Jawed
Legend
Well, duh, they are just PCs.Oh great, we have a console arms race on our hands.
Well, duh, they are just PCs.Oh great, we have a console arms race on our hands.
GCN ISA already includes moves twixt scalar/vector registersThere are wait counts for the various memory accesses and exports, but NOP or independent instruction padding handles the class of operations that involve sourcing or forwarding between vector and scalar elements. It would be an unenviable bug to have to trace through for a problem that dynamically may or may not occur based on what SIMD the scheduler chooses. The alternative can be an excessively pessimistic compiler that inserts enough NOPs to satisfy the worst case where a wait state of several 4-cycle vector issues gets multiplied by a 4x scalar issue rate.
 for cases that don't involve execution masks. The code is quite explicit already, so there's no bug lying in wait because some timings are different.
for cases that don't involve execution masks. The code is quite explicit already, so there's no bug lying in wait because some timings are different.EXEC-related cases would be some of the cases where NOPs or independent instructions are expected. There are shorter waits for vector writes to SGPRs that are then used as vector sources. I did not mention some of the shorter delays that may or may not show up like those for RAW for DPP instructions. Whether there is a wall-clock delay that is being hidden by the 4-cycle cadence may factor into what happens.GCN ISA already includes moves twixt scalar/vector registers
It makes everything work except where the ISA document requires that software put in wait states, which can be mandated by undetected accesses to specially-aliased registers like EXEC, a lack of forwarding, or some other kind of race condition where movement takes longer than 4 clock cycles to finish but there is no existing wait instruction that can halt further issue.The 4 cycle cadence makes everything work (current GCN):
The multiple-length SIMD patent does not give a CU-wide RF, and even provides for the scenario where a wavefront can split across multiple SIMDs, based on how the front-end is able to pack lanes.As soon as we start talking about a CU-wide RF then the timings have to become more slack, because each SIMD requires an operand collector (and scatter unit). The code doesn't need NOPs to cover this since any available alternative hardware thread can execute in the slack. If there are no alternative hardware threads, then it's just a stall. You don't need an explicit NOP to make that happen.
We aren't talking about 32-core 4GHz workstation CPU, but low-power conservatively-clocked derivate of mobile low-end architecture. It may consume about 5 % of the total bandwidth at full load, maybe even less.Can't compare bandwidth with desktop parts as desktops don't have to deal with memory contention like the PS4 has to. The GDDR5 on PS4 has to service both the CPU and GPU effective bandwidth for the PS4 will generally be lower than the number stated.
Regards,
SB
We aren't talking about 32-core 4GHz workstation CPU, but low-power conservatively-clocked derivate of mobile low-end architecture. It may consume about 5 % of the total bandwidth at full load, maybe even less.
Raw GPU performance is less than 6 % higher than R9 380X, while the bandwidth is 20 % higher.
All of a sudden, Polaris 11 doesn't offer "console-level performance" at subnotebook form factor.
Definition of "cycles" probably complicates things. Paper mentioned dynamic clocks in addition to the cadence changing. Could be a fixed 2/4x multiplier to keep things in sync, but SIMDs are probably clocked asynchronously. Might be why they made no mention of partial 16 ALU SIMDs as an 8x multiplier is probably pushing the limits.4 consecutive cycles
No, it always works.GCN as we know it is fragile in this case,
Yes, I would expect the ISA to be extended to cover the specific new cases. I can't think of any reason why existing code would just break. At least none that can't be blamed on the compiler people.It might require something to change in GCN as it will be to support this.
It's pretty glib about that problem.The multiple-length SIMD patent does not give a CU-wide RF, and even provides for the scenario where a wavefront can split across multiple SIMDs, based on how the front-end is able to pack lanes.
As far as requiring an operand collector, I may have skimmed past that being mentioned.
Improved AMD GCN
Primitive Discard Accelerator could be big and transparent. Prefetching. ASTC for textures which could be big. Would require some console specific content and repackaging, but not unreasonable. Could also be better color compression for ROPs.What kind of hardware improvement, probably borrowed from Polaris, is possible while keeping a perfect hardware compatibility with regular PS4 games? Color compression? What else?
