Install the app
How to install the app on iOS
Follow along with the video below to see how to install our site as a web app on your home screen.
Note: This feature may not be available in some browsers.
You are using an out of date browser. It may not display this or other websites correctly.
You should upgrade or use an alternative browser.
You should upgrade or use an alternative browser.
AMD: Speculation, Rumors, and Discussion (Archive)
- Thread starter iMacmatician
- Start date
- Status
- Not open for further replies.
D
Deleted member 2197
Guest
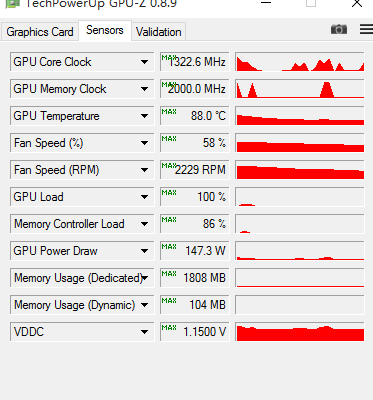
Now, here’s some stuff that was posted at Chiphell. We get new GPU-Z screengrabs showing overclocked settings and TDP at 147.3W.
https://www.chiphell.com/thread-1609649-1-1.html
Retailer video - 480 Crossfire in action.
http://videocardz.com/61456/video-presentation-of-radeon-rx-480-running-in-crossfire-leaked
Last edited by a moderator:
Jawed
Legend
I think they're talking about rejecting triangles before they get rasterised.Given the lack of actual data, I'd like to hijack this comment for a quick education about better discard: what is it and what are the opportunities that are allegedly still open to be exploited?
I'm assuming the better discard is geometry based? What is possible other than backface removal?
Or they talking about better pixel discard? And, if so, is there a lot of thing to be improved there?
My theory is that pixel shading/ROP is bottlenecked by useless triangles living for too long and clogging up buffers, when they shouldn't even be in those buffers. The ROPs can't run at full speed (e.g. in shadow buffer fill) if triangles are churning uselessly too far through the pipeline before being discarded.
The triangle discard rates for backface culling and tessellated triangle culling are, in absolute terms, still very poor:
http://www.hardware.fr/articles/948-10/performances-theoriques-geometrie.html
The relative rate for culling when tessellation is active appears to be the only time AMD is working well.
itsmydamnation
Veteran
I dont agree with your analysisI don't think Polaris is profitable at this point and when you add in development costs, I don't think it ever will be.
So your Development costs factor in money form Sony/MS? Assuming P10 has 32 ROP's thats looking a lot like a large chunk of a PS4 neo SOC.
The last time we had cards this cards this cheap on a new node with a comparable size was the 3870 and 3850 and these were 220 and 180 dollar cards. These cards were 20 percent smaller and on a vastly cheaper node. Add in inflation in well over 8 years and it doesn't make sense that the rx 480 and the newly demoted rx 470(the cut down of polaris) is 200 and 150 respectively. And it all has to do with costs. Lets look at wafer cost first.
What inflation over the last 8 years? We have had a big global down turn, Government have pumped in trillions and lowered interest rates to 0%, out side of currency fluctuations which where i living have gone from peak ( 110 to USD to ~75 to USD) there's been nothing....

Of course these are first run wafer costs, but the point still stands. If AMD had any time to raise graphic card prices, it would have been completely justified this time around. But for some reason, its never been cheaper. Add in development costs as seen below and basically Kyle Bennett might be right, in AMD entire graphic product stack might have collapsed, not because they are bad cards those, but because they are unprofitable.
Things to consider:
1. AMD and GF share a large shareholder, there could be give and take on margins at both points.
2. Those wafer costs look way to high, we have heard ranges of no cost increase to slight cost increase per transistor, 28nm to 14nm ( like this which is %15 more per transistor)
3. Then Nvidia is also selling the 1070 at a massively lower margin then 970/980:
P10 232mm sq gives 246 GPU's a die
GP104 312mm sq gives 177 GPU a die
Assuming 0.18 errors a mm sq for both there are on average 33.7% more errors per die on GP104
You would expect somewhere around 33% more total failure chips per wafer for GP104 then P10
Im not even going to guess total failure rates but lets say Polaris has 15% (lol i just did) that means GP104 has 20.3% falure rate, thats makes it 209 vs141 dies
according to steam 970 outsells 980 5:1 so i will keep the same ratio for 1070 to 1080
also have to remember that GDDR5x will have an additional cost over GDDR5 but i have no way to factor that in
GP104 will have a more expensive cooler which again i can't factor in
so if 209*200= 41,800 of card revenue ( ~$170 470, $200 480, $229 8gb 480) is a loss ( lets call it small)
then ( 22*599 + 117*379 = 57890) Now that sounds like a big difference but nvidia has gross margins in Q1 of 58% which would require a wafer revenue of 66,044 which means their gross margin for GP104 is 30% or nearly 1/2 of what the average NV gross margin was in Q1. if we assume NV margin is 58% then break even revenue is 24,314.
