darn it ! lol enjoy itSorry, I think I messed up somehow and they're sending it to me instead. My bad entirely, apologies.
Install the app
How to install the app on iOS
Follow along with the video below to see how to install our site as a web app on your home screen.
Note: This feature may not be available in some browsers.
You are using an out of date browser. It may not display this or other websites correctly.
You should upgrade or use an alternative browser.
You should upgrade or use an alternative browser.
AMD Vega 10, Vega 11, Vega 12 and Vega 20 Rumors and Discussion
How can it not be visible in shader when it is a dedicated type with pixel-level synchronization semantics in the shader? e.g. Intel advertises their implementation with the critical section starting at the first access touching the ROV resource.That's a rasterizer feature. Not something that would be visible in shader.
https://software.intel.com/en-us/gamedev/articles/rasterizer-order-views-101-a-primer
The shader compiler will automatically insert a synch point at the first instance of the RGBE buffer read.
I'd be genuinely surprised if the rasterisers are made to repack wavefronts at pixel level to guarantee such order.
Last edited:
There is a wave-level ID, operand source, message type, and specific counters added for a mode called Primitive Ordered Pixel Shading. Perhaps that is related?
chavvdarrr
Veteran
so, its confirmed that AMD failed to implement successfully tile-based rendering in Vega?
AMDs slides show up to 30% memory bandwidth usage reduction when DSBR is active: https://goo.gl/images/3TdRmp. This clearly shows that their tile-based renderer and on chip-binning ("fetch once") is working properly.so, its confirmed that AMD failed to implement successfully tile-based rendering in Vega?
However we don't know whether the occlusion culling ("shade once") is enabled and/or working. Per pixel occlusion culling would directly reduce the number of pixel shader invocations, and would bring other gains (reduced ALU/TMU use) in addition to reduced memory bandwidth use. "Shade once" should improve performance also in games that aren't memory bandwidth bound. AMD slide: https://goo.gl/images/YcVKmr.
However we don't know whether the occlusion culling ("shade once") is enabled and/or working. Per pixel occlusion culling would directly reduce the number of pixel shader invocations, and would bring other gains (reduced ALU/TMU use) in addition to reduced memory bandwidth use. "Shade once" should improve performance also in games that aren't memory bandwidth bound.
This slide was pretty recent. "Optionally performs deferred rendering step".
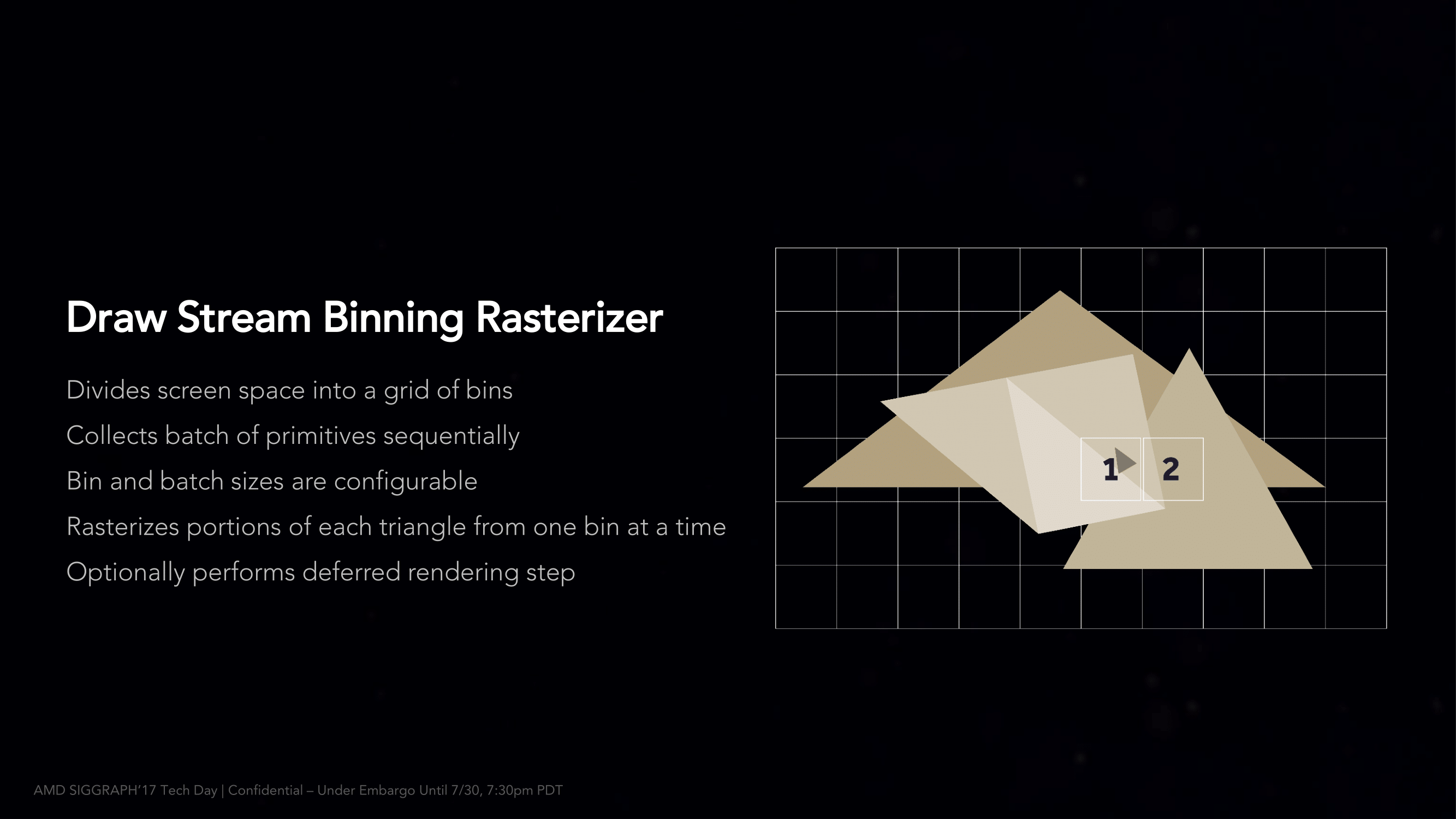
Interesting bin an betches are flexible? Does Nvidia can do this?This slide was pretty recent. "Optionally performs deferred rendering step".
