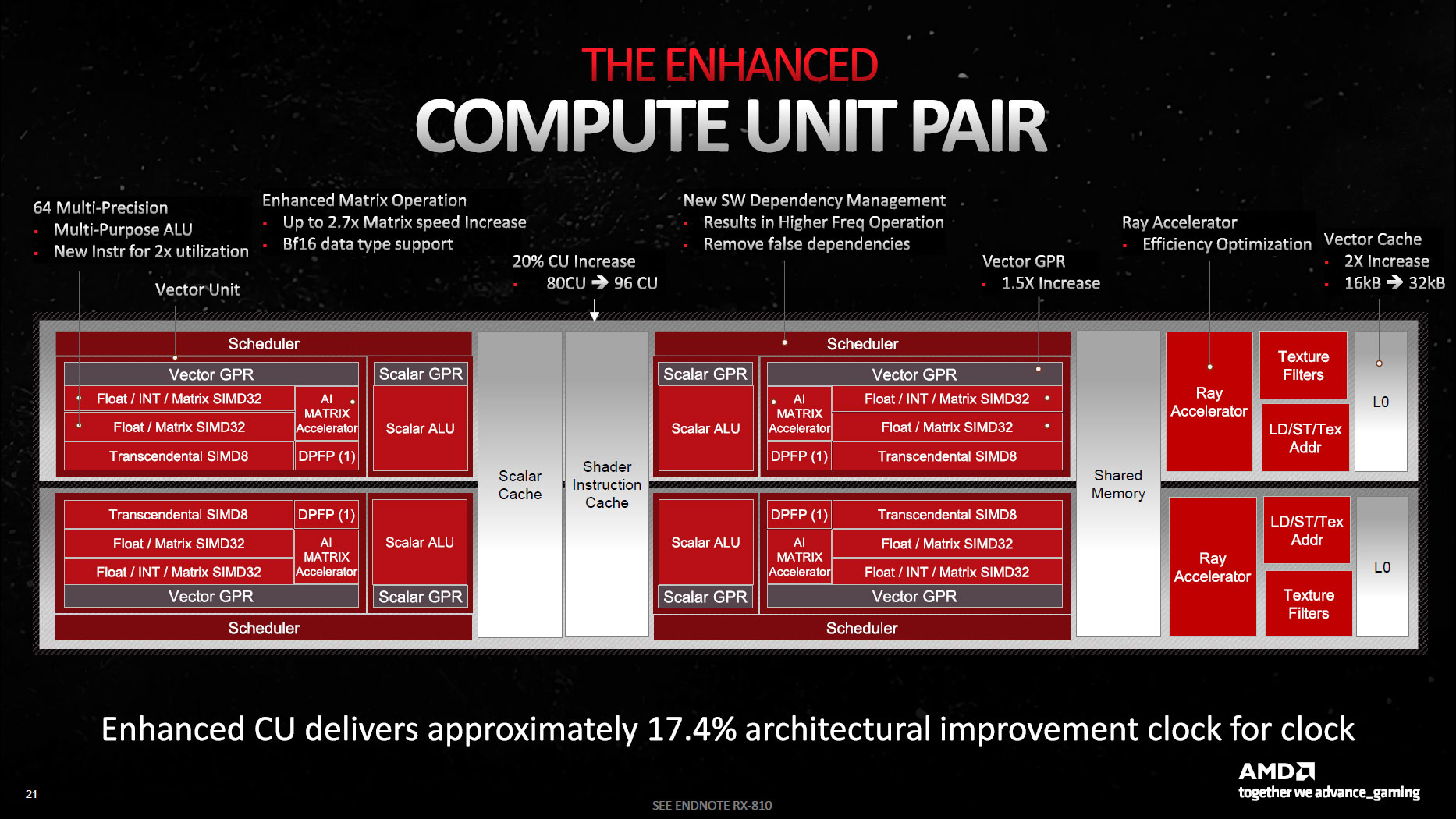
Yes, beside double issue, RDNA3 has doubled register file and LDS size, iirc. That's raising a standard which was set with PS4 and has not changed since that (idk about NV).
