You are using an out of date browser. It may not display this or other websites correctly.
You should upgrade or use an alternative browser.
You should upgrade or use an alternative browser.
GPU Ray Tracing Performance Comparisons [2021-2022]
- Thread starter DavidGraham
- Start date
Seems like a pretty normal performance delta. For some reason the 2080 Ti and 3070 do especially badly here and the 3080 is 70% faster than the 2080 Ti at 4K.
I think the 3070 and the 2080 Ti are performing comparably worse due to different reasons. The 3070 is most likely just running out of VRAM with RT enabled, the 2080 Ti just isn't as good as Ampere for a lot of async compute.
They use async compute to hide the cost of building the BVH, that's one of the reasons why it's so cheap. This capture is at native 4K on the 3080 (no DLSS)
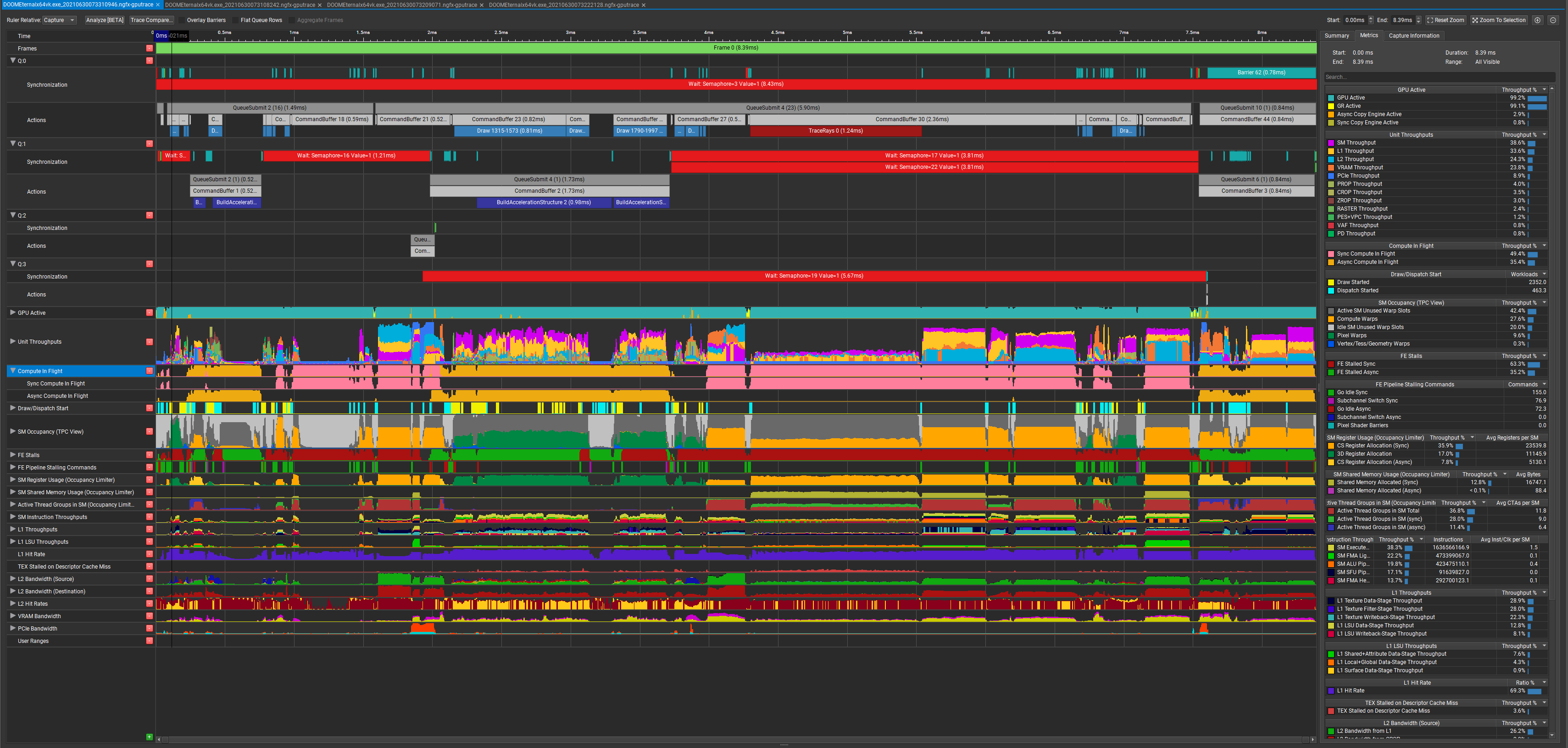
From several frame captures I see the cost of RT is usually in the 1.5 - 2.5 ms range at native 4K which is pretty impressive.
