Wanted to build off of this. I didn't read the slide deck until now, but things did turn out as I thought they could be at least according to these marketing slides. Fine grained draw calls, shorter and smaller jobs to fit between breaks on GPU resources.
This first slide represents the move to the advantages of parallel rendering. This is imo much above just relieving the CPU of over burdened draw calls. This is GPU stuffing.
This I didn't know, I guess this was just worth sharing. I didn't realize so many different aspects of rendering were split up like this, I assume the color code represents different parts of the GPU. Well stupid written point since I'm going to post the next slide... lol. Green are ROPS? Blue is Bandwidth/BUS? Red are ALU? Purple? Maybe it doesn't work like that, anyway, next slide shows what can now be done in parallel. Is this all marketing mombo jumbo? Because imo these are huge gains, and also seriously taxing to the GPU compared to DX11. And also, if you guys know the answer to this question, but wouldn't each coloured block on that diagram require a read from memory and follow up with a write when it moves onto the next block, and then another read?
So wrt. Xbox One, in this scenario, if you flood all parts of the GPU like this you'll see a lot of concurrent read/writes happening at different times? If so, esram an effective cost wise solution to solve this problem. It has a greater purpose than just supplementing DDR3. Concurrent read/writes on traditional GDDR memory setups would kill the bandwidth if I understand correctly. So my understanding, having 7 or so threads submitting their own GPU work to be done, there is no way any developer could possibly time when all those items hit, you're going to be hit with a lot of read/writes when jobs finish and start. You would need bandwidth that would be unaffected by it hence esram was the best choice for what was available, since we can see it is not hindered by concurrency.
Which if all of that is true, we should expect the way developers program for Xbox One to change. Does it still really make sense to continue to have the render target exist in esram anymore ? You're going to want that scratch pad free if this is the type of GPU pipeline behaviour.
Last image was a question to you guys. Feb 17 was a while back, so I assumed everything about DX12 we knew already since post GDC. But this slide is telling me that the whole story has not been told yet? 1 major pillar left in DX12?
edit: and man is Brad Wardell all over those slides. LOL. I guess he's pretty involved with the marketing side of things here.
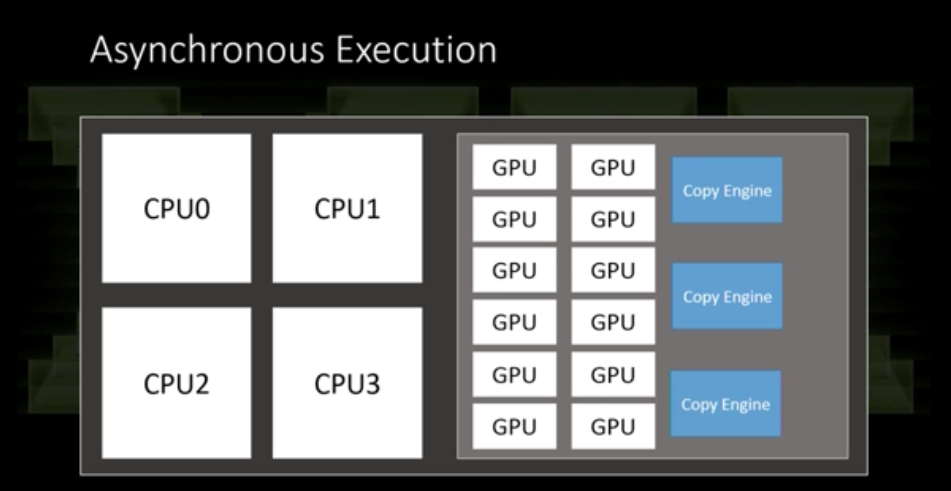
Here's another picture of the final pillar.
If 8 Core CPU is the first one, Fine grained compute is the GPU is the second one, I'm completely confused on what they bitmap could be for the last one. VR? Is that a volcano spewing lava?






")