Install the app
How to install the app on iOS
Follow along with the video below to see how to install our site as a web app on your home screen.
Note: This feature may not be available in some browsers.
You are using an out of date browser. It may not display this or other websites correctly.
You should upgrade or use an alternative browser.
You should upgrade or use an alternative browser.
Xbox One (Durango) Technical hardware investigation
- Thread starter Love_In_Rio
- Start date
- Status
- Not open for further replies.
SenjutsuSage
Newcomer
We seem to have a new tag, 17.3% overclock
938.4 mhz Durango GPU clock confirmed
Would be 1.44 teraflops, sounds good.
Please, do tell. Where did you hear this? Oh, wait, just a joke, right?
")
LOl, I have this tongue in cheek theory that in the know mods plant true information in the thread tags, amongst the nonsense.
17.3% overclock is a new tag I believe, it didn't used to be there. 15% OC was, but not 17.3.
Dont take it too serious.
Haha i didn't even notice the tags, 17.3% GPU overclock & 15% CPU overclock confirmed!!!!
Even if the GPU was overclocked 17.3% that would still be disappointing, the rumoured GPU just doesn't cut it.
SenjutsuSage
Newcomer
Haha i didn't even notice the tags, 17.3% GPU overclock & 15% CPU overclock confirmed!!!!
Even if the GPU was overclocked 17.3% that would still be disappointing, the rumoured GPU just doesn't cut it.
I don't know, I like the design, a lot. A part of me is kinda actually hoping that the GPU isn't notably stronger than what people think, just to see the reaction when the exact GPU that we know about now, proves to be a whole lot more capable than people were ever giving it credit for.
Edit:: Thanks for telling me about the tags. Now you're going to have me tag watching in every thread of significance. I'm having a tinfoil hat built as we speak.
I don't know, I like the design, a lot
Me too, it's very fun to discuss. And seems capable and low cost. A lot of thought went into it. I've always admired MS engineers.
It seems like the perfect design for Nintendo really, had they not lost the plot.
Are you sure that's up to Crytek and not EA?
Crytek is an independent company and a middleware provider. I'm not expecting a Crysis 3 up port or anything, but even if one was on the way that shouldn't keep Crytek from promoting CryEngine on PS4 in general.
Please use the established "double-confirmed" expression if you intend your comment to be tongue-in-cheek in nature, that cuts down on misinterpretations and thus, unnecessary noise...Haha i didn't even notice the tags, 17.3% GPU overclock & 15% CPU overclock confirmed!!!!
I don't know, I like the design, a lot. A part of me is kinda actually hoping that the GPU isn't notably stronger than what people think, just to see the reaction when the exact GPU that we know about now, proves to be a whole lot more capable than people were ever giving it credit for.
Edit:: Thanks for telling me about the tags. Now you're going to have me tag watching in every thread of significance. I'm having a tinfoil hat built as we speak.
Durango having a tile base design has further implication beyond the console itself. I don't think Durango's was designed with just a console in mind. It's a power and bandwidth friendly design which means it's potentially well suited for smaller devices. If MS's phones, tabs and setup all use derivatives of Durango designs, it will allow 720 titles to be easily ported to those devices.
Furthermore, Durango as a robust tile based design with its DMEs and fast and wide I/o bus with its compression logic creates what looks to be a very hardy streaming device. Before Durango is finished rendering the last tile of a frame, the vast majority of that frame can already be in transit to a peripheral device. Compressing tiles and sending them off chips means Durango can be faster and more i/o friendly than more conventional PC hardware when servicing other devices.
Durango doesnt look like it was designed to be cheaper. It's console specific design look like its meant to efficiently service the broader feature set that's next gen consoles will offer as multimedia devices.
But this is how I see Durango, which doesn't mean much.
Last edited by a moderator:
SenjutsuSage
Newcomer
Durango having a tile base design has further implication beyond the console itself. I don't think Durango's was designed with just a console in mind. It's a power and bandwidth friendly design which means it's potentially well suited for smaller devices. If MS's phones, tabs and setup all use derivatives of Durango designs, it will allow 720 titles to be easily ported to those devices.
Furthermore, Durango as a robust tile based design with its DMEs and fast and wide I/o bus with its compression logic creates what looks to be a very hardy streaming device. Before Durango is finished rendering the last tile of a frame, the vast majority of that frame can already be in transit to a peripheral device. Compressing tiles and sending them off chips means Durango can be faster and more i/o friendly than more conventional PC hardware when servicing other devices.
Durango doesnt look like it was designed to be cheaper. It's console specific design look like its meant to efficiently service the broader feature set that's next gen consoles will offer as multimedia devices.
But this is how I see Durango, which doesn't mean much.
Very impressive analysis nonetheless. I think you could be onto something. Hell, I think you're more than onto something, Microsoft might ask you to sign an NDA so they can punish you for breaking it in retrospect.
(((interference)))
Veteran
I've asked about it explicitly and it's not designed for tile based deferred rendering, though I'm sure you could implement a TBDR on it.
(((interference)))
Veteran
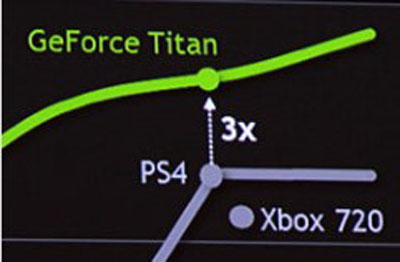
Yes...what we all already know?