I wouldn't say it always works if the instruction stream can fail to pad or perhaps purposefully not pad with NOPs or independent instructions and yield incorrect or undefined behaviors. The usual bare-minimum for that kind of description is that the hardware at least would stall.No, it always works.
If operands have to be moved to ALUs (either just in time or in bulk) then it's a variant of the already existing mechanisms that GCN has for situations where static analysis of code indicates that state needs time to settle before an ALU can consume operands.
The multi-length patent's provision for a high-performance scalar unit that explicitly abandons the 4-cycle cadence changes the implicit number of cycles the earlier static analysis would depend on. The motivation of the patent is the capture of information that cannot be determined by the compiler, and so defies the use of static analysis for this purpose in general.I can't think of a more finely-grained consistency problem that is introduced specifically by any of these patent documents.
It would need the ability to source an additional operand if FMA were fully implemented. LDS sourcing is another thing the current SALU cannot do, either.In other words, I'm betting against variable width SIMDs. The most I'm expecting is that SALU inherits the full VALU instruction set (I expect there are some instructions that aren't worth porting over). In which case the bandwidth/latency problems involved in moving state back and forth between per-VALU RFs and the SALU RF are so minor that it isn't worth all this debate. Certainly none of these patents.
Yes, there's devil in the details of the SALU ISA, e.g. will it have FMA or will it use a macro to do FMA in two successive instructions?
Frame buffer compression would be helpful. There's also the possibility that "improved GCN" is the PS4's original IP improvements over the original GCN.What kind of hardware improvement, probably borrowed from Polaris, is possible while keeping a perfect hardware compatibility with regular PS4 games? Color compression? What else?
Ironic mode ON
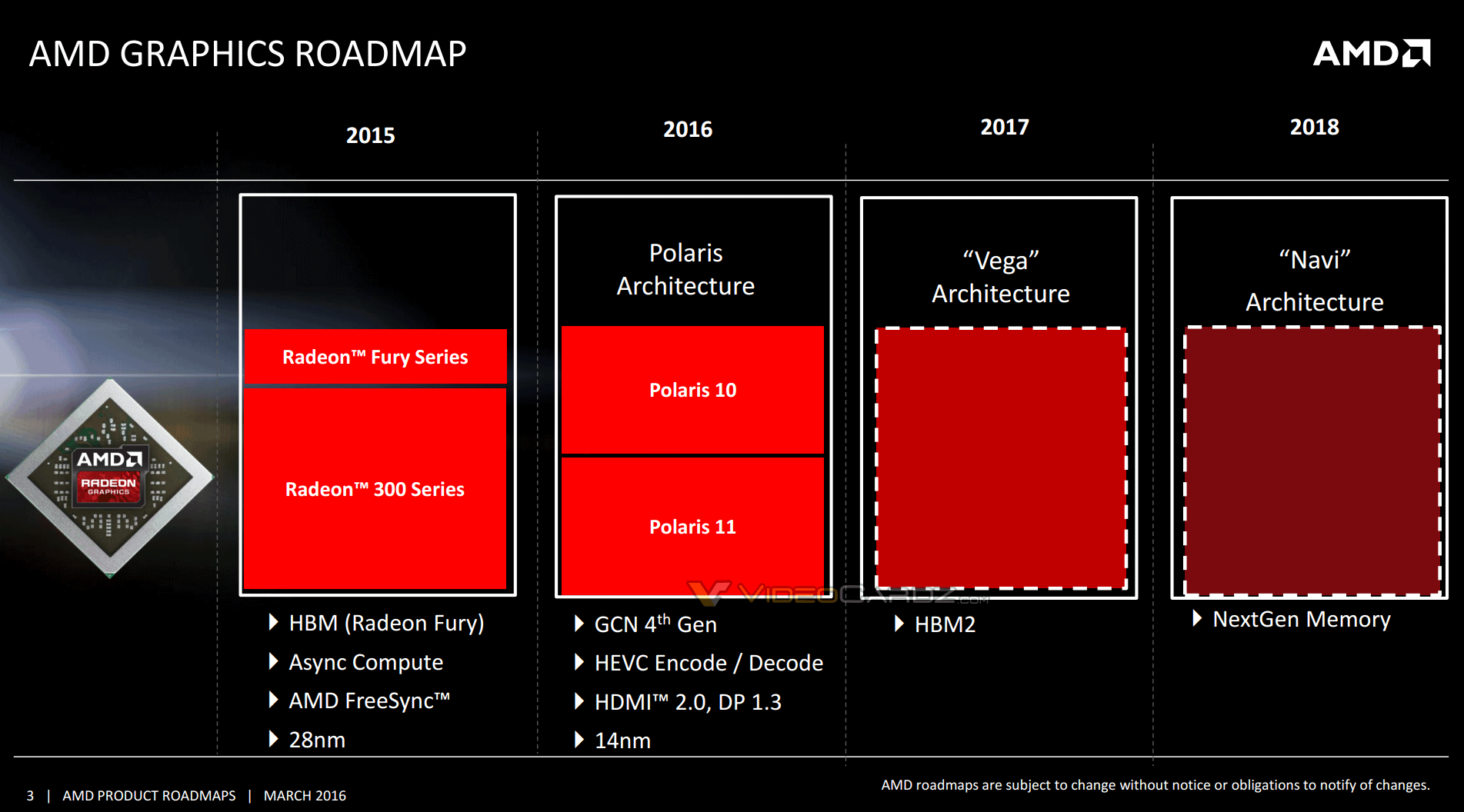
So AMD is telling us that Polaris, Vega and Navi are all the same except memory?
Ironic ode OFF