That's a big optimization potential - bad occupancy due to register pressure and being tight on LDS should be gone, so we can crank things up.
I can increase the quality of my GI for example, something that just more cores does not really allow. I need more LDS.
There is an
2x increase in L0/L1 cache size (32/256 KB), and 1.5x increase in L2 cache size (6 MB); the bandwidth is also higher due to 1.5x wider links.
L3 cache, i.e. "Infinity Cache", is smaller for higher-end parts (64/80/96 MB) but larger for the low-end Navi 33 (48 MB), and L3 cache bandwidth is 1.5-2x higher (up to 3.5 TB/s).
Navi 31/32 also have 1.5x more VGPRs, 1536 bytes or 384 FP32 registers per 'wave' (thread), but Navi 33 stays at 1024 Bytes or 256 FP32 registers, as shown by the
code commit to the AMDGPU LLVM frontend.
LDS size did not change though, it's the same 128 KB per WGP (or 64 KB per CU) as in RDNA1, but latency has been dramatically improved. Curiously GDS got shrunk to 4 KB.
Then of course there are supercalar dual-issue ALUs capable of processing FP32 and FP32/Int8 register / immediate operands in one clock, using either V_DUAL instructions in VOPD encoding for Wave32 threads, or
Wave64 threads which would transparently dual-issue all VOPD instructions as proved by Chips&Cheese benchmarks below (but bizarrely
Wave64 mode is not supported in HIP/ROCm due to hardware limitations, and there are further limits such as source VGPRs from different banks and cache ports, even/odd register numbers etc.).
In practice Wave32 is the prevalent mode, so dual-issue relies on compilers/optimizers which do a very poor job of automatically scheduling parallel multiple-operand instructions (Intel and HP will testify to the spectacular failure of the much touted
Explicitly Parallel Instruction Computing (EPIC) architecture for the
Itanium (IA64) processors, which relied on exactly the same kind of compiler optimizations in order to extract 6-way parallelism from its VLIW instruction bundles).
Editor’s Note (6/14/2023): We have a new article that reevaluates the cache latency of Navi 31, so please refer to that article for some new latency data. RDNA 3 represents the third iteratio…

chipsandcheese.com
Editor’s Note (6/14/2023): We have a new article that reevaluates the cache latency of Navi 31, so please refer to that article for some new latency data. Late last year, AMD launched high end RDNA…
chipsandcheese.com
AMD cites "17.4% architectural improvement clock-for-clock", so with a 8% frequency increase that should have resulted in a 25% higher performance, but so far such improvements mostly manifest
in compute-limited tasks, like heavy levels of raytracing.
Swimming with the next generation GPUs

www.tomshardware.com
RDNA3 doesn't seem to be that much faster per CU than RDNA2, and it's 60 CUs vs 72 CUs, which seems unbelievable for it to surpass the 6800XT.
RDNA3 has a superscalar "dual-issue" scheduler (or argualby twice the number of ALUs in a CU/WGP), higher VGPR counts and higher clocks - so in theory this should compensate for less CUs, but in practice, only
manifests in raytracing-heavy titles and synthetic benchmarks.
But even if it performs the same or even slightly slower than a 6800XT, I'd take RDNA3 over RDNA2 in this case because of the features under the hood.
It's equally important that the Navi 32 package is only 346 mm2, with the main GCD taking 200 mm2 and the rest taken by four MCDs, which are shared with Navi 31 - that's comparing to monolithic 520 mm2 die in Navi21, which only sold for $650 in the defective bin of 72 CUs, and originally was $999 in the defect-free bin of 80 CUs for the RX 6900 XT.
So RX 7800 XT should be far more proftitable to AMD and partners, and they would be able to offer additional incentives in the tune of at least $25-30 by this Christmas season, and probably even more by next Summer.
")