Nvidia's tile size is adjusted based on the amount of pixel and vertex data that can be fit into its allocation on-die.Interesting bin an betches are flexible? Does Nvidia can do this?
The Realworldtech test shows that tile patterns changing as the vertex and pixel format settings are increased.
Any hints? Pweeeaaaasee?VERY INTERESTING!!!!!
Sorry, it just bursts out occasionally when I'm not technically allowed to say anything. My apologies, I'm just a bit excited.
If I'm understanding Rys correctly, Primitive Shaders don't require developer input. They're applied automatically in driver.
DavidGraham
Veteran
Which still begs the question, where is their effect on performance?If I'm understanding Rys correctly, Primitive Shaders don't require developer input. They're applied automatically in driver.
I figure you will only see it in geometry heavy scenarios. I don't think GCN is geometry bottlenecked in most games contrary to popular belief.Which still begs the question, where is their effect on performance?
I figure you will only see it in geometry heavy scenarios. I don't think GCN is geometry bottlenecked in most games contrary to popular belief.
I imagine, that is why a Developer was mentioning he loves how Vega handles open worlds. Even in games such as BF1, when you spin 180 to fire on someone, think about the geomtry involved in doing so, rapidly.
Also, I think too many people are underestimating HBCC, and the ability to store micro-code within vega. Doesn't that mean, RX Vega can load Vulkan, or DX12.1 microcode into local stores, like the 1X claims to do.. ?
Or is my understanding on the matter, off .. ?
Most current games would be trying to stay within the storage limits of the board. Vega has a decent to generous amount, which makes many games insensitive to any paging enhancement. Until more than just a few architectures can handle large allocations without choking, games will have to remain insensitive. Most of the HBCC's features and capabilities are wasted on gaming.Also, I think too many people are underestimating HBCC, and the ability to store micro-code within vega. Doesn't that mean, RX Vega can load Vulkan, or DX12.1 microcode into local stores, like the 1X claims to do.. ?
I do not follow what you think is different about microcode loading. Microcode is used by everything. Some of the features that were added to cards over time, like HSA support, priority queues, HWS being enabled, and so on were the result of microcode updates. Sometimes, the chips that did not get those updates missed out because of limits to their microcode storage or handling. Vega changes its load method to use a path locked down by its platform security processor.
I dunno man, according to Reddit we're going to need Raja and Lisa to say it on a live stream in front of a large audience because we're not REALLY REALLY sure he was talking about primitive shaders.
Infinisearch
Veteran
Could you ask him if thats DX11 and DX12 or DX12 only?