The compiler knows how to keep the instruction stream valid.I wouldn't say it always works if the instruction stream can fail to pad or perhaps purposefully not pad with NOPs or independent instructions and yield incorrect or undefined behaviors. The usual bare-minimum for that kind of description is that the hardware at least would stall.
The static analysis doesn't depend on the 4 cycle cadence - it depends on a hardware thread having a constrained set of issues. SALU and VALU are not co-issued from the same hardware thread. The hazards caused by state being in one or the other ALU and required in the following instruction by the other ALU are fully understood.The multi-length patent's provision for a high-performance scalar unit that explicitly abandons the 4-cycle cadence changes the implicit number of cycles the earlier static analysis would depend on. The motivation of the patent is the capture of information that cannot be determined by the compiler, and so defies the use of static analysis for this purpose in general.
It would be ironic if the way that execution is switched to a scalar ALU is using a SALU-specific code path generated by the compiler:If a 4-cycle operation dependence requires 5 NOPs or independent operations, that is 20 cycles of settling time. The high-performance scalar unit that a normal wavefront can be switched to on the fly quadruples the issue rate in terms of actual cycles.
The compiler could cover it, if it took the onerous step of adding 20 NOPs in the off-chance the hardware might dynamically subvert the wait states.
The other smaller SIMDs may also change the cadence on the fly, if the patent is to be believed, with varying levels of pessimism required of the compiler.
It would need the ability to source an additional operand if FMA were fully implemented. LDS sourcing is another thing the current SALU cannot do, either.
Getting all that into place might make the next step of creating a pipelined FMA unit incremental in complexity. Keeping it as a singular operation would avoid the need to track macro progression in case the GPU opts to preempt things in the next 15 cycles.
for each x
if bit_count(exec_mask) > 1 then
[VALU loop code]
else
[SALU loop code]
Looking at existing GPU that sound OK. A big missing part of picture is actually the number of ROPs which is of great when it comes to pushing out lots of pixels.227% more GPU throughput and 31% higher CPU clock, relying on only 23% bandwidth boost. Probably an inevitable compromise for a mid-term upgrade.