The compiler knows how to keep the instruction stream valid.
The hypothetical hardware changes explicitly target behavior that AMD claims the compiler cannot determine ahead of time.
If the claim is that static analysis cannot be used to schedule for a dynamic behavior, how is it that it should be able to schedule for the required hazard avoidance of that behavior?
The static analysis doesn't depend on the 4 cycle cadence - it depends on a hardware thread having a constrained set of issues. SALU and VALU are not co-issued from the same hardware thread. The hazards caused by state being in one or the other ALU and required in the following instruction by the other ALU are fully understood.
GCN requires software to paper over hardware gaps in pipeline monitoring and varying paths taken to replace stale data, which is a physical question based on what the hardware is actually doing. Moving what amounts to 32 or 64-bit values in the case of scalar and mask values shouldn't take 20 cycles to "settle". It's a behavior wired into the pipeline and buffers between the independent pipelines that make up the CU, where the hardware does not check and does not update values and assumes the software will fill in the 20 hardware cycles of time it takes to get around to replacing the old data. The problem I see is with one possible embodiment that can drop a statically scheduled 20 cycles to 5 and pull in up to 15 more instructions subject to the stale data if the existing mask handling remains.
Any time some hypothetical new architecture has to decide whether to move state to another ALU, purely for the sake of efficient scheduling, a barrier placed by the compiler will show the hardware where and how it should schedule the move.
The decision making is not up to the compiler in this instance, and would involve a barrier instruction at every block boundary.
The placement of the barrier is also backwards from the memory and export barriers. These are counts based on increment/decrement upon issue/completion of an operation. This scheme needs a barrier that stops when nothing further has been issued yet and the prior instruction is already complete, it would need to be a cycle-counting hang or one that checks pipeline readiness--which would be a check to a pipeline interlock and redundant.
You forget that LDS and global memory operations have variable settling times and there is no consistency problem experienced there. The barriers for these operations are placed there by the compiler too, despite the fact that the compiler doesn't know the settling time.
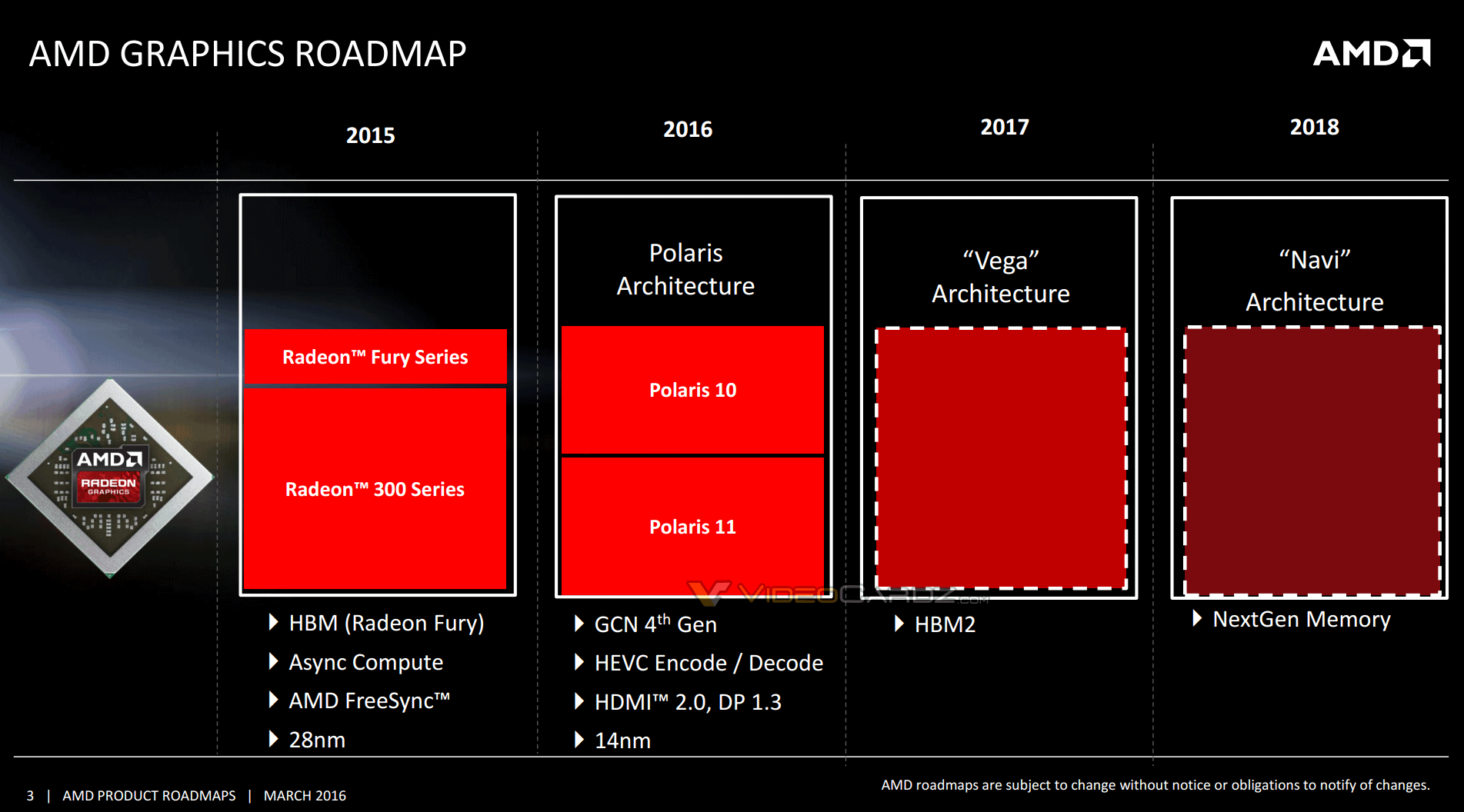
Those barriers currently exist. The wait states are listed for a portion of GCN where such barriers do not, and where the hardware literally runs blindly into undefined behavior, which I argue means GCN needs to change something in its hardware capabilities or software requirements. However, since it does look like the IP level of Polaris strives to match the prior one in software model, this may rule out any such scheme prior to Vega.
Since these are patents rather than more substantive disclosures, it may also be never.
It would be ironic if the way that execution is switched to a scalar ALU is using a SALU-specific code path generated by the compiler:
Code:
for each x
if bit_count(exec_mask) > 1 then
[VALU loop code]
else
[SALU loop code]
At least for the patent's scheme, it might not work since the front end scheduler can readily decide to not move a thread to the scalar unit at any given block, regardless of the execution mask. If, for example, a pair of threads on a 2-wide SIMD predicates one thread off while the scalar units are fully subscribed, the active vector thread remains on the SIMD. The claimed benefit was to match wavefronts to physical SIMDs , but a reduced number of wasted lanes was the consolation prize when perfection could not be achieved.
In the other direction, the patent allows for performance counters to prompt the front end to allocate threads to a SIMD with an execution mask in excess of the standard SIMD width and cadence, if it decides other bottlenecks make full ALU utilization counterproductive or unlikely.
The above conditional would need to be replaced with an instruction intended to query what hardware the CU decided to allocate it to. At least the patent appears to keep its allocation decisions at basic block boundaries, otherwise the check would have the potential to fail within a block.
The Scalar paper mentioned independent command streams for the scalar.
The paper posited a more explicit tracking within the program itself, in order to evaluate when utilization was below par.