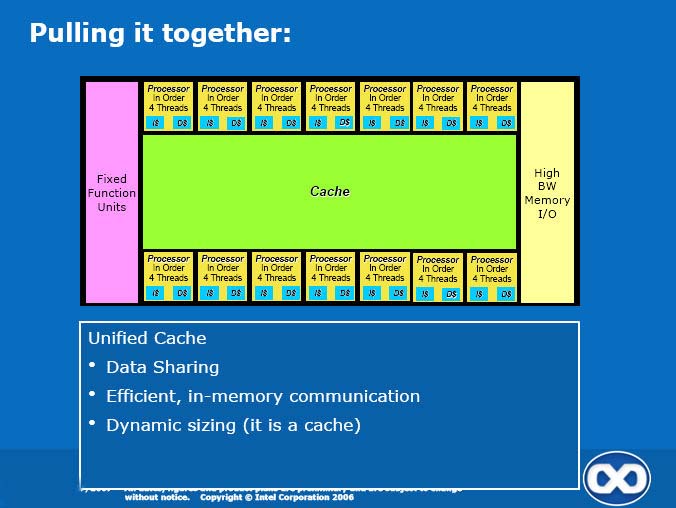
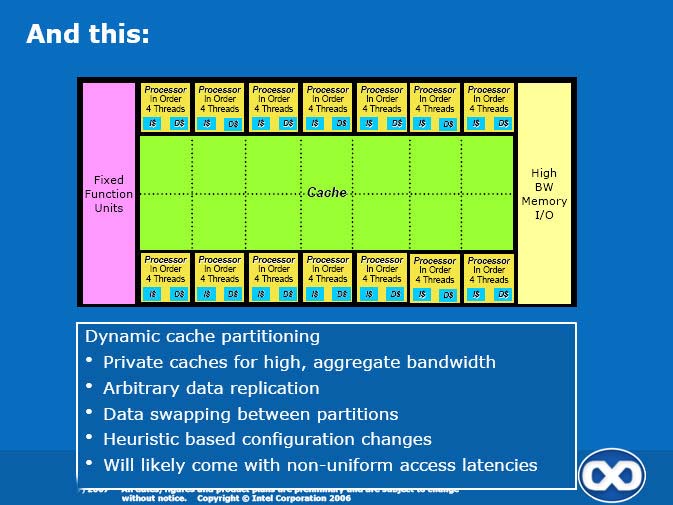
I am intrigued how it will scale up because lack of scalability was one of the reason for Cell SPEs doesn't used cache coherence scheme and opted for the DMA model.
First, some background.
In my opinion, the non-scalability of cache coherence is greatly exaggerated. Yes, connecting hundreds or thousands of processors to make a single cache-coherent shared memory image is really hard (although the SGI Origin did it), but putting a few dozen processors together isn't so bad. Lots of systems have been built by Sun, SGI, IBM, have connected discrete chips. Of course, bandwidth and latency are the issues.
However, once you've moved to an on-chip setting, the latencies go down and the available bandwidth goes up, making building a cache-coherent system even easier. It still isn't easy to design the controller to do it correctly, but even that is becoming easier as we better understand how to build such systems.
Do you know any more detail about Intel implementation?
From what I've been told, Larrabee will use a full-map directory protocol. It is conseptually similar to what was proposed in the Stanford DASH prototype and then used in the SGI Origin and Alpha 21364. The difference is that Larrabee uses a directory cache (on-chip) rather than a in-memory directory (stored in off-chip DRAM).
The a directory protocols with directory caches work in general is that in front of each memory controller is a cache that holds information as to which caches on the chip are caching a block. If one core wants to write the block, it first accesses the directory. The directory sends message to invalidate the other cores that have the block cached. These cores all send an acknowledgement message. Once all the acknowledges have been collected, the original processor can write the block.
By using a directory, the system doesn't need to broadcast requests. More importantly, it avoids needing to have all N-1 processors respond with an acknowledgement (as would happen in a Opteron system, for example).
To make this work, the directory tracks which processors cache which blocks. This means the geometry of the directory needs to mirror the combined geometries of the cache tags. In essence, you end up with a highly set-associative cache to hold the directory information (which isn't so good, but can be done).

")