So RDNA2 doesn't overclock, basically maintains a clock in a 50-100mhz range and it's power consumption what really varies. Which is very aligned with what PS5 does, and at even higher clocks.
This might come down to the improved circuit implementation and better characterization of the silicon. There was often more consistent behavior out of earlier GPUs once the overgenerous voltage levels were pruned, and it seems AMD has put physical optimization work that has been sorely lacking to an extent I hadn't considered.
Also, I've just realized that XSX is really the only RDNA2 based GPUs with 14 CUs per SA. The rest of them including the PS5 have 10. I wonder what are the pros and cons of the approach.
Wavefront launch seems like it could be handled at the shader engine level, which means the average lifetime of wavefronts need to be higher to avoid underutilization. Per shader array resources would have nearly 50% more contention, so things like the L1 and export bus could be more crowded.
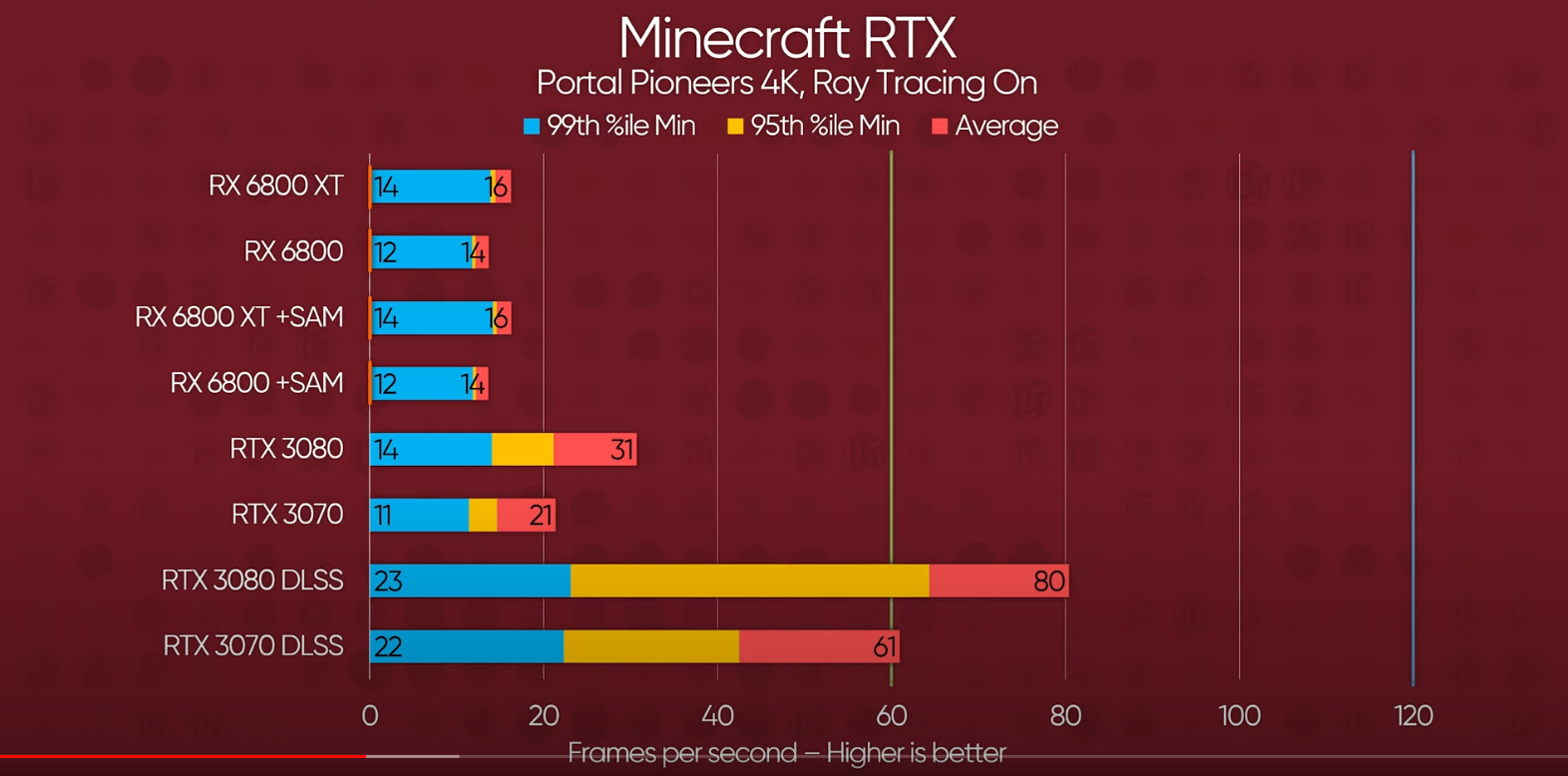
It stands out how close the minimums and average are. Given how much broader the other implementation is between minimum and average, it feels like there could be some driver or software issue capping performance--or there is a very pervasive bottleneck.
4K is really poor. The Infinity Cache "virtual 2TB/s" bandwidth is even more wasted than 5700XT's 448GB/s. Wow.
Some elements of the architecture may not have seen the same improvement. It does seem like the L2 hasn't received much attention, and if we believe it played any role in amplifying bandwidth signficantly in prior GPUs, not increasing its bandwidth or concurrency means it's amplifying things significantly less.
I'm also curious about getting the full slide deck, including footnotes. The memory latency figures are something I'm curious about. The improvement numbers do seem to hint that there's substantial latency prior to the infinity cache, which deadens some of its benefits.
It's also possible that if it's functioning as a straightforward victim cache that it's thrashing more due to streaming data. The driver code mentioning controlling allocation would seem to point to more guidance being needed to separate working sets that can work versus those that thrash even 128MB caches.
From my developer conversations AMD is just behind - it is a hardware difference. Their RT implementation does not accelerate as much of the RT pipeline. It does not accelerate ray traversal, so an AMD GPU is spending normal compute on that in comparison to NV having a hw unit in the RT core doing that. It is also getting contention due to how it is mapped in hardware. I have been told AMD RT is decidedly slower at incoherent rays than NV RT implementation. So the more incoherent rays a game has, the more rays shot out, the more objects possibly hit... the greater the difference in relative performance in the architectures becomes. But I would like to test it to see where exactly the differences lie.
I'm curious if there's also an effect based on not just incoherence but also how quickly the rays in a wavefront resolve. Incoherence can bring in a lot of extra memory accesses, but being tied together in batches of 32 or so can also lead to a greater number of SIMD-RT block transactions if at least one ray winds up needing measurably more traversal steps than the rest of the wavefront.
It looks like AMD does credit the infinity cache for holding much of the BVH working set, and apparently the latency improvement is noted. That does point to there being a greater sensitivity to latency with all the pointer chasing, but that can go back to my question about the actual latency numbers. Even if it's better, it seems like it can be interpreted that the latency figures prior to the infinity cache are still substantial.
View attachment 4939
I think this explains it. AMD said 58% cache hit rate at 4K and it looks like ~75% at 1080p and ~67-68% at 1440p so it's a significant drop off at 4K.
It does seem to show that even at the large capacity offered that there's a lot of accesses that remain very intractable for cache behavior. If the old rule of thumb that indicated that miss rate drops in proportion to the square root of cache size, the cache would have been more than sufficient to get very high hit rates.