from that number that would Put polaris 10 right around 28% gross margin which is just below AMD product wide 32%. But AMD also expects this to be a very high quantity part so you can take a smaller margin if needed.
this also assumes there isn't a magical greater then 36 CU P10 ( i dont think so but until die shots nothing can be known).
There is no competition right now, more importantly it looks like AMD is going to have at least an order of magnitude more cards at launch, What about the revenue loss NV is taking having so few cards to sell, no more GM204 being manufactured yet still having all that OPEX cost to pay.......So why did AMD price their cards so low then. The answer is competition.
You could say 379 was forced on Nvidia just the same.The 1070 for marketing purpose and it's supposed 379 dollar price is a price killer for AMD. If the 1070 is 35-40% faster than a rx 480, then the 200 and 229 price wasn't a consciously made price point for them. It was forced upon them. This is because Nvidia is simply the stronger brand and has the greater marketshare. This means at similar pricepoints and similar price to performance, nvidia will take marketshare away from AMD. If AMD priced their rx 480 at 300 dollars, it would be a repeat of tonga vs the gtx970/980 as far as marketshare bleed.
Tonga didn't compete with the 970/980 and AMD market share improved with the 3XX series, A large part of the damage was stock 290/290X reviews as the 970 appears to be the big decisive win for NV.
And how did you come to that? In January they compared to a GTX950 which sells for sub <$200. Nothing else was hinted at price wise at all in JanuararyI think from the slides shown to us in January, AMD wanted to price this chip in the 350 range because AMD initially indicated this to be the sweet spot range. That's was also the price of pitcairns which was again made on a cheaper node, and was smaller.
you mean GP106?Hopefully for AMD sake, the gm206 arrives late and Nvidia pricing isn't aggressive.
How do you expect GP106 to reach Polaris 10 level of performance? 256bit bus? 128/192bit bus with GDDR5x ( whats the extra cost, the availability look like?, 4gb or 8gb). When do you think it will show up, if its making it for back to school it kind needs to be ASAP. If we assume GP106 is the same size as P10 with 256bit bus then based off the numbers before it would need to sell for $277 for 58% margin again NV could take a lower margin.
Sure Polaris isn't looking like RV770 but it's nowhere near R600 and nowhere near as bad a situation you make out.
I dont agree with your analysis
you mean GP106?
How do you expect GP106 to reach Polaris 10 level of performance? 256bit bus? 128/192bit bus with GDDR5x ( whats the extra cost, the availability look like?, 4gb or 8gb). When do you think it will show up, if its making it for back to school it kind needs to be ASAP. If we assume GP106 is the same size as P10 with 256bit bus then based off the numbers before it would need to sell for $277 for 58% margin again NV could take a lower margin.
Sure Polaris isn't looking like RV770 but it's nowhere near R600 and nowhere near as bad a situation you make out.
I don't think GP106 will be bandwidth starved, the gp104 1070 has the same bandwidth as rx480 but it goes a lot faster, nV's cards might not need the bandwidth.
Yeah the rest of what you stated is spot on. We can't make assumptions on AMD's rx 480 margins as being low or high, all we can say is they aren't selling at a loss.
Alessio1989
Regular
A game is not only based on frame buffers (front+back buffers). A game is based on resources too. Sharing resources requires a balance between decoupling and transferring. If you saturate the bandwidth for the frame buffering, you have no more bandwidth for resource transferring. Whoops, Huston we have a problem here.You say BW is the biggest issue in today's computing. And it's not about AFR, it's about the other stuff.
An SLI bridge off loads sending a complete image from the PCIe bus, freeing up to 2GBps for that other stuff that you care about.
2GBps is more than enough to transfer a 4K image at 72Hz, allowing for 144Hz aggregate, so that's plenty for most high end solutions today. It's also plenty to transmit one eye of 2kx2k VR images at 90Hz.
