Install the app
How to install the app on iOS
Follow along with the video below to see how to install our site as a web app on your home screen.
Note: This feature may not be available in some browsers.
You are using an out of date browser. It may not display this or other websites correctly.
You should upgrade or use an alternative browser.
You should upgrade or use an alternative browser.
AMD: Southern Islands (7*** series) Speculation/ Rumour Thread
- Thread starter UniversalTruth
- Start date
Yep cause each "engine" only had one SIMD. The easiest way to look at it is by LDS. Each CU has an LDS shared across all four SIMDs so the CU is the unit in the hierarchy that workgroups are bound to. Very much like nVidia's SM. Interesting that there was no mention of dedicated transcendental units, guess those instructions will run on the ALUs as well.
They'll be there. Just not mentioned here.Interesting that there was no mention of dedicated transcendental units, guess those instructions will run on the ALUs as well.
The TMUs ("Filter") are mentioned in this slide:Iam wondering if the TMU-s are still in CU-sNot a single slide mentioned them.
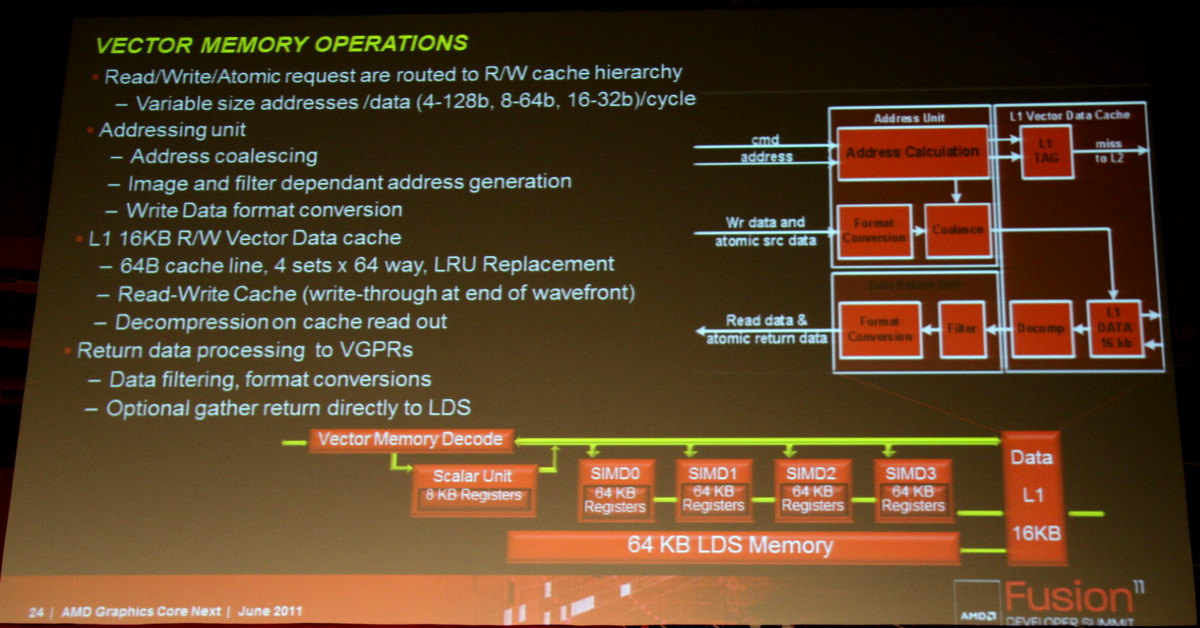
So AMD is going to unify GP-L1 cache and Tex-L1 (and keep LDS separate) while Fermi unified local memory and GP-L1 and kept the Tex-L1 separate. And AMD is going to use a compressed L1 for textures like nvidia. Current L1 appears to be uncompressed, 128 way (full) associative 8 kB. That may enable more efficient bandwidth use.
Last edited by a moderator:
I think it should be (a), else it would break dx11 spec.
You just need to expose a spec. conformant view, if you have parallel views (like DX-concurrent OpenCL-queues) doesn't make it spec. breaking.
If a kernel declares a workgroup needs only 16 kB of it, you can run 4 groups without breaking any spec.If a spec requires a certain amount of local memory, then not exposing that amount is spec breaking.
If a kernel declares a workgroup needs only 16 kB of it, you can run 4 groups without breaking any spec.
What about kernels written assuming 32kb local mem (dx11)?
Anyway, now the re design of alu organization is clear which was my original question. Instead of one vector thread over four cycles issuing a 4 wide vliw bundle per clock, now it does 4 vector threads each issuing single instruction per clock.
I think it's one instruction from four threads over four cycles. The batch/workgroup size is still 64.
I think it's one instruction from four threads over four cycles. The batch/workgroup size is still 64.
If instructions are sourced from 4 different threads, they might as well be from 4 different IP's each. I think the organization is similar to fermi which dual issues from 2 warps. Here it quad issues from 4 different wavefronts.
If instructions are sourced from 4 different threads, they might as well be from 4 different IP's each. I think the organization is similar to fermi which dual issues from 2 warps. Here it quad issues from 4 different wavefronts.
I meant one instruction from each hardware thread, with each instruction taking four cycles.
You can run at least two.What about kernels written assuming 32kb local mem (dx11)?
A kernel still declares how much it needs. If the kernel at hand uses less than the full 32kB, there is still the opportunity to run more than a single workgroup even on Evergreens. The specification just limits the maximum size a workgroup can use. You can write a kernel where a workgroup uses only 256 Byte for instance. One doesn't have to assume each workgroup will use 32kB, a kernel declares local memory usage. That declaration determines the maximum number of simultaneous thread groups.
Last edited by a moderator:
What do you mean? Isn't that how it works now?!? Does not matter if it is nvidia or AMD, R700/Evergreen/NI or G80/Fermi. It always works in the same way.While that would work, I don't think any IHV will try such a solution.
OpenGL guy
Veteran
Why not?While that would work, I don't think any IHV will try such a solution.
 We know the LDS usage at compilation time, so we can easily manage LDS resources at dispatch time either in the GPU or in the driver.
We know the LDS usage at compilation time, so we can easily manage LDS resources at dispatch time either in the GPU or in the driver.If a kernel declares 32KiB of LDS usage, then you would only get one wavefront per SIMD, but if you only used 1 KiB of LDS then we could schedule up to 32 wavefronts per SIMD.
What do you mean? Isn't that how it works now?!? Does not matter if it is nvidia or AMD, R700/Evergreen/NI or G80/Fermi. It always works in the same way.
Yep, been that way since G80 and CUDA 1.0.
I like AMD's approach of having specialized units all leveraging a shared pool of L2 and CU's. Very clean and very scalable. The shared, coherent cache is a real enabler.
itsmydamnation
Veteran
http://twitter.com/#!/DKrwtDavid Kanter said:don't know about schedule, but probably 28nm so late this year maybe. VLIW4 was a small change, but a precursor to the new uarch.
pretty amazing if VLIW was always planned to just be a 1 gen stop gap, AMD did a great job at not letting that one out of the bag!!!!
really looking forward to your artical David!!!!!!
Why not?
If a kernel declares 32KiB of LDS usage, then you would only get one wavefront per SIMD, but if you only used 1 KiB of LDS then we could schedule up to 32 wavefronts per SIMD.
Sure, but designing your hw assuming devs will use litle LDS when spec exposes 32K is a poor design choice. Although something that will work.
This micro discussion on LDS is getting derailed.
Similar threads
- Replies
- 3K
- Views
- 640K
- Replies
- 3K
- Views
- 700K
- Replies
- 1K
- Views
- 397K