3070Ti: 174 Int8 TOPs (1.77*48*2048)
ps5pro: 68 Int8 TOPs with RDNA3 wmma rates (2.2*60*512)
If DLSS takes ~1 ms on a 3070Ti, then a DLSS sized network would take 2.6 ms* on the CUs of the ps5pro, which seems like a good trade off when the difference between 1080p and 4k frametime is on the order of 10 ms. If DLSS takes 2 ms on the 3070Ti, it would take 5.2 ms on the ps5pro CUs, which now seems like a bad trade off.
*Is this naive extrapolation where lower level performance differences between dedicated tensor cores and CUs could manifest?
In general it seems like modern general compute hardware is closer to being a good tradeoff then the "conventional wisdom" believes, which I read as some obvious show stopper. That is, the conversation is entirely about the rate being much faster, without consideration for the absolute time taken nor how that time relates to the upscaling "window". But, for the point of this thread, I'm suggesting that the cost of the upscaler is probably not what is taking away other possible improvements (even in my worst case construction) because that seemed to be a theme of some of the earlier comments, which is why I went down this rabbit hole in the first place.
Not quite how this works. You're assuming bandwidth is unlimited in these scenarios and it's a pure compute play when you're doing this calculations.
Firstly, the ampere series of GPUs are incorrectly rated on tensor ops. That's not your fault. But the 3070TI in this case is 174 tensor TOPS with sparsity. It's actually only 87 Tensor TOPs int-8
So perhaps this is largely missed, I think it's a critical marketing issue I suppose.
Tensor Cores, and large matrix accumulator silicon, are actually measured very differently than what you're measuring on the CUs, or SMs. Those are 8-bit int Tera Operations. If it was 32bit it would be called a TFLOP, which is tera floating point operations.
So the reason PS5 has 300 TOPs, is because that's actually just dual issue, 32bits cut down to 8bit, with sparsity for 2x.
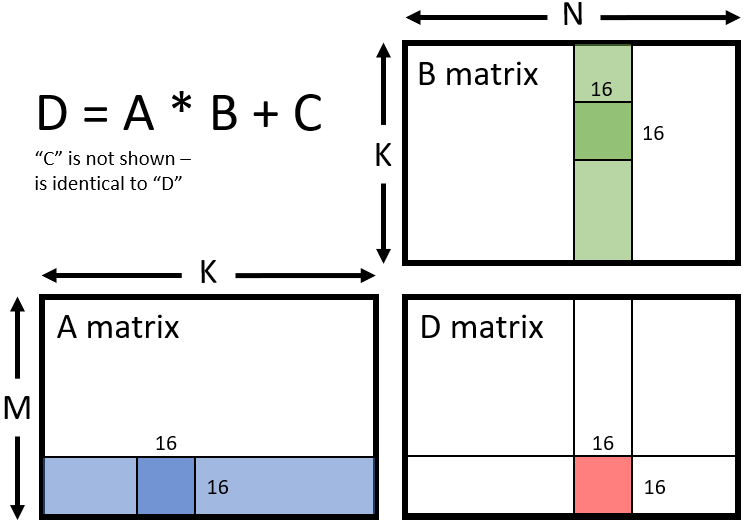
Tensor Cores, and equivalent silicon, are rated in TOPS, but they don't stand for Tera OPs. They are Tensor Tera Ops. And that little bit, "tensor" being removed from the front, is a world of difference. What a tensor core is able to complete in a single cycle, will take _many_ cycles of a CU to complete. They are very different silicon right. The CU is a general purpose high performance SIMD/SIMT unit. That's the architecture for it. They are designed to hold precision.
The Tensor core, is a large scale, massive matrix multiplier with accumulate that is very happy to toss precision in favor of completing as much work as possible in a single cycle. It does it so fast, it's always bandwidth limited, its probably idle most of the time. There's just not enough data for it to crunch. The problem with tensor cores is that it's so specialized, it only runs 1 type of AI algorithm, and there are many, and it's designed to run the Neural Network family of algorithms. And they cannot be used for anything else, anything else requires the CUs.
It's worth reading about how tensor cores work, I've listed the blog post above. But incase you don't want to:
Tensor Core
- Global memory access (up to 80GB): ~380 cycles
- L2 cache: ~200 cycles
- L1 cache or Shared memory access (up to 128 kb per Streaming Multiprocessor): ~34 cycles
- Fused multiplication and addition, a*b+c (FFMA): 4 cycles
- Tensor Core matrix multiply: 1 cycle
- shared memory access 1*34 cycles
General SM
To perform the same matrix multiply it is 32 cycles and 8*34 cycles of shared memory accesses.
From a compute perspective, the tensor cores are 32x faster.
The problem is, on both sides there is memory and latency to get memory into caches to serve both. And that is a flat rate whether it goes into the compute path or the tensor path as the tensor cores are located inside the SM.
so the only reason we don't see more performance out of the tensor cores, is quite simply, because they cannot be fed any faster.
The larger GPUs with more tensor cores, only go faster at it because they are also paired into more SMs, and more SMs are paired with more bandwidth. There's nothing they can really do about it either, memory takes like 200 cycles to arrive, tensor cores are sitting around doing nothing.
quite simply, you're looking at bandwidth limitations here which is why tensor cores aren't just running away with it, memory latency keeps it idle, so you're looking closer to a 2x improvement overall in the worst case scenario. With latency hiding you are looking close of upward to 9x faster.
But the PS5 shares everything, and it's extremely bandwidth limited as it sharing bandwidth with the CPU, and losing some of it because of that, losing bandwidth to rendering, and of course it now has to do AI upscaling.
So it's not going to be the same as just counting cycle operations and saying it's 1/2 the speed to 10x slower than tensor cores. Tensor cores can take memory access in 34 cycles, and complete it's job 1 cycle later all the while the SMs are doing their work in parallel.
It's very different