I thought Tensors were used for denoising in non-realtime applications?Ray testing is done in h/w, the rest is running on SIMDs. RA is a part of WGP too btw so saying that something is "done on WGP" doesn't automatically mean that it's done by a shader.
Denoising is not a part of ray tracing from h/w and API point of view and can be done in many ways. Using ML for this is obviously not very universal as AMD h/w lacks the capability (or it's too slow to be useful).
Install the app
How to install the app on iOS
Follow along with the video below to see how to install our site as a web app on your home screen.
Note: This feature may not be available in some browsers.
You are using an out of date browser. It may not display this or other websites correctly.
You should upgrade or use an alternative browser.
You should upgrade or use an alternative browser.
AMD Execution Thread [2023]
- Thread starter Kaotik
- Start date
- Status
- Not open for further replies.
I also don't know about AI denoising being used for realtime already now. Which is curious because i would naively assume AI should work well for this.I thought Tensors were used for denoising in non-realtime applications?
But it may be a matter of semantics pretty soon.
It's speculated NV works on adding Neural Radiance Cache to Cyberpunk PT, which uses tensor cores.
And although NRC is not a denoising technique, it reduces the amount of noise, like any other approach aiming to optimize the number of required samples.
Thus people will call NRC a denoising technique, as already happened with Restir too.
I'm very curious about NRC. It may make realtime PT much more practical than it is now. And it may be the first true application of AI in realtime rendering beyond image postprocessing.
DegustatoR
Legend
OptiX 5.0 use them for denoising presumably but that's not gaming and it doesn't run on anything but Nv h/w obviously.I thought Tensors were used for denoising in non-realtime applications?
It could if the h/w almost every game targets would be capable of running it.Which is curious because i would naively assume AI should work well for this.
Traversal is in SW on AMD and there are instructions for ray's intersection testing against AABBs and triangles.Ray traversal is in h/w on both (ray accelerator is that h/w on the AMD side), hit evaluation / intersection testing is in s/w on AMD and in h/w on Nv (and Intel)
The cause of slowness is doing the divergent traversal in shaders. This automatically necessitates the use of fat FP32 formats for coordinates, so BVH should be fat and traversing incoherent rays should be slow due to both divergent execution (low occupancy) and high bandwidth requirements. Opting for a narrow and deep BVH is surprising, considering that theoretically, it should be more divergent than a wider and shallower BVH with more boxes per level.
That's irrelevant from NVs perspective. With CP they already have a playground to demonstrate nice things which requires NV HW in practice, so the lack of ML acceleration of other IHVs would only motivate them more to make an AI denoiser. Other IHVs could use a fallback and would appear inferior.It could if the h/w almost every game targets would be capable of running it.
So i'm sure they tried it, but for unknown reasons it did not yet work as well as expected.
I speculate AI is not yet smart enough to turn noise into proper gradients, although this sounds so easy. If you give ma a 1spp PT image and tell me i should denoise it manually in Photoshop, i could not do that either. Although i'm smart as fuck.

So maybe they need to reduce noise further first, using Restir, NRC, etc., and then at some point it will work.
The advantage of a larger branching factor is the corresponding reduction of tree levels.Opting for a narrow and deep BVH is surprising, considering that theoretically, it should be more divergent than a wider and shallower BVH with more boxes per level.
I still have the program i wrote for our discussion years ago, and can print some examples:
...no. I can't find it.
But let's say we have a binary tree of 256 nodes, it will give us 8 levels. (excuse one off errors)
With a branching factor of 8, it will give us only 4 levels. So we will find our intersection with only half of traversal steps.
But ofc. the traversal step is now more work, requiring to test 8 child boxes instead just 2.
To make it a win, we ideally have those 8 childern per node in continuous memory, so we can fetch them quickly without hopping around.
Then we also only need to store the pointer to the first child. We no longer need 8 child pointers per node.
That's in short how a larger branching factor can increase efficiency. I remember experiments of setting the branching factor to 32 or 64, so whole thread group can test all boxes in parallel, plus ideal memory access pattern. But i don't remember the outcome.
However, if we can iterate enough rays over the node data we have currently in registers, we get raytracing at maximum efficiency on GPU.
