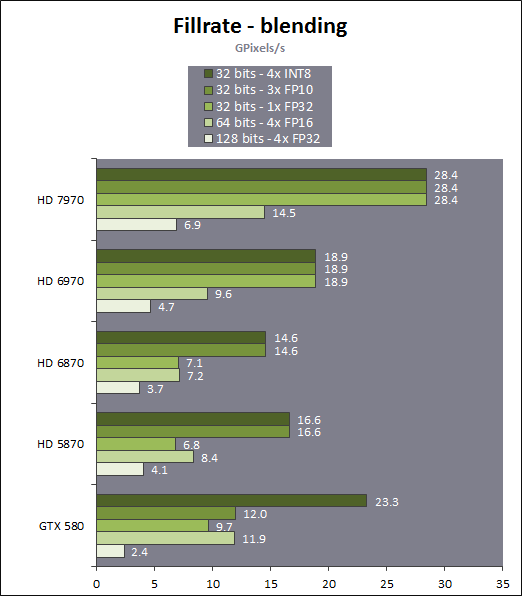
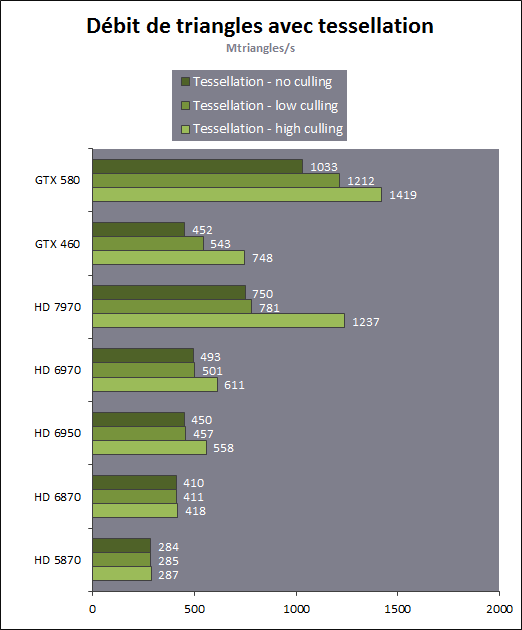
Going off the same tangent, with my calculations I end up with a ~500mm2 die with ~1024CC. Again, this is based on the assumption that this chip is closer to Fermi than Kepler.Doing a rough estimate, I would guess a dumb shrink of GF110 would reduce the die size from 529mm² to be something in the ~315mm² range (memory interface doesn't shrink, TSMC's HKMG processes offer only ~1.8 times the transistor density of 40G without following special layout rules). NVidia needs to put some more tricks in it, a shrunk GF110 isn't going to beat Tahiti in any convincing way. It may be able to match it, if they invest everything of the 28nm process advantage in increased clocks (meaning power consumption would be the same as a 40nm GF110). I think it is not a viable option.
And if AMD does another Cayman for 28nm, we might see a slightly more aggressive packing density and they could get 40CUs in less than 400mm2 to respond to Kepler.
Last edited by a moderator:
")