So exactly what are you griping about? The fact that it costs a bit more? Is that it?
The cost of gpu is just a fraction of the total cost of the card. Partners won't buy your product if they cannot take good margins from it. Given the Polaris boards look much better compare to the price they make you pay than the 1070/80 I think AMD is just fine with their margins. I also don't think AMD have the money to just accept 0 profit on their highest selling product(biggest TAM).
Now taking amds words of the 480 being a card for the "future" I think they are planning in reusing it as lower tier gpu when the new generation comes and then have a "full line up of Premium VR capable". But that's just a while guess from my part.
Enviado desde mi HTC One mediante Tapatalk
Now taking amds words of the 480 being a card for the "future" I think they are planning in reusing it as lower tier gpu when the new generation comes and then have a "full line up of Premium VR capable". But that's just a while guess from my part.
Enviado desde mi HTC One mediante Tapatalk
D
Deleted member 2197
Guest
I am in two minds about the 1060 and the performance of its192-bit bus.I don't think GP106 will be bandwidth starved, the gp104 1070 has the same bandwidth as rx480 but it goes a lot faster, nV's cards might not need the bandwidth.
Yeah the rest of what you stated is spot on. We can't make assumptions on AMD's rx 480 margins as being low or high, all we can say is they aren't selling at a loss.
But then the 1070 with its 256-bit bus competes well (putting aside OC) against a reference 384-bit 980ti/Titan X at all resolutions, and they have the ideal structure in terms of GPC/SM for Maxwell.
So it is possible the 1060 will perform well even with its smaller bandwidth, relative to say 980; although the concern may be it has only half the GPC with 60% of the SM.
Maybe too much of a compromise if (just emphasising as IMO it is unknown its exact position in the overall product tiers, such as will there be a ti) it is meant to target performance window close to 980.
Cheers
Last edited:
Yeah, I totally don't get it.A game is not only based on frame buffers (front+back buffers). A game is based on resources too. Sharing resources requires a balance between decoupling and transferring. If you saturate the bandwidth for the frame buffering, you have no more bandwidth for resource transferring. Whoops, Huston we have a problem here.
Solution A: use PCIe to transfer some stuff + use a dedicated interface for some other stuff, when possible.
Solution B: use PCIe for everything.
Question: which system has the largest aggregate BW?
Except that there's no Solution A on markets.Yeah, I totally don't get it.
Solution A: use PCIe to transfer some stuff + use a dedicated interface for some other stuff, when possible.
Solution B: use PCIe for everything.
Question: which system has the largest aggregate BW?
NV's solution is "use dedicated interface for everything" (old implicit, possible with game dev implicit) or "use PCIe for everything" (dev explicit, dev implicit)
Ok. I assume that this would be a relatifely minor performance optimization?I think they're talking about rejecting triangles before they get rasterised.
My theory is that pixel shading/ROP is bottlenecked by useless triangles living for too long and clogging up buffers, when they shouldn't even be in those buffers. The ROPs can't run at full speed (e.g. in shadow buffer fill) if triangles are churning uselessly too far through the pipeline before being discarded.
Since not doing any work at all is by far the best way to improve performance, you'd think that in decades of GPU design this would have had already its share of attention.
That's what prompted my question in the first place: it seemed to me that geometry discard is a problem without a lot of solutions.The triangle discard rates for backface culling and tessellated triangle culling are, in absolute terms, still very poor
Except that there's no Solution A on markets.
NV's solution is "use dedicated interface for everything" (old implicit, possible with game dev implicit) or "use PCIe for everything" (dev explicit, dev implicit)
So when there's Textures to be loaded, NV doesn't send them over PCIe?
Alessio1989
Regular
Ok, waiting for GCN Gen 5...
PS: I am only talking about isa....
PS: I am only talking about isa....
Last edited:
Alessio1989
Regular
Solution A, but NVIDIA does not use PCI-E for resource transferring between GPUs. Let's call it "solution C"Yeah, I totally don't get it.
Solution A: use PCIe to transfer some stuff + use a dedicated interface for some other stuff, when possible.
Solution B: use PCIe for everything.
Question: which system has the largest aggregate BW?
Alessio1989
Regular
Not between PCI-E. There is no GPU1-PCI_E-GPU2 on NV SLI/linked adaptors mode.So when there's Textures to be loaded, NV doesn't send them over PCIe?