Sadly raytracing usually generates sparse and chaotic distributions of rays, so forming large packets is rarely possible, and it also conflicts with the other optimization potential of improved sampling strategies, making rays even more sparse.
Thus prioritizing such low level HW optimizations does not give the expected profit, and finding the ideal compromises remains hard.
Iirc, AMDs instruction takes 4 individual child pointers, so they do not enforce such continuous memory order.
DegustatoR
Legend
Nv doesn't make games unless you count Q2RTX and Portal RTX as such. All others who actually make games do not make them for Nv h/w only.That's irrelevant from NVs perspective.
By 'depth', I meant the number of BVH levels. It's easy to understand why a wide structure with less levels is better for SIMD (more compression opportunities, less branching, etc). The question was why AMD chose a seemingly suboptimal narrow one with more levels.The advantage of a larger branching factor is the corresponding reduction of tree levels
Perhaps it's more efficient for AABB tests if they are limited by AABB throughput to begin with. Maybe four boxes fit their cache lines and texture logic better, maybe it's faster to build and update BHV with more levels or perhaps there are other reasons.
It wouldn't be different than offering DLSS libraries.All others who actually make games do not make them for Nv h/w only.
When Turing was introduced, Jensen said AI denoising is going to come, and neither AMD nor Intel had AI acceleration.
Before that there was PhysX acceleration exclusive to NV, stereo 3D vision, hw accelerated bezier patches, and so forth. They love proprietary stuff.
I was surprised too. But i'm even more surprised about Intels choice of 6, which is not even a power of two.The question was why AMD chose a seemingly suboptimal narrow one.
Maybe only 4 boxes fit into the registers of a tiny TMU, and / or it's simd is only 4 wide.
Spatially, 8 makes the most sense, because doubling resolution by adding one level gives 8 smaller boxes. BVH8 is thus trivial and fast to build, if you don't care about quality. So i would have expected that.
DavidGraham
Veteran
Even in the games that NVIDIA makes (like Quake 2 RTX, Minecraft RTX, Portal RTX), denoising is done in shaders. The whole RTX Remix platform relies on shader denoising as well. My guess is that NVIDIA discovered that DLSS and Denoising were too much to handle together on the Tensor cores, so they separated both workloads to avoid resources contention, especially now that DLSS3 is a reality and is even more resource hungry than DLSS2.Nv doesn't make games unless you count Q2RTX and Portal RTX as such. All others who actually make games do not make them for Nv h/w only.
DmitryKo
Veteran
Ray testing is done in h/w, the rest is running on SIMDs. RA is a part of WGP too btw .
This is correct. BTW we already discussed the AMD raytracing patent where TMUs can be configured for ray intersection testing, but flow control is implemented by unified shaders, and then the specific RDNA2/3 implementation of this patent.
To recap, RDNA2/3 rely on shader ALUs to execute the traversal, and the TMUs contain the fixed function logic for fast intersection testing of rays against proprietary BVH structures (the titular 'Ray accelerator').
The reason AMD uses TMUs is because they have massive memory bandwidth for texel interpolation and trilinear/anisotropic filtering between the MIP levels, so there are wide buses to texture caches to prefetch the required patterns of texels as fast as possible. TMUs also have direct connections to VGPRs and constant registers to provide the sampled color to the pixel shade.
So AMD added a special 'filtering' mode to the TMUs, which is instead a ray-triangle intersection solver. It treats TLAS BVH nodes as a FP32 'texture' with 'texels' arranged in a hardware-specific pattern. Hence the reference to 'image', a prefix reserved for vector memory image instructions, in the mnemonic for IMAGE_BVH_INTERSECT_RAY.