The full slide offers a bit more perspective, as the zoomed one makes the PS4 look 2X as powerful
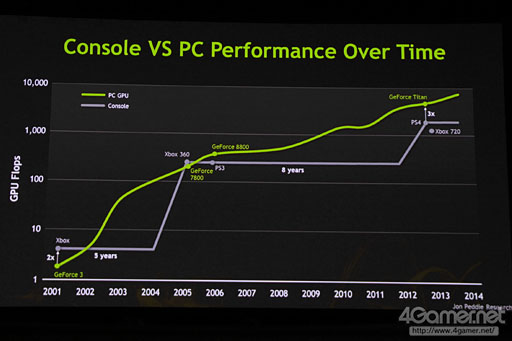
It does look like 720 is slightly above the 1000 flops line, in line with 1.2 TF's rumored.
Only question is if Nvidia "knows" or is going on the same rumors everybody else is.
A quick google says Nvidia rates Titan at 4.5 teraflops. interestingly this is 2.5X the 1.8 TF PS4, not 3X *shrug*.
1.84X3=5.52
It's interesting they correctly give credit for Xenos perhaps being slightly more powerful than the best PC GPU's at it's release. At least it was in the same small ballpark. A notable accomplishment we aren't likely to see again.
Xbox was 2X geforce 3? Not sure on that one.
I've asked about it explicitly and it's not designed for tile based deferred rendering, though I'm sure you could implement a TBDR on it.
And what is your source for this? MS's own patents are pretty explicitly suggesting otherwise and they explain a lot about the stuff we do know by the sound of it. Maybe the 'deferred' part is what's off? The patent below goes into detail about the procedure of rendering tile-based content and where this method's gains come from and it seems to mesh well with what ppl like Arthur on GAF had said months back. Additionally, the patent seems to directly allude to leaning on the eSRAM and display planes both for this methodology.
Here is the patent link for a new page...this link is a bit better actually since it has the diagrams:
http://www.faqs.org/patents/app/20130063473
I read through it and it sounds like there could be pretty considerable bandwidth and processing advantages rendering things on a tile depth basis as opposed to simply using tiles to construct layers, and then processing those layers in the GPU. This (new?) method could possibly explain why the eSRAM is targeted at such low latency and the murmurs from insiders of an exceptionally efficient GPU. It may not simply be a generic GCN setup making it "efficient" like many have asserted. It sounds like the more meaningful efficiency gains may come instead (or rather, in addition to...) the way the content layers are being processed.
Someone can correct me here, but I think in the typical approach to tile-based rendering support, even for stuff like the PRT support in AMD's recent hardware, the method for processing the content involved the GPU waiting around for the full layer to be stored in memory before it processes it all at once. This leads to the GPU sitting there with nothing to do in this capacity in the meantime, no? As such your GPU efficiency is bound by latency somewhat.
In the manner employed by the patent there, instead of your GPU waiting until an entire layer full of tiles is ready it handles the processing on a per tile basis as those tiles are stored in memory. The result is your GPU processing is bound by the latency of the eSRAM, which reportedly is extremely low (which is a good thing). At least, that's what it sounds like to me.
The image planes seem to play a meaningful role in this process too, so I'll re-read that patent tomorrow maybe and see if it adds anything interesting.
Last edited by a moderator:
SenjutsuSage
Newcomer
And what is your source for this? MS's own patents are pretty explicitly suggesting otherwise and they explain a lot about the stuff we do know by the sound of it. Maybe the 'deferred' part is what's off? The patent below goes into detail about the procedure of rendering tile-based content and where this method's gains come from and it seems to mesh well with what ppl like Arthur on GAF had said months back. Additionally, the patent seems to directly allude to leaning on the eSRAM and display planes both for this methodology.
Here is the patent link for a new page...this link is a bit better actually since it has the diagrams:
http://www.faqs.org/patents/app/20130063473
I read through it and it sounds like there could be pretty considerable bandwidth and processing advantages rendering things on a tile depth basis as opposed to simply using tiles to construct layers, and then processing those layers in the GPU. This (new?) method could possibly explain why the eSRAM is targeted at such low latency and the murmurs from insiders of an exceptionally efficient GPU. It may not simply be a generic GCN setup making it "efficient" like many have asserted. It sounds like the more meaningful efficiency gains may come instead (or rather, in addition to...) the way the content layers are being processed.
Someone can correct me here, but I think in the typical approach to tile-based rendering support, even for stuff like the PRT support in AMD's recent hardware, the method for processing the content involved the GPU waiting around for the full layer to be stored in memory before it processes it all at once. This leads to the GPU sitting there with nothing to do in the meantime. As such your GPU efficiency is entirely latency-bound.
In the manner employed by the patent there, instead of your GPU waiting until an entire layer full of tiles is ready it handles the processing on a per tile basis as those tiles are stored in memory. The result is your GPU processing is bound by the latency of the eSRAM, which reportedly is extremely low (which is a good thing). At least, that's what it sounds like to me.
The image planes seem to play a meaningful role in this process too, so I'll re-read that patent tomorrow maybe and see if it adds anything interesting.
Who can know for sure, but I tend to agree that this makes the most sense. At least I think betting on this possibly being at least a fairly important part of their design calculations is a much safer bet than a surprise enhancement of the existing rumored specs. And plus it sounds damn interesting. I would really like to see a situation where they truly did have enough confidence in this idea of theirs to actually take it forward.
- Status
- Not open for further replies.
Similar threads
- Replies
- 50
- Views
- 9K
- Replies
- 5
- Views
- 3K
- Locked
- Replies
- 3K
- Views
- 312K
- Replies
- 494
- Views
- 38K