Now we're getting somewhere.Solution A, but NVIDIA does not use PCI-E for resource transferring between GPUs. Let's call it "solution C"
Do you actually believe this?
Are you saying that, in CUDA, I can use copy engines to transfer data over PCIe, or use pinned memory to do GPU originated DMA acceseses over PCIe, but somehow Nvidia hasn't figured out to do that for graphics?
That's an extraordinary strong claim and you're going to need to back that up one way or the other.
Alessio1989
Regular
NVIDIA GPUDirect is about network transferring, not about GPU-to-GPU in the same system trasnferring.
https://developer.nvidia.com/gpudirect
That's why they still use SLI bridges (AMD used CFX bridges until GCN Gen 2 where it switches to direct DMA access via PCI-E).
This is why you need a copy of the same resources used on all GPUs on NVIDIA GTX cards and AMD GCN Gen 1 cards. Direct3D 12 allows to share (ie: no need to have different copies) resources between GPUs on linked adaptor modes, and NV sharing tier is better then AMD sharing tier (tier2 vs tier1), however NVIDIA has lower bandwidth capabilities (~2Gbps?) compared to AMD GCN Gen 2+ cards (full PCI-E available bandwidth).
Before D3D12 it was not a major issue since sharing resources was not supported by the API (NVLINK and AGS allow some control about though... AGS also now allows more control in a D3D12 stile now in the last update).
So, marketing speaking SLI bridges still makes sense in most of games since most of games still use AFR-like techniques when multi-GPU is supported.
But AFR is going to die. AOS showed in an early D3D12 title how good can explicit multi-GPU be outside linked adaptor modes (ie CFX/SLI).
https://developer.nvidia.com/gpudirect
That's why they still use SLI bridges (AMD used CFX bridges until GCN Gen 2 where it switches to direct DMA access via PCI-E).
This is why you need a copy of the same resources used on all GPUs on NVIDIA GTX cards and AMD GCN Gen 1 cards. Direct3D 12 allows to share (ie: no need to have different copies) resources between GPUs on linked adaptor modes, and NV sharing tier is better then AMD sharing tier (tier2 vs tier1), however NVIDIA has lower bandwidth capabilities (~2Gbps?) compared to AMD GCN Gen 2+ cards (full PCI-E available bandwidth).
Before D3D12 it was not a major issue since sharing resources was not supported by the API (NVLINK and AGS allow some control about though... AGS also now allows more control in a D3D12 stile now in the last update).
So, marketing speaking SLI bridges still makes sense in most of games since most of games still use AFR-like techniques when multi-GPU is supported.
But AFR is going to die. AOS showed in an early D3D12 title how good can explicit multi-GPU be outside linked adaptor modes (ie CFX/SLI).
Last edited:
I'm thinking it's more about "NVIDIA hasn't figured out a way to use both at once, and think SLI bridges are better for gaming"Now we're getting somewhere.
Do you actually believe this?
Are you saying that, in CUDA, I can use copy engines to transfer data over PCIe, or use pinned memory to do GPU originated DMA acceseses over PCIe, but somehow Nvidia hasn't figured out to do that for graphics?
That's an extraordinary strong claim and you're going to need to back that up one way or the other.
You need to look at it from a lower level.NVIDIA GPUDirect is about network transferring, not about GPU-to-GPU in the same system trasnferring.
https://developer.nvidia.com/gpudirect
That's why they still use SLI bridges (AMD used CFX bridges until GCN Gen 2 where it switches to direct DMA access via PCI-E).
GPUDirect allows a GPU to access a framebuffer in, say, a video capture card without CPU memory involvement.
Replace "video capture card" with "other GPU". Do you see the light?
In a single GPU solution, what happens when there's not enough local memory to access a texture? It gets stored in CPU DRAM and the GPU accesses it from there. From a PCIe point of view, it would make no difference to store it in another GPU instead.
Answer me this: on an old SLI bridge, you'd completely saturate the BW with just the final image. There'd be no BW left for any resource sharing at all. Performance would be way worse than single GPU. Yet it's not.
And finally: can you explain how SLI worked with triple 4K surround and the old bridge? It's BW being way lower than the required BW for the final pixels alone?
The reason I never considered solution C is that it'd be momentally stupid to do it this way, and it just wouldn't work at all.
- Status
- Not open for further replies.
Similar threads
- Replies
- 90
- Views
- 18K
- Replies
- 2K
- Views
- 238K
- Replies
- 20
- Views
- 7K