Just to be clear (maybe i missed something): You're talking about full ASIC-design DP, not 1:1 SP/DP rate?Presumably AMD is going to continue putting full-speed DP into its enthusiast chips,[...]
Install the app
How to install the app on iOS
Follow along with the video below to see how to install our site as a web app on your home screen.
Note: This feature may not be available in some browsers.
You are using an out of date browser. It may not display this or other websites correctly.
You should upgrade or use an alternative browser.
You should upgrade or use an alternative browser.
AMD: Pirate Islands (R* 3** series) Speculation/Rumor Thread
- Thread starter iMacmatician
- Start date
-
- Tags
- amd
Erm.. if HBM is used, isn't the PCB going to be significantly smaller on all the cards using that tech?
I imagined the R380's PCB being small enough to fit into a mini-ITX case.
Am I wrong?
Should be smaller, if nothing else at least all this GDDR5 area will be removed.
http://i.imgur.com/0tuzDOV.jpg
BTW, how large is single stack of HMB memory? Those chips will be needed to be stacked on the interposer that hosts both memory and GPU.
Jawed
Legend
So, worst case, 28% more bandwidth.I think 4GB would mean four 1024-bit stacks of 1GB, probably running somewhere between 800MHz and 1200MHz, based on what little information is currently available. So 409.6GB/s to 614.4GB/s.
On its own, no, I agree, HBM can't do much, since there's more than enough bandwidth available assuming delta-compression based efficiency gains. Tonga clearly doesn't have enough ROPs and it's well over half the performance of 290X with 55% of the bandwidth.But I don't think HBM alone would bring all that much of a performance boost, since Hawaii never looked all that bandwidth-limited to me.
Remember, GTX980 has 67% of GTX 780Ti's bandwidth, yet is comfortably faster. Notice the "excess of fillrate" in GTX 980, though.
My mind boggles at how 290X's fillrate is squandered. Something's seriously broken.
I can't help wondering if part of the reason why Maxwell ROPs and memory interface are so good is because of the two-part arrangement - the cause of all the GTX 970 grief.
Which, leads me to wonder if AMD needs to overhaul its L2/ROP architecture in a similar fashion. Perhaps that's part of what's in Tonga, why it is so good. Alternatively, maybe AMD couldn't put in enough ROPs because the MC/L2/ROP architecture just doesn't want to go there, without another big architectural change.
Maybe that only happens with HBM? Perhaps that's AMD's plan.
It's worth comparing against 1GHz 7870 (R9 270X). They have about the same power consumption and 285 has less bandwidth and fillrate, but more TFLOPs:As for Tonga's improvements, they've never been properly quantified (as far as I know).
Seems to be around 15-20% faster... Tomb Raider performance indicates 2GB is not enough...
Jawed
Legend
I'm referring to the full "FirePro" performance configuration, 1/2 rate DP.Just to be clear (maybe i missed something): You're talking about full ASIC-design DP, not 1:1 SP/DP rate?
So, worst case, 28% more bandwidth.
On its own, no, I agree, HBM can't do much, since there's more than enough bandwidth available assuming delta-compression based efficiency gains. Tonga clearly doesn't have enough ROPs and it's well over half the performance of 290X with 55% of the bandwidth.
Remember, GTX980 has 67% of GTX 780Ti's bandwidth, yet is comfortably faster. Notice the "excess of fillrate" in GTX 980, though.
My mind boggles at how 290X's fillrate is squandered. Something's seriously broken.
I can't help wondering if part of the reason why Maxwell ROPs and memory interface are so good is because of the two-part arrangement - the cause of all the GTX 970 grief.
Which, leads me to wonder if AMD needs to overhaul its L2/ROP architecture in a similar fashion. Perhaps that's part of what's in Tonga, why it is so good. Alternatively, maybe AMD couldn't put in enough ROPs because the MC/L2/ROP architecture just doesn't want to go there, without another big architectural change.
Maybe that only happens with HBM? Perhaps that's AMD's plan.
It's worth comparing against 1GHz 7870 (R9 270X). They have about the same power consumption and 285 has less bandwidth and fillrate, but more TFLOPs:
Seems to be around 15-20% faster... Tomb Raider performance indicates 2GB is not enough...