^ Eternal is using async compute to hide much of the cost of building the BVH (Control does something similar afaik), maybe the 2080 Ti is slower using that path. Should be easy enough to get a frame capture with NSight using a 2080 Ti and compare
")
Last edited:
DavidGraham
Veteran
CPU limitations.The gap closes to 12 % as resolution goes down to FHD.
Ultra Nightmare settings consume a lot of VRAM, the 3060 is a 12GB card.GeForce 3060 is already beating 8 GB cards?
DegustatoR
Legend
Anyway, back to the topic: DOOM: Eternal mit Raytracing und DLSS im Test
DavidGraham
Veteran
The 3090 is 57% faster @4K than the 6900XT, @2K it is 50% faster too.Anyway, back to the topic: DOOM: Eternal mit Raytracing und DLSS im Test
The 3070 is a touch behind the 6900XT as well.
DegustatoR
Legend
There are some weird results there between resolutions and 8GB cards.
3070 is 44% slower than 3070Ti in 1080p for example and 50% slower in 1440p. No idea why.
Both 3070 and 3060Ti are also slower than 3060 - except in 4K where they are ahead. Which seems a bit weird if its due to lack of VRAM for UQ streaming buffer.
They should've probably tested them (or all GPUs) with Nightmare texture streaming buffer.
3070 is 44% slower than 3070Ti in 1080p for example and 50% slower in 1440p. No idea why.
Both 3070 and 3060Ti are also slower than 3060 - except in 4K where they are ahead. Which seems a bit weird if its due to lack of VRAM for UQ streaming buffer.
They should've probably tested them (or all GPUs) with Nightmare texture streaming buffer.
DavidGraham
Veteran
There are 3 texture settings: Ultra, Nightmare and Ultra Nightmare.
They have no visual quality difference, Ultra Nightmare just caches in massive amount of textures to minimize the possibility of any texture pop in during fast motion.
Ultra Nightmare is not usable on 8GB or less GPUs.
Ultra Nightmare + RT is impossible on 8GB GPUs, and if forced results in severe fps degradation. The 3070 for example goes from 100fps+ to just 30fps.
They have no visual quality difference, Ultra Nightmare just caches in massive amount of textures to minimize the possibility of any texture pop in during fast motion.
Ultra Nightmare is not usable on 8GB or less GPUs.
Ultra Nightmare + RT is impossible on 8GB GPUs, and if forced results in severe fps degradation. The 3070 for example goes from 100fps+ to just 30fps.
It does absolutely nothing for average static image quality, just changes the amount of Textures cached in VRAM like @DavidGraham says, hence why it is called "Texture Pool Size" and not "Texture Resolution or Quality".. A texture on Ultra Nightmare looks the exact same as it does on Low. The lower you go even down to "Low" only increases the chances that rapid camera movement or perhaps an active camera teleport can perhaps lead to a lower res mip being shown for a few frames. That is it.Does the ultra nightmare vram heavy setting in Doom actually change the image in any way? Does it improve performance? Why is it there?
D
Deleted member 2197
Guest
It does absolutely nothing for average static image quality, just changes the amount of Textures cached in VRAM like @DavidGraham says, hence why it is called "Texture Pool Size" and not "Texture Resolution or Quality".. A texture on Ultra Nightmare looks the exact same as it does on Low. The lower you go even down to "Low" only increases the chances that rapid camera movement or perhaps an active camera teleport can perhaps lead to a lower res mip being shown for a few frames. That is it.
Makes me wonder why this is a setting in the first place if its that useless. It's just going to confuse people.
Why not leave it at medium or high for all cards, or let the engine automatically choose based on GPU's VRAM, graphics settings and active background programs.
This is one thing that definately should improve for the next IDTech game. Their fixed memory allocation system also has some drawbacks like we have seen with that strange DLSS memory allocation bug.
DegustatoR
Legend
They should've just made it separate from quality presets.Makes me wonder why this is a setting in the first place if its that useless. It's just going to confuse people.
Why not leave it at medium or high for all cards, or let the engine automatically choose based on GPU's VRAM, graphics settings and active background programs.
This is one thing that definately should improve for the next IDTech game. Their fixed memory allocation system also has some drawbacks like we have seen with that strange DLSS memory allocation bug.
