Yes, but if Fury is 300 watts and AMD said that Polaris is 2 times perf/watt (Koduri said 2,5)
I went back and checked, Koduri never mentioned Fury as the card he was comparing against. The presentation that did mention Fury only said 2x.
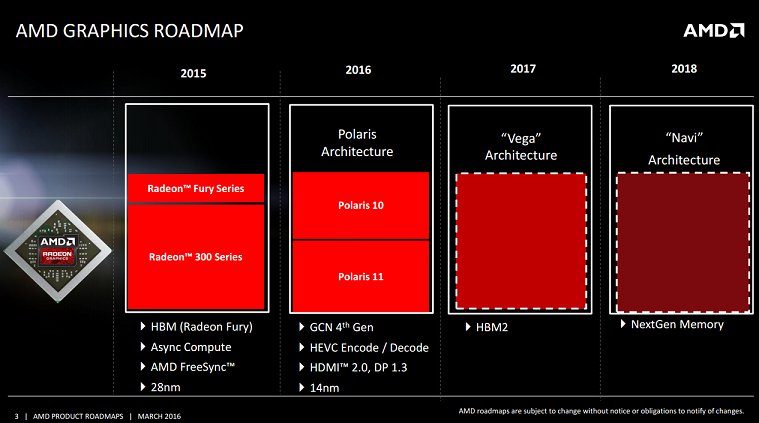
The Polaris architecture was designed to bring VR to the masses.
Note that they used 390(non-X) as the VR to the masses benchmark. I expect all lower-end P10 models to hit that, and the highest-end ones to go maybe just a little over 390X. If they could do much better than that on a 232mm^2 chip, it would be the biggest win in GPUs since, well, ever.
Polaris 10 also demo'd running Hitman DX12 at greater than 60 FPS at 2560x1440 which is actually comparable or faster than Fury X.
This needs the usual disclaimer that they get to pick the most impressive benchmarks for the ones that they show to the press. The specific area of Hitman they were using had a lot of complex, tesselated, occluded geometry that Fury has to process before it can throw it away. It just so happens that one of the big architectural improvements of Polaris that they have mentioned is better and earlier discard of occluded geometry. I suspect that the specific scene was chosen precisely because it plays to the strengths of the card and shows it in the best possible light.