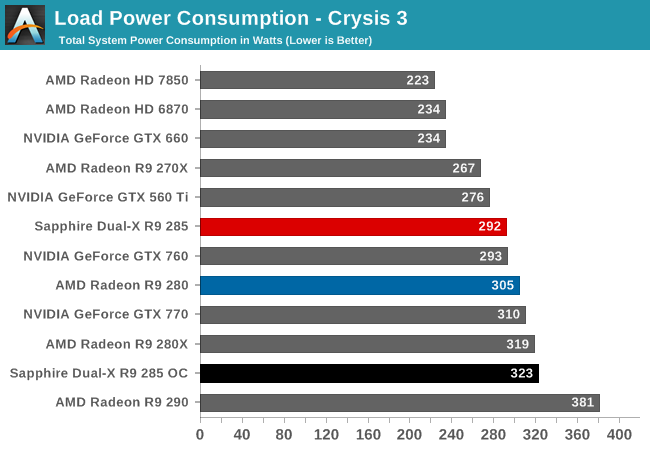
The R9 285 draws way more than the 270X; in fact, it's very close to the 280: http://www.hardware.fr/articles/926-7/consommation-efficacite-energetique.html
What specifically isolates the 290X's ROPs as being a pain point? AMD has leaned very heavily on high-resolution use cases, which would lean heavily on the ROP/MC architecture.My mind boggles at how 290X's fillrate is squandered. Something's seriously broken.
Hawaii's tessellation results for non-culled triangles show practically zero scaling, the performance picture versus the competition frequently reverses at lower resolutions, and they show CPU and front-end limits far more quickly. The fixed function domain created when GCN split the CUs off has a known promised enhancement in Carrizo's generation when they add preemption. Do you recall a change to the FF domain prior to that and after GCN was introduced?
It would be a change if there were an L2/ROP architecture, since they are not linked.Which, leads me to wonder if AMD needs to overhaul its L2/ROP architecture in a similar fashion.
Does anything come to mind prior to Tonga's delta compression as a fixed-function ROP enhancement since RV770?Perhaps that's part of what's in Tonga, why it is so good.
Jawed
Legend
Oh, interesting, I saw much closer numbers, about 9% more for 285. Performance per watt section of that page puts 285 as the worst of those GCNs.The R9 285 draws way more than the 270X; in fact, it's very close to the 280: http://www.hardware.fr/articles/926-7/consommation-efficacite-energetique.html
Ooh, so 285 performance per unit bandwidth is nice, but not per watt. (Well, multiple samples are required for a real comparison, but there's a gulf between 9% and 25%).
Jawed
Legend
True, 290X looks good against 780Ti at 8MP, but 40%+ fillrate versus slightly less bandwidth - something's looking like it needs improving...What specifically isolates the 290X's ROPs as being a pain point? AMD has leaned very heavily on high-resolution use cases, which would lean heavily on the ROP/MC architecture.
I don't know what you're getting at.Hawaii's tessellation results for non-culled triangles show practically zero scaling, the performance picture versus the competition frequently reverses at lower resolutions, and they show CPU and front-end limits far more quickly. The fixed function domain created when GCN split the CUs off has a known promised enhancement in Carrizo's generation when they add preemption. Do you recall a change to the FF domain prior to that and after GCN was introduced?
That's the kind of thing I'm thinking about, a substantial change. Pure speculation: a substantial change might be required, beyond that seen in Tonga, and might be part of the change to an HBM based memory system.It would be a change if there were an L2/ROP architecture, since they are not linked.
I can't think of anything. Can you?Does anything come to mind prior to Tonga's delta compression as a fixed-function ROP enhancement since RV770?
Should be smaller, if nothing else at least all this GDDR5 area will be removed.
http://i.imgur.com/0tuzDOV.jpg
BTW, how large is single stack of HMB memory? Those chips will be needed to be stacked on the interposer that hosts both memory and GPU.

http://www.memcon.com/pdfs/proceedings2014/NET104.pdf
Those seem like confounding factors for performance numbers when evaluating whole games for the purposes of focusing on ROP throughput as a primary item of concern. So much else is creaking along before the ROPs are brought into the equation.I don't know what you're getting at.
The increase in the number of channels that would result from switching to HBM might encourage a change in how the L2 is partitioned.That's the kind of thing I'm thinking about, a substantial change. Pure speculation: a substantial change might be required, beyond that seen in Tonga, and might be part of the change to an HBM based memory system.
There seems to be some flexibility when it comes to ROPs, or has been. Tahiti had a secondary crossbar that linked a ROP to three memory controllers, although this reverted to a 1:1 link in Hawaii.
Nothing major comes to mind, but I didn't want to rely solely on my recollection.I can't think of anything. Can you?
There are areas of limited improvement throughout the pipeline prior to getting to the ROPs. Even the vaunted changes in the programmable portion have not changed much since GCN came out. GCN's global power inefficiency is going to cap improvements. Something around a quarter of the GPU's power budget went to the memory subsystem. HBM could cut the overall consumption per unit of bandwidth approximately in half.
That frees up 12-13% more power budget, if nothing else changes.
Oh, interesting, I saw much closer numbers, about 9% more for 285. Performance per watt section of that page puts 285 as the worst of those GCNs.
Ooh, so 285 performance per unit bandwidth is nice, but not per watt. (Well, multiple samples are required for a real comparison, but there's a gulf between 9% and 25%).