DavidGraham
Veteran
That was before Moor's law ended, now we are in a new reality. Chips are going bigger again.Usually chips get smaller, not larger. And HW becomes cheaper, not more expensive
RDNA2 chips are expensive even though they are smaller than Turing. A 6900XT is a 1000$ and in most RT workloads it's no better than a Turing.Turing was the opposite of that.
Turing was more expensive yes, but considering it was the only future proof arch with DX12U support, It paid dividend for it's userbase, as opposed to the cheap dead end RDNA1 GPUs.
Turing is definitely more capable RT wise than RDNA2. Period. Current workloads (gaming/professional) are proof enough of that.Finally it's simply not true AMD RT is 'not capable'. If you think so, you also think Turing is not capable, which i doubt.
But hey don't have to. Keep them small and achieve visual progress with better softwareThat was before Moor's law ended, now we are in a new reality. Chips are going bigger again.
Yep, even RDNA was expensive. Got the same TF at half the price by sticking at GCN. So AMD also did contribute to my somewhat exaggerated depressed view on a healthy PC platform.RDNA2 chips are expensive even though they are smaller than Turing. A 6900XT is a 1000$ and in most RT workloads it's no better than a Turing.
In RT games i see it very mostly ahead of Turing, even if RT performance in isolation is worse. So it's good enough in practice, and higher flexibility may pay off if DXR evolves quickly (which i doubt).Turing is definitely more capable RT wise than RDNA2. Period. Current workloads (gaming/professional) are proof enough of that.
Frenetic Pony
Veteran
Makes me wonder why this is a setting in the first place if its that useless. It's just going to confuse people.
Why not leave it at medium or high for all cards, or let the engine automatically choose based on GPU's VRAM, graphics settings and active background programs.
This is one thing that definately should improve for the next IDTech game. Their fixed memory allocation system also has some drawbacks like we have seen with that strange DLSS memory allocation bug.
It's not really "useless", watching textures "pop" in is never pleasant. It's just that people benchmarking games don't really know what VRAM pools like this do, heck most users don't either. You up the setting and it looks no different from a standstill, what gives?
I don't imagine any next gen Idtech games are going to bother with such large pool sizes though. We've got SSDs and decompression engines and watnot now, no need to pre-stream and cache in vram anymore assuming your current streaming system is up to snuff. Besides you need that vram for radiance caches and acceleration structures and etc.
RDNA2 chips are expensive even though they are smaller than Turing. A 6900XT is a 1000$ and in most RT workloads it's no better than a Turing.
Turing was more expensive yes, but considering it was the only future proof arch with DX12U support, It paid dividend for it's userbase, as opposed to the cheap dead end RDNA1 GPUs.
Turing is definitely more capable RT wise than RDNA2. Period. Current workloads (gaming/professional) are proof enough of that.
Most of the current RT workloads are developed with a focus on what Nvidia hardware can and cannot do. So I think it's not (yet) the right time for such an absolute statement as your "uring is definitely more capable RT wise than RDNA2. Period."
For example Doom Eternal Benchmarks say otherwise. Don't be blinded by the better Ampere, RDNA2 can be quite competitive with Turing, even on a 550-vs-1100-comparision of RX 6800 vs. 2080 Ti.
(anecdotal) proof:

source: https://www.pcgameshardware.de/Doom...ng-RTX-Update-DLSS-Benchmarks-Review-1374898/
edit:
anecdotal proof #2 (6700XT is a bit ahead in 1080p, a bit behind in 3840p, 2070S is a 539€ card, 6700XT 480€)

source: https://www.computerbase.de/2021-06...mm-lego-builders-journey-2560-1440-raytracing
Last edited:
RDNA2 needs around 50% more transistors than Turing to deliver the same performance with heavy RT workload. From a technical standpoint AMD's implementation is worse than Turing's.
Not to forget at the cost of normal rendering budget.
Yet another metric. Well, for that to have any meaning, you'd have to compare the full configs of each Navi21 and TU102. As it stands, 6800 uses 60 out of 80 execution units (and 75% of the ROPs, 100% memory configuration for completeness' sake), TU102 68 out of 72 (92% of memory and ROPs).RDNA2 needs around 50% more transistors than Turing to deliver around the same performance with heavy RT workload. From a technical standpoint AMD's implementation is worse than Turing's.
And not all x-tors go into raytracing:
proof:

source: https://www.pcgameshardware.de/Graf...s/Rangliste-GPU-Grafikchip-Benchmark-1174201/
Similar threads
- Replies
- 7
- Views
- 2K
- Replies
- 0
- Views
- 556
- Replies
- 480
- Views
- 72K
- Replies
- 15
- Views
- 3K