Bulldozer was pretty bad, but is there anything in Steamroller that strikes you as ill-suited to the needs of modern PCs?
In a vacuum, for the restricted subset of the Bulldozer core's target workloads, there's nothing that is unacceptable for most standard PCs. Steamrollers isn't targeting server that much, so a good chunk of Bulldozer's design choices like the hefty L1 become suspect (the limited associativity and aliasing issues of the L1 make it somewhat suspect for server).
In context, Trinity or Richland are equally acceptable, and an i3 or i5 equally acceptable or superior for roughly the same price or less while being more efficient and profitable.
Implementation changes to the processor broke socket backwards compatibility, so a significant swath of the market that thinks Steamroller-level performance is acceptable would not find Kaveri acceptable.
For gaming rigs, even with Mantle AMD's frame times are obviously more variable than an i5 on games like BF4 that have sized their CPU load to run acceptably with DX11. I don't trust a chip that is looking fit to flop over once games decide to do something with the CPU power freed up by Mantle besides nothing.
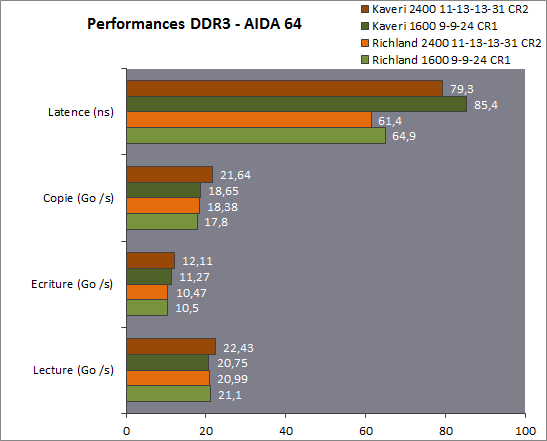
It seems like a fairly sound design to me. It's hard to make an accurate assessment of the core itself due to the fact that there's only one implementation of it so far, i.e. Kaveri, but given the latter's atrocious memory latency, I'm inclined to believe that Steamroller itself is a decent core.
Kaveri's biggest improvements are where it can reverse the CMT underpinnings of Bulldozer, and its weaknesses are where it cannot.
The cache subsystem is not that great, although it's not subject to some very bad corner cases like BD's very constrained write throughput or Trinity's unexplained terrible 256-bit load throughput.
The FPU was only ever competitive with Sandy Bridge when in an octo-core model, and with AVX2 the promotion of integer SIMD to full-width leaves that little sliver behind.
It's not as wide as Haswell and can't compete with it on a per thread basis, but that's not absolutely necessary to design good PC chips.
It competes with Nehalem, and cannot justify itself against its predecessors in the desktop.
It is currently a null offering for mobile. It's still a speed racer design with coarse module-level power gating.
Bulldozer-line cores still seem to have problems reaching the market, and they generally have plenty of not-so-good salvage bins.
That may come down to process problems, and Llano is a sign that the alternative was worse, but I think part of it is that Bulldozer cores at a fundamental level require circuit performance in a range that is outside the comfort zone of any process AMD will see for a very long time.
As for Carrizo's lowered TDP, that's only a potential issue for high-end desktop APUs, which aren't a very big part of AMD's business anyway. Besides, in practice 95W Kaveris seem to draw a good bit less, and aren't much faster than 65W ones, so it might not even be an issue at all.
The lack of performance scaling from the ostensible middle-range to high end of the design is a problem itself.
There are designs that do not have this problem, even from AMD itself.
AMD eked out better power efficiency at more modest clocks, and the 28nm process it uses purposefully sacrifices high-frequency scaling. The Steamroller pipeline is still a pipeline that was a disappointment when it could hit 4.2 GHz, much less one that turbos to ~3.
(correction: that is for one of the A8 SKUs, the A10 is up to 4)
I'm really not sure where AMD can go from there with Bulldozer.
Apple's A7 is able to get good performance for its niche because it doesn't pretend that it could someday scale to 4.5 to 5 Ghz.
On the other hand, I'm not sure what AMD can do to justify building a replacement with the same set of costly requirements and cross-purposes.
Its biggest growth areas are semicustom consoles, emerging market small systems, and maybe physicalized dense servers, markets that are cost-conscious and noteworthy for having lower standards in terms of engineering, performance, reliability, and validation.
")