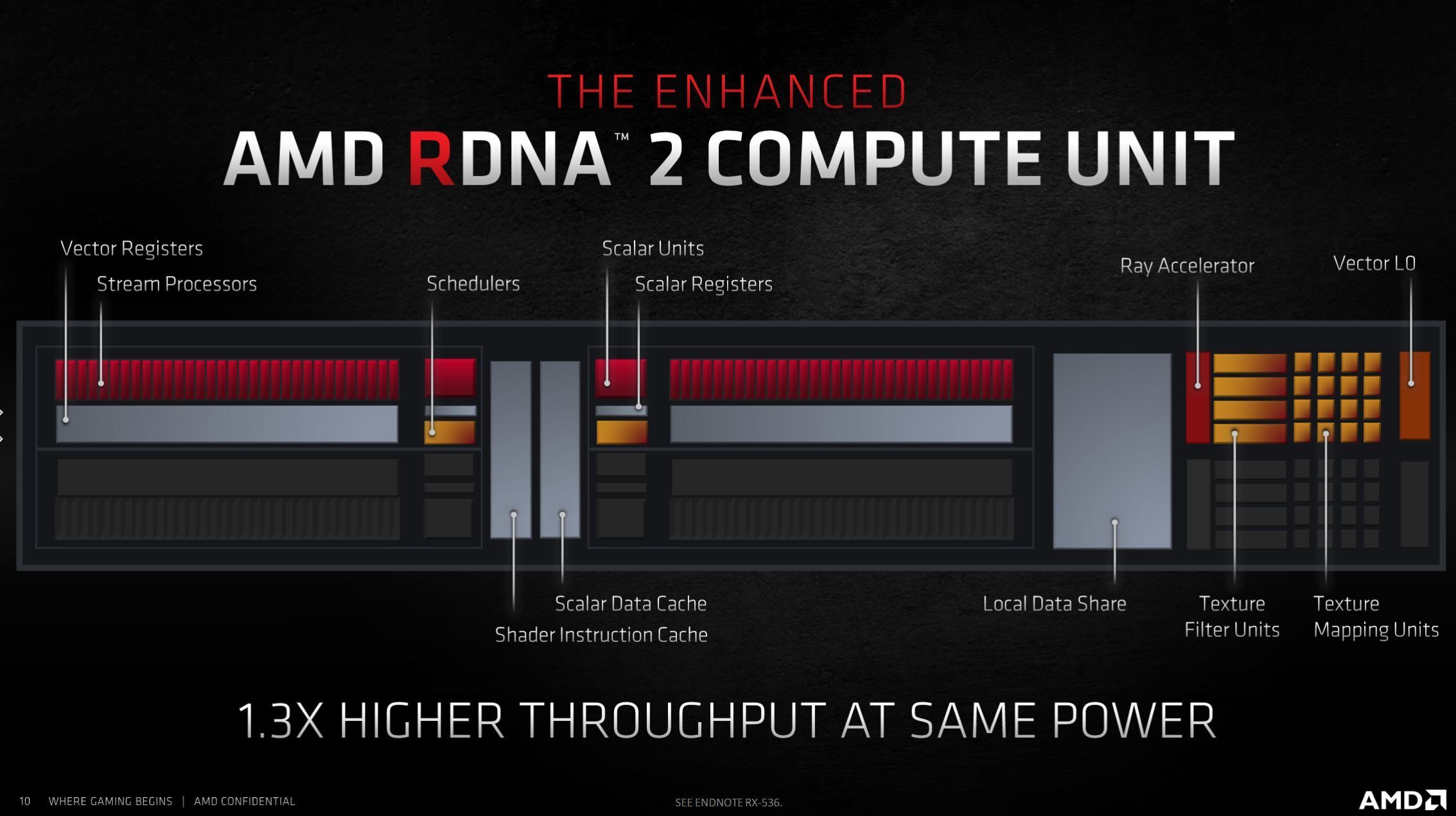

RDNA 2 deep-dive: What’s inside AMD’s Radeon RX 6000 graphics cards
AMD's new RDNA 2 architecture brings ray tracing, an innovative Infinity Cache, and more to Radeon RX 6000-series GPUs. Here's everything you need to know.
There are no other ALUs within the compute unit / WGP in RDNA2/3 besides the unified shader ALUs, that can be used for flow control. The block diagram has not really changed since TeraScale 2 (Evergreen), it's on Figure 1 in the 'Instruction Set Architecture' documents.so saying that something is "done on WGP" doesn't automatically mean that it's done by a shader
The AMD raytracing patent does assume that implementations may actually include specialized ALUs for raytracing only, so that could be introduced in RDNA4/5.
