The sample memory would never hold the entire scene. That's the frame buffer's job. The sample memory only holds fragments as long as it's not possible to turn them into completed pixels.
Just to make the patent harder to read

the patent is written to encompass any anti-aliasing scheme, whether it's super sampling or edge multi-sampling (or... erm dunno!).
If you take the simple case of edge multi-sampling, then the AA samples are encoded in a single bit per sample (they're just geometry samples, so the triangle either covers each sample point or it doesn't). That's encoded as the coverage mask. So on top of the colour and z that you need to hold for the fragment, you only need 1 byte for upto 8xAA samples in the coverage mask.
The other point about edge anti-aliasing, of course, is that you don't need to store a fragment in the sample memory if the fragment isn't on a triangle edge. If that pixel (according to z-testing thus far) is visible then it is blended with the existing value of the pixel in the frame buffer and the fragment is discarded. If the pixel is entirely hidden, then of course the fragment is discarded.
So in edge multi-sampling you're not trying to store anything like the entire frame in the sample memory. You're only storing the fragments that are unresolvable thus far.
A simple way (this isn't the entire method) of defining unresolved fragments relating to a pixel is to consider the coverage mask. In 8xAA, you can't resolve the colour/z of a pixel until all 8 samples have been covered by one or more fragments. So if two fragments only cover 6 of the 8 samples within a pixel, you can't blend those two fragments until you resolve how the final two samples are covered.
As the frame's triangles are rendered as fully resolved pixels, fragments in the sample memory are discarded - so the consumption of sample memory is constantly rising and falling. When the last triangle's last fragment arrives and you process it, you will have resolved all outstanding fragments in sample memory, which means it is empty.
So, after all that, the storage demands of the sample memory are not as seemingly huge as they first appear. At least if using edge multi-sampling.
Why was 10MB chosen for the EDRAM? What are the approximately 3MB of unused EDRAM doing (1280x720x8 is 7MB ish)?
-------
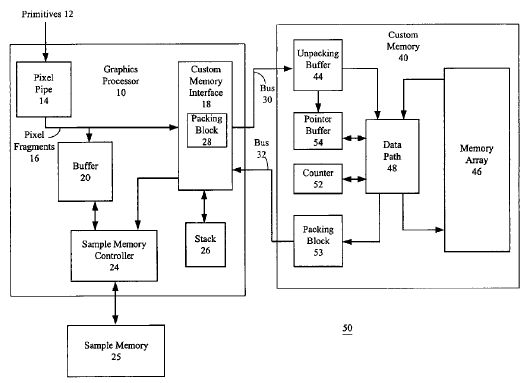
The buffer, 20 in the patent, is designed to hold fragments as they come from the GPU. But it also holds those fragments as they are fetched out of sample memory (or, potentially, on their way into sample memory).
The primary reason for 20 is so that the fragment data can be blocked into compressible units for maximum efficiency as they go over the bus - and also so that the fragment data requires a minimal-cost fetch of pixels from EDRAM by the Data Path blending unit, 48.
Also the buffer acts to hide the latency of sample fetches from the Sample Memory, by creating a queue mechanism for fragment despatch into the blending unit, 48.
In other words a random assortment of fragments are sorted into neat blocks, and while the fetching and sorting is going on, the blending unit is working on other fragments.
-------
So it seems to me that it's possible that the buffer, 20, is the remaining 3MB-ish of EDRAM.
Since blending is extremely sensitive to latency (it should never be waiting for fragments or pixel fetches from the frame buffer), you want the blending unit to be pipelined both on its input (fragments) and on its output (unresolved fragments).
So I could argue that 46 is a block-structured (pixel-organised, tiled) portion of EDRAM, i.e. the frame buffer, while 20 is a portion of EDRAM whose task is to convert random (variable latency) reads/writes against the Sample Memory into smoothly pipelined data for the blending unit.
Erm...
Jawed