The Tech Report had similar results: http://techreport.com/review/26997/amd-radeon-r9-285-graphics-card-reviewed/8
For some obscure reason, Tonga's performance/watt is really quite bad. Very loose binning, maybe? It's odd because when Tonga was first introduced, AMD hyped it up as their most efficient GPU, but it just might be their least efficient one (discounting pre-GCN stuff).
They are using a OC'ed card in that review. The french one seems to have a non reference card too and only lower the powertune settings and not anything else for their measurement. AMD probably doesn't apply powertune very aggressively on cards like the 285 since they are not as power hungry as cards like the 290. I assume the voltages aren't at reference specs for any of those power consumption tests. My guess is, they can cut the power by 20-30% while keeping 90% of the performance if they want for a reference board with reference clocks by turning powertune down and lowering voltage.The Tech Report had similar results: http://techreport.com/review/26997/amd-radeon-r9-285-graphics-card-reviewed/8
For some obscure reason, Tonga's performance/watt is really quite bad. Very loose binning, maybe? It's odd because when Tonga was first introduced, AMD hyped it up as their most efficient GPU, but it just might be their least efficient one (discounting pre-GCN stuff).
The Tech Report had similar results: http://techreport.com/review/26997/amd-radeon-r9-285-graphics-card-reviewed/8
For some obscure reason, Tonga's performance/watt is really quite bad. Very loose binning, maybe? It's odd because when Tonga was first introduced, AMD hyped it up as their most efficient GPU, but it just might be their least efficient one (discounting pre-GCN stuff).
That card is overclocked and has a higher voltage
That's pretty small!
I have the flu. After a short night of fever-induced, semi-delirious dreams, I woke up at 7 a.m. this morning, and I think I had an epiphany (of sorts):
So here's what I think is going on: Fiji is based on the same IP level as Tonga, just bigger and maybe equipped with HBM. It has been more or less ready for a while, but delayed due to inventory glut, and maybe HBM production costs. When it is finally released, it may be fast but it's not going to break any power-efficiency records.
The real next generation of AMD GPUs will be launched with Carrizo and then Bermuda, and this is where the generational leap will happen, possibly matching Maxwell, or exceeding it thanks to HBM. It might also be built on 14nm.
- According to Damien from Hardware.fr who talked to AMD about it (and other sources corroborate this) the GPU in Carrizo will be based on AMD's most advanced IP when it is released, and it will be more advanced than any discrete GPU available at that time;
- There are persistent rumors that Fiji is the R9 380X and that another GPU, possibly called Bermuda, is the R9 390X;
- Tonga and Fiji are volcanic islands, but as far as I know they are not known for their pirates, and they are most definitely nowhere near the Caribbean;
- We have been hearing rumors about Fiji for a long time now;
- AMD has had pretty horrible inventory issues with Hawaii and Tahiti, leading to apparent delays for Tonga, to the point that the full version of this GPU has yet to be released on desktop;
- Bermuda has a long and rich history of piracy.
So here's what I think is going on: Fiji is based on the same IP level as Tonga, just bigger and maybe equipped with HBM. It has been more or less ready for a while, but delayed due to inventory glut, and maybe HBM production costs. When it is finally released, it may be fast but it's not going to break any power-efficiency records.
The real next generation of AMD GPUs will be launched with Carrizo and then Bermuda, and this is where the generational leap will happen, possibly matching Maxwell, or exceeding it thanks to HBM. It might also be built on 14nm.
Last edited:
Jawed
Legend
There is rationale in this: adding HBM to the Tonga memory architecture in Fiji. Then Pirate Islands is the "true D3D12" hardware.So here's what I think is going on: Fiji is based on the same IP level as Tonga, just bigger and maybe equipped with HBM.
That would mean that they'd miss not only the 'has truckloads of RAM' checkmark, but the DX12 feature set as well? Not a promising prospect...There is rationale in this: adding HBM to the Tonga memory architecture in Fiji. Then Pirate Islands is the "true D3D12" hardware.
Jawed
Legend
D3D12 is 7-9 months away? Launching a true D3D12 card at the same time seems very likely.
We already know that HBM is not going to allow >4GB RAM in the first iteration.
So neither of these things is inherently surprising.
I'm still dubious that HBM is coming this spring, but Alexko's sequence is the first thing I've seen that makes it seem like a possibility to me. I still think the performance is going to be disappointing if it's only 50% faster while using delta-compression + HBM.
We already know that HBM is not going to allow >4GB RAM in the first iteration.
So neither of these things is inherently surprising.
I'm still dubious that HBM is coming this spring, but Alexko's sequence is the first thing I've seen that makes it seem like a possibility to me. I still think the performance is going to be disappointing if it's only 50% faster while using delta-compression + HBM.