The idea comes from Microsoft R&D and everyone need to read this for understand how they did. This is clever.
http://hhoppe.com/proj/gim/
Abstract: Surface geometry is often modeled with irregular triangle meshes. The process of remeshing refers to approximating such geometry using a mesh with (semi)-regular connectivity, which has advantages for many graphics applications. However, current techniques for remeshing arbitrary surfaces create only semi-regular meshes. The original mesh is typically decomposed into a set of disk-like charts, onto which the geometry is parametrized and sampled. In this paper, we propose to remesh an arbitrary surface onto a completely regular structure we call a geometry image. It captures geometry as a simple 2D array of quantized points. Surface signals like normals and colors are stored in similar 2D arrays using the same implicit surface parametrization — texture coordinates are absent. To create a geometry image, we cut an arbitrary mesh along a network of edge paths, and parametrize the resulting single chart onto a square. Geometry images can be encoded using traditional image compression algorithms, such as wavelet-based coders.
Hindsights: Geometry images have the potential to simplify the rendering pipeline, since they eliminate the "gather" operations associated with vertex indices and texture coordinates. Although the paper emphasizes the exciting possibilities of resampling mesh geometry into an image, the same parametrization scheme can also be used to construct single-chart parametrizations over irregular meshes, for seam-free texture mapping. The irregular "cruft" present in several of the parametrizations is addressed by the inverse-stretch regularization term described in the 2003 Spherical Parametrization paper.
They solve the tiny triangle problem @Dictator , the idea was there but not the hardware
http://graphicrants.blogspot.com/2009/01/virtual-geometry-images.html
y plan on how to get this running really fast was to use instancing. With virtual textures every page is the same size. This simplifies many things. The way detail is controlled is similar to a quad tree. The same size pages just cover less of the surface and there are more of them. If we mirror this with geometry images every time we wish to use this patch of geometry it will be a fixed size grid of quads. This works perfectly with instancing if the actual position data is fetched from a texture like geometry images imply. The geometry you are instancing then is grid of quads with the vertex data being only texture coordinates from 0 to 1. The per instance data is passed in with a stream and the appropriate frequency divider. This passes data such as patch world space position, patch texture position and scale, edge tessellation amount, etc.
If patch tessellation is tied to the texture resolution this provides the benefit that no page table needs to be maintained for the textures. This does mean that there may be a high amount of tessellation in a flat area merely because texture resolution was required. Textures and geometry can be at a different resolution but still be tied such as the texture is 2x the size as the geometry image. This doesn't affect the system really.
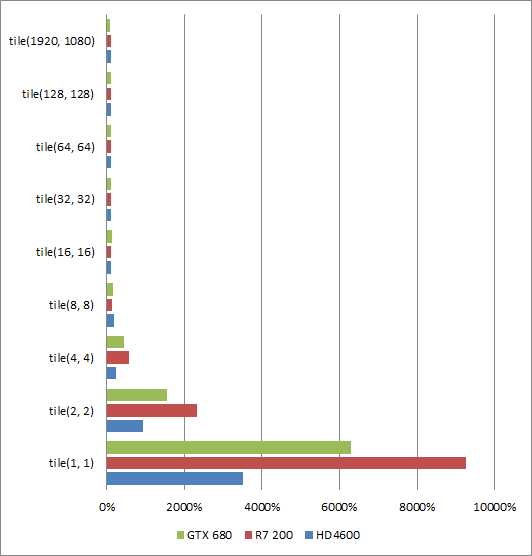
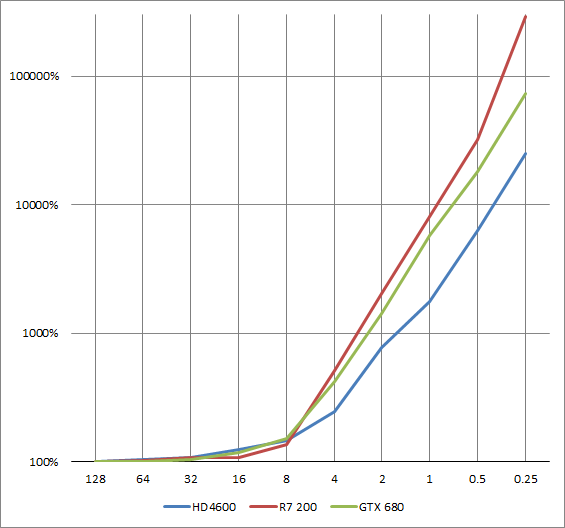
If the performance is there to have the two at the same resolution a new trick becomes available. Vertex density will match pixel density so all pixel work can be pushed to the vertex shader. This gets around the quad problem with tiny triangles. If you aren't familiar with this, all pixel processing on modern GPU's gets grouped into 2x2 quads. Unused pixels in the quad get processed anyways and thrown out. This means if you have many pixel size triangles your pixel performance will approach 1/4 the speed. If the processing is done in the vertex shader instead this problem goes away. At this point the pipeline is looking similar to Reyes.