I thought Tensors were used for denoising in non-realtime applications?
Even in the games that NVIDIA makes (like Quake 2 RTX, Minecraft RTX, Portal RTX), denoising is done in shaders. The whole RTX Remix platform relies on shader denoising as well. My guess is that NVIDIA discovered that DLSS and Denoising were too much to handle together on the Tensor cores
I do recall that back in 2018, AI denoising was used in the realtime Unreal engine demos which were run on Volta (Titan V), but it seems by 2021 they switched to the shader-based NRD library.

NVIDIA RTX Kit
Render game assets with AI, create game characters with photo-realistic visuals, and more.
 developer.nvidia.com
developer.nvidia.com
Last edited:
DmitryKo
Veteran
Acceleration structures usually use axis aligned bounding boxes, so you need only a min and max value per dimension to define its range, giving 6 floats for a box in 3D.
Bounding boxes are certainly not aligned to be parallel to the screen space - that would introduce too much empty space which reduces efficiency.
But axis aligning can be used in model space for performance optimization, to ensure that bounding boxes do not contain too much empty space.
It basically means that elongated objects should be aligned across their longest axis in model space, and some of the most complex objects may need to be split into multiple objects with simpler geometries.
Even if bounding boxes were aligned to the screen space, it makes little sense to remove sides - there are reflective/refractive surfaces which generate additional rays when hit, to emulate light scattering and realistic shadows,
More details here:
Improving raytracing performance with the Radeon™ Raytracing Analyzer (RRA)
Optimizing the raytracing pipeline can be difficult. Discover how to spot and diagnose common RT pitfalls with RRA, and how to fix them!
 gpuopen.com
gpuopen.com
i have little hope DXR will add such BVH API while IHVs may still want to modify their data structures for newer architectures.
Come back in 2029,when 300 TFLOPS graphic cards are in the mid-range and Direct3D / DirectX Raytracing / HLSL202x is being replaced with a single-source programming model similar to SYCL and CUDA/HIP, based on standard C++26.
It's easy to understand why a wide structure with less levels is better for SIMD (more compression opportunities, less branching, etc). The question was why AMD chose a seemingly suboptimal narrow one with more levels.
Perhaps it's more efficient for AABB tests if they are limited by AABB throughput to begin with. Maybe four boxes fit their cache lines and texture logic better, maybe it's faster to build and update BHV with more levels or perhaps there are other reasons.
Maybe only 4 boxes fit into the registers of a tiny TMU, and / or it's simd is only 4 wide.
I think it's because all four TMUs in a CU have to be combined to act as a 'Ray Accelerator'...
Last edited:
Why do you mention screenspace? I thought you did an estimate on BVH memory / bandwidth costs using 8 points per box, but only two are necessary. Maybe i got the entire context wrong.Bounding boxes are certainly not aligned to be parallel to the screen space - that would introduce too much empty space which reduces efficiency.
Haha, yes. I guess i have to wait so long... : /Come back in 2029,when 300 TFLOPS graphic cards are in the mid-range and Direct3D / DirectX Raytracing / HLSL202x is being replaced with a single-source programming model similar to SYCL and CUDA/HIP, based on standard C++26.
DmitryKo
Veteran
Why do you mention screenspace? I thought you did an estimate on BVH memory / bandwidth costs using 8 points per box, but only two are necessary. Maybe i got the entire context wrong.
I thought you're proposing to drop back-facing sides of all bounding boxes which are 'invisible' from the point of the screen plane (where you shoot your rays from)?