If I'm understanding Rys correctly, Primitive Shaders don't require developer input. They're applied automatically in driver.
@Rys if you could answer that would be appreciated as well.
Anarchist4000
Veteran
Invoke the primitive shader through whatever API or mechanism AMD eventually provides. It seems the point of primitive shaders was to make their binning and work distribution more flexible. So a programmer could write a new, more efficient paths or fall back on the traditional pipeline. The actual fast paths likely follow a path beyond the limits of the traditional pipeline. Doesn't mean they can't defer interpolation or automatically perform other optimizations. Key difference being what used to be a driver optimization is becoming exposed to devs. Big chunk of the black box there.It was my understanding that the NGG Fast Path -culling would require use of primitive shaders, too. If they're done automatically, how can developer make sure NGG Fast Path -culling is used instead of the 'native', too?
With the recent open world craze and modding it will likely be used. Fallout 4, Skyrim, etc can easily use all available memory as gamers load all sorts of models and texture packs. Limited only by acceptable performance. HBCC is likely the key feature Bethesda was after as it would aid old and new games. Cases where the dev can't control the scene as a gamer plops objects everywhere inevitably building some giant castle.Until more than just a few architectures can handle large allocations without choking, games will have to remain insensitive. Most of the HBCC's features and capabilities are wasted on gaming.
Truly a wonder that a programmable replacement for the first stages can actually perform its most basic task and replace them.I dunno man, according to Reddit we're going to need Raja and Lisa to say it on a live stream in front of a large audience because we're not REALLY REALLY sure he was talking about primitive shaders.
The cited statement is literally saying it is not being exposed to devs. It was noted that GFX9 merged several internal setup stages, seemingly combining the stages that generate vertices that need position calculation and then the stages that processed and set them up. That sounds like it has to do with primitive shaders, or is what the marketing decided to call primitive shaders.Key difference being what used to be a driver optimization is becoming exposed to devs.
The prior shader stages didn't look like they were exposed to developers, so AMD might not be driven to expose the new internal stages all that quickly. Some of the work that occurs hooks into parts of the pipeline that have been protected from developers so far.
The stats I've seen for the gaming customer base may be out of date by now, but most systems they'd be selling to would be less well-endowed than a Vega RX. I do not think they are going to abandon those systems, and as such counting on a Vega-specific feature outside of coincidental use seems unwise.With the recent open world craze and modding it will likely be used. Fallout 4, Skyrim, etc can easily use all available memory as gamers load all sorts of models and texture packs. Limited only by acceptable performance. HBCC is likely the key feature Bethesda was after as it would aid old and new games. Cases where the dev can't control the scene as a gamer plops objects everywhere inevitably building some giant castle.
I would like to see an interview or some statement about Bethesda's pushing for a leading-edge feature like HBCC or similar tech, given their open-world engine isn't from this decade.
I'm curious about the internal makeup of the primitive shader pipeline, such as whether the front end is running the position and attribute processing phases within the same shader invocation, or if it's like the triangle seive compute shader+vertex shader customization that was done for the PS4.
The idea of using a compute-oriented code section to calculate position information and do things like back-faced culling and frustrum checking ahead of feeding into the graphics front end seems to be held in common.
Mark Cerny indicated that this was not always beneficial, since developers would need to do some preliminary testing to see if it made things better.
Potentially, the overhead of two parallel invocations and the intermediate buffer was a source of additional overhead.
If this isn't two-workgroup solution, then AMD may have noted from analyzing the triangle sieve method that it could take that shader and the regular vertex shader and throw it all in the same bucket, then try to use compile-time analysis to hoist the position and culling paths out of the original position+attribute loop.
Perhaps a single shader removes overhead and makes it more likely to be universally beneficial than it was with the PS4. If not, then going by the Linux patches it may be that it's not optional like it was for the PS4.
Analysis of the changes may explain what other trade-offs there are. Making a single shader out of two shaders may save one portion of the overhead and possibly reuse results that would have to be recalculated. However, it could also be that while it's smaller than two shaders it's still an individually more unwieldly shader in terms of occupancy and hardware hazards, and exposed to sources of undesirable complexity from both sides. The statement that it calculates positions, and then moves to attributes may also point to a potentially longer serial component. From the sounds of things, this is an optimization of some of the programmable to fixed function transition points, but the fixed function element is necessarily still there since the preliminary culling must be conservative.
edit: missing word
Last edited: