surely, you're speaking relatively to the amount of total units? Cause otherwise, I'm pretty sure that statement would be wrong.
Benetanegia
Regular
Yes, but I don't think more tensor cores are required on larger chips? More TCs just finish the task faster, I'm sure. Or am I missing something?
EDIT: Like, hyphotetically, the number of tensor cores could be limited by drivers to be the same on all cards and the model would then execute the same and not somehow worse.
EDIT: Like, hyphotetically, the number of tensor cores could be limited by drivers to be the same on all cards and the model would then execute the same and not somehow worse.
Generally speaking yes more tensor cores would finish the job faster. The more tensor cores you have the faster you can get through the density of the network. If it’s thin, it’s not going to matter much, but if it’s deep, then having more cores will result in faster performance than less. Bandwidth is also a large factor.Yes, but I don't think more tensor cores are required on larger chips? More TCs just finish the task faster, I'm sure. Or am I missing something?
EDIT: Like, hyphotetically, the number of tensor cores could be limited by drivers to be the same on all cards and the model would then execute the same and not somehow worse.
So what I meant was exactly this topic with respect to DLSS being the same across the cards. The answer is yes, it is the same model being run across all GPUs, and that the answer is that more hardware runs it faster (generally speaking).
but to answer your question; I have no clue if larger chips require more tensor cores
. That’s beyond me lol
Last edited:
Benetanegia
Regular
Generally speaking yes more tensor cores would finish the job faster. The more tensor cores you have the faster you can get through the density of the network. If it’s thin, it’s not going to matter much, but if it’s deep, then having more cores will result in faster performance than less. Bandwidth is also a large factor.
So what I meant was exactly this topic with respect to DLSS being the same across the cards. The answer is yes, it is the same model being run across all GPUs, and that the answer is that more hardware runs it faster (generally speaking).
but to answer your question; I have no clue if larger chips require more tensor cores
That makes sense. The wording of your first post made me think you were implying that there was indeed a difference.
Generally speaking yes more tensor cores would finish the job faster. The more tensor cores you have the faster you can get through the density of the network. If it’s thin, it’s not going to matter much, but if it’s deep, then having more cores will result in faster performance than less. Bandwidth is also a large factor.
So what I meant was exactly this topic with respect to DLSS being the same across the cards. The answer is yes, it is the same model being run across all GPUs, and that the answer is that more hardware runs it faster (generally speaking).
but to answer your question; I have no clue if larger chips require more tensor cores
That is not what I asked though. Would a 2080 do DLSS faster/better than a 2070...?
That is not what I asked though. Would a 2080 do DLSS faster/better than a 2070...?
Yah, it should do it faster because it has more tensor cores.
Yes. It has more tensor power. It should complete the network fasteThat is not what I asked though. Would a 2080 do DLSS faster/better than a 2070...?
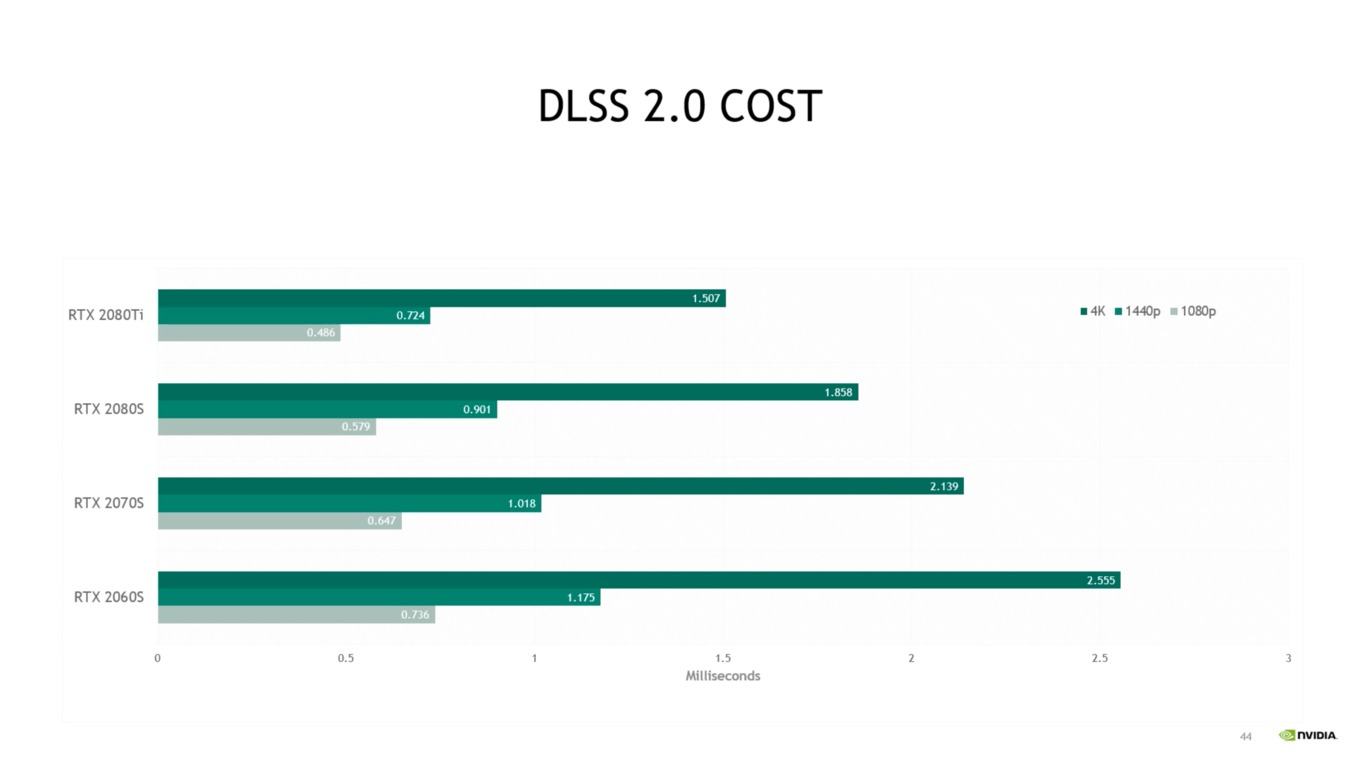
D
Deleted member 2197
Guest
Missed this when the DLSS reviews came out. Google translation ... 
https://www.pcgameshardware.de/Nvid...arrior-5-DLSS-Test-Control-DLSS-Test-1346257/Nvidia's developer tool Nsight allows games and their frames to be analyzed in order to expose performance guzzlers. The possibilities go far beyond what we can see, for example, which effect requires which computing time. The tool also shows how well the GPU is busy and which resources are used. If you analyze a DLSS 2.0 game through Nsight, you will see several things here: DLSS 2.0 is used at the end of a frame and causes data traffic on the tensor cores (INT8 operations). This would prove that DLSS 2.0 is not a task for the FP-ALUs, but that Turing's special units are actually used.
The only thing I've ever seen NVIDIA write about is FP16 Tensor Ops with FP16 accumulate.
When they presented DLSS at gamescom 2018 they had a slide about DLSS where they say that they have "~500 Billion FP16 Ops". But that might be for training and not for execution. The number 500 occurs in the volta whitepaper, "DGX Station is a whisper-quiet, water-cooled workstation that packs four NVIDIA Volta-powered Tesla V100 GPUs delivering up to 500Tensor TFLOPS for deep learning applications."
From "NVIDIA DLSS: Control and Beyond" :
"Our next step is optimizing our AI research model to run at higher FPS. Turing’s 110 Tensor teraflops are ready and waiting for this next round of innovation."
From "NVIDIA DLSS 2.0: A Big Leap In AI Rendering"
"With Turing’s Tensor Cores delivering up to 110 teraflops of dedicated AI horsepower, the DLSS network can be run in real-time simultaneously with an intensive 3D game"
In the Turing whitepaper they say that they have "113.8 Tensor TFLOP of FP16 matrix math with FP16 accumulation". So i guess that is number that they reference.
But I mean, if someone has proof that it's only using INT8 I guess everyone would be happy to see it?
When they presented DLSS at gamescom 2018 they had a slide about DLSS where they say that they have "~500 Billion FP16 Ops". But that might be for training and not for execution. The number 500 occurs in the volta whitepaper, "DGX Station is a whisper-quiet, water-cooled workstation that packs four NVIDIA Volta-powered Tesla V100 GPUs delivering up to 500Tensor TFLOPS for deep learning applications."
From "NVIDIA DLSS: Control and Beyond" :
"Our next step is optimizing our AI research model to run at higher FPS. Turing’s 110 Tensor teraflops are ready and waiting for this next round of innovation."
From "NVIDIA DLSS 2.0: A Big Leap In AI Rendering"
"With Turing’s Tensor Cores delivering up to 110 teraflops of dedicated AI horsepower, the DLSS network can be run in real-time simultaneously with an intensive 3D game"
In the Turing whitepaper they say that they have "113.8 Tensor TFLOP of FP16 matrix math with FP16 accumulation". So i guess that is number that they reference.
But I mean, if someone has proof that it's only using INT8 I guess everyone would be happy to see it?
The only thing I've ever seen NVIDIA write about is FP16 Tensor Ops with FP16 accumulate.
When they presented DLSS at gamescom 2018 they had a slide about DLSS where they say that they have "~500 Billion FP16 Ops". But that might be for training and not for execution. The number 500 occurs in the volta whitepaper, "DGX Station is a whisper-quiet, water-cooled workstation that packs four NVIDIA Volta-powered Tesla V100 GPUs delivering up to 500Tensor TFLOPS for deep learning applications."
From "NVIDIA DLSS: Control and Beyond" :
"Our next step is optimizing our AI research model to run at higher FPS. Turing’s 110 Tensor teraflops are ready and waiting for this next round of innovation."
From "NVIDIA DLSS 2.0: A Big Leap In AI Rendering"
"With Turing’s Tensor Cores delivering up to 110 teraflops of dedicated AI horsepower, the DLSS network can be run in real-time simultaneously with an intensive 3D game"
In the Turing whitepaper they say that they have "113.8 Tensor TFLOP of FP16 matrix math with FP16 accumulation". So i guess that is number that they reference.
But I mean, if someone has proof that it's only using INT8 I guess everyone would be happy to see it?
Turing added int8 and int4 modes to tensor cores. int8 is double fp16 throughput and int4 is double int8 throughput.
Is there anyway to launch Minecraft Windows 10 on Nsight?
I ran Control but it pauses anytime i alt-tab. So I can't capture an ingame frame on Nsight to analyse.
I ran Control but it pauses anytime i alt-tab. So I can't capture an ingame frame on Nsight to analyse.
Last edited:
Maybe I was a bit unclear, but I meant in the context of DLSS (and hence why I only named DLSS examples). I will try to be more clear going forward.Turing added int8 and int4 modes to tensor cores. int8 is double fp16 throughput and int4 is double int8 throughput.
Similar threads
- Replies
- 460
- Views
- 47K
- Replies
- 161
- Views
- 10K
- Replies
- 3
- Views
- 691
- Replies
- 640
- Views
- 81K
- Locked
- Replies
- 10
- Views
- 1K