[edit] Never mind, finally got it
You only need 2 points/vertices to define a world space axis-aligned bounding box (AABB).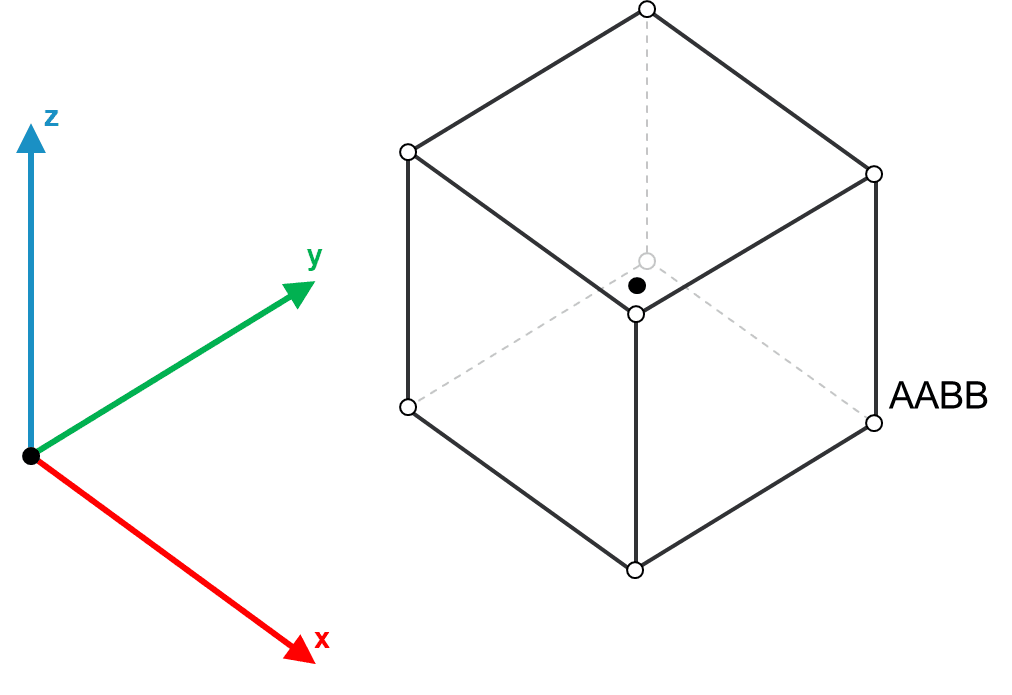
What is an AABB? - Radiance Fields
When you're playing a video game or watching a movie with 3D graphics, you're seeing objects that are made up of points in a 3D space.
 neuralradiancefields.io
neuralradiancefields.io
In 3D space, child bounding boxes might share some vertices with the parent bounding box, but there's no way children could share 6 vertices with parents - it's only possible to have 1, 2, or 4 shared vertices (and even then, straight angles were a thing for first-get 2.5D first-person shooters like Wolfenstein 3D, Doom, Duke Nukem 3D, and Star Wars: Dark Forces).
Here are some visual examples. First, consider the blue parent bounding box, which has purple and orange child bounding boxes each sharing a single vertex with the parent (so 7 vertices are unique for each child).

If you stretch up each child box along a single axis until you entirely fill up one side of the parent box, there would be 2 verices shared with the parent (and 6 unique vertices).
And if you stretch the children along two axes to fill up the entire side of the parent box, they will now share 4 vertices (yet 4 vertices would still remain unique).
Obviously the next step would be to fill the entire parent box until all 8 coordinates are shared, which doesn't make sense.

But even one shared vertex would be rare - most child boxes would only touch the sides of the parent box:
So there's too much hassle to account for cases of shared vertices, which would require additional vertex attributes or vertex masks to indicate shared state, incurring addtitional processing overhead for very mild memory/bandwidth savings.
Last edited:
DmitryKo
Veteran
Suggestions for deeper architectural improvements include shader instructions for hardware BVH tree building and traversal (i.e. NVidia and Intel approach) with a dedicated stack wemory for ray/BVH coordinates; AMD has a patent US20230206543 on a hardware traversal engine describing these techniques.
we already discussed the AMD raytracing patent where TMUs can be configured for ray intersection testing, but flow control is implemented by unified shaders, and then the specific RDNA2/3 implementation of this patent.
AMD recently (June 2023) got assigned a new raytracing patent US20230206543 Graphics Processing Unit Traversal Engine. It further expands on their 2019 patent above, US2019019776 Texture Processor Based Ray Tracing Acceleration Method and System which describes TMU-based ray-triangle intersection solvers.
The new patent describes a hardware BVH traversal engine that introduces dedicated fixed-function ray-tracing units (RTU) for ray/BVH traversal tasks (i.e. NVidia and Intel approach), as well as dedicated stack memory (register file) and/or and cache memory to store processed ray/BVH coordinates in TLAS and BLAS spaces, enabling recursion.
GRAPHICS PROCESSING UNIT TRAVERSAL ENGINE - ADVANCED MICRO DEVICES, INC.
<div p-id="p-0001">A processing unit employs a hardware traversal engine to traverse an acceleration structure such as a ray tracing structure. The hardware traversal engine includes one or more memor
 www.freepatentsonline.com
www.freepatentsonline.com
Some excerpts:.
Abstract
A processing unit employs a hardware traversal engine to traverse an acceleration structure such as a ray tracing structure. The hardware traversal engine includes one or more memory modules to store state information and other data used for the structure traversal, and control logic to execute a traversal process based on the stored data and based on received information indicating a source node of the acceleration structure to be used for the traversal process. By employing a hardware traversal engine, the processing unit is able to execute the traversal process more quickly and efficiently, conserving processing resources and improving overall processing efficiency.
Description
... Ray tracing operations employ a tree structure, such as a bounding volume hierarchy (BVH) tree, to represent a set of geometric objects within a scene to be rendered. The geometric objects (e.g., triangles or other primitives) are enclosed in bounding boxes or other bounding volumes that form leaf nodes of the tree structure, and then these nodes are grouped into small sets, with each set enclosed in their own bounding volumes that are represented by a parent node on the tree structure, and these small sets then are bound into larger sets that are likewise enclosed in their own bounding volumes that represent a higher parent node on the tree structure, and so forth, until there is a single bounding volume representing the top node of the tree structure and which encompasses all lower-level bounding volumes.
A conventional GPU employs a software shader, executing at a shader processor to control ray tracing operations. To implement BVH traversal (that is, traversal of a BVH tree) for ray tracing, the GPU employs a loop wherein the shader provides a ray address and a BVH node address to texture addressing hardware of the GPU, the texture address hardware provides the corresponding ray and BVH node to an intersection engine to identify any intersection between the ray and the BVH node, and the intersection result is returned to the shader to determine the next node of the BVH tree to be processed. Thus, the shader initiates each iteration of the tree traversal process, thereby adding overhead for each iteration.
In contrast to the conventional approach... a hardware traversal engine that initiates at least some of iterations of the tree traversal process, thereby reducing the overall overhead associated with tree traversal... the control flow of the tree traversal process is offloaded from the shader to the traversal engine hardware, improving overall processing efficiency.
The traversal engine includes a plurality of memory modules to store data used for the traversal process. The traversal engine is thus able to execute operations quickly, and further reduces the impact of the traversal process on the memory access traffic at the processing unit, such as by reducing the number of accesses to a cache or local data store of the processing unit.
Examples of these memory modules include an initial data store configured to store data extracted from an initial ray tracing call, a top level acceleration structure (TLAS) data store configured to store data for the ray in TLAS coordinate space, a bottom level acceleration structure (BLAS) data store configured to store data for the ray in BLAS coordinate space, a traversal state memory configured to store temporary data associated with the current iteration of the traversal process, a closest hit memory configured to store the closest hit value for the ray in the tree structure, and a traversal stack configured to store a stack of node addresses for the current ray for the ray to intersect next.
Sony was assigned a similar patent in 2022, WO2022040481 System and Method for Accelerated Ray Tracing with Asynchronous Operation and Ray Transformation, which describes fixed-function raytracing units for BVH traversal, complete with traversal stack memory.
WO2022040481A1 - System and method for accelerated ray tracing with asynchronous operation and ray transformation - Google Patents
A graphics processing unit (GPU) (300, 400, 500) includes one or more processor cores (304, 406, 502) adapted to execute a software-implemented shader program, and one or more hardware-implemented ray tracing units (RTU) (408, 410, 504) adapted to traverse an acceleration structure to calculate...
patents.google.com

Sony patents method for “significant improvement of ray tracing speed”
Special hardware units handle ray traversal, freeing up the GPU shaders.
RedGamingTech's take:
Last edited:
We finally have a near perfect RDNA 2 vs RDNA 3 comparison courtesy of Computerbase.
RDNA 3 is 5% faster at 4k in rasterization and 7% faster with moderate RT in use. With max RT enabled it jumps to 12%.
RDNA 3 is 5% faster at 4k in rasterization and 7% faster with moderate RT in use. With max RT enabled it jumps to 12%.
D
Deleted member 2197
Guest
AMD Acquires An AI Software Company - Phoronix
 www.phoronix.com
www.phoronix.com
AMD acquired Mipsology, an AI software start-up based out of France, to enhance their AI inference software capabilities. Mipsology's Zebra AI software can be used with FPGAs like those from AMD-Xilinx. Mipsology's Zebra AI software on FPGAs is advertised as being able to compete with GPU inference performance.
I wasn't familiar with Mipsology myself but then again their software doesn't appear to be open-source.
There they self-describe their efforts as:
"Zebra AI accelerator computes image-based neural network inference without making any changes to your existing neural network.
Zebra is easy to use and works on main frameworks: PyTorch, TensorFlow and ONNX and is easily deployed using best in class CPU and FPGA hardware.
Zebra is so easy to deploy, our users call Zebra ‘plug & play.’"
I think you are overthinking things. Axis aligned bounding boxes are defined in object space or world space, and consists of a position for the box and the dimensions along each axis. Essentially two points per box.I thought you're proposing to drop back-facing sides of all bounding boxes which are 'invisible' from the point of the screen plane (where you shoot your rays from)?
If you meant compressing the size of bounding box structures by re-using parent node coordinates for child nodes, you're probably confusing BVH tree with binary space partitioning tree.
In 3D space, child bounding boxes might share some vertices with the parent bounding box, but there's no way children could share 6 vertices with parents - it's only possible to have 1, 2, or 4 shared vertices (and even then, straight angles were a thing for first-get 2.5D first-person shooters like Wolfenstein 3D, Doom, Duke Nukem 3D, and Star Wars: Dark Forces).
Here are some visual examples. First, consider the blue parent bounding box, which has purple and orange child bounding boxes each sharing a single vertex with the parent (so 7 vertices are unique for each child).
View attachment 9447
If you stretch up each child box along a single axis until you entirely fill up one side of the parent box, there would be 2 verices shared with the parent (and 6 unique vertices).
And if you stretch the children along two axes to fill up the entire side of the parent box, they will now share 4 vertices (yet 4 vertices would still remain unique).
Obviously the next step would be to fill the entire parent box until all 8 coordinates are shared, which doesn't make sense.
View attachment 9450
But even one shared vertex would be rare - most child boxes would only touch the sides of the parent box:
So there's too much hassle to account for cases of shared vertices, which would require additional vertex attributes or vertex masks to indicate shared state, incurring addtitional processing overhead for very mild memory/bandwidth savings.

AMD announces Radeon RX 7800 XT 16GB and RX 7700 XT 12GB graphics cards - VideoCardz.com
AMD Radeon RX 7800 XT & RX 7700 XT revealed, designed for 1440p gaming At Gamescom AMD announces its mid-range RX 7000 GPUs. AMD has unveiled two highly anticipated graphics cards: the RX 7800 XT and RX 7700 XT, filling a crucial gap in AMD’s RDNA3 desktop lineup. Although we had some...
 videocardz.com
videocardz.com
Officially announced now.
Pretty big gap down to the 7600 from the 7700XT, so plenty of room for a 7700 non-X at some point. I'd long expected that N32 would be a three SKU part given how low spec N33 is.
Still no pricing, though I have very little expectations AMD is looking to make these any kind of good deal with the naming they're using. A 7800XT has less CU's than the 6800XT ffs. And it's not like RDNA3 is way more powerful per-CU than RDNA2.
More options is nice, but it's probably gonna be another waiting game with these til they come down in price and then maybe eventually these will be worthwhile to buy.
EDIT: Given the comparisons AMD are going with, I'm betting 7800XT will be $550, and 7700XT will be $450.
- Status
- Not open for further replies.
Similar threads
- Replies
- 18
- Views
- 8K
- Replies
- 97
- Views
- 18K
- Replies
- 33
- Views
- 6K
- Replies
- 21